 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradformer: Graph Transformer with Exponential Decay
Paper and Code
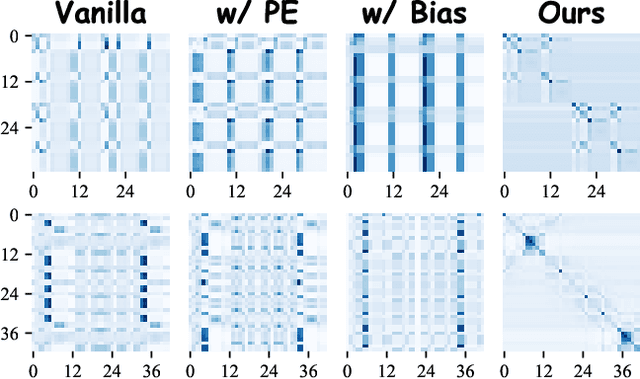
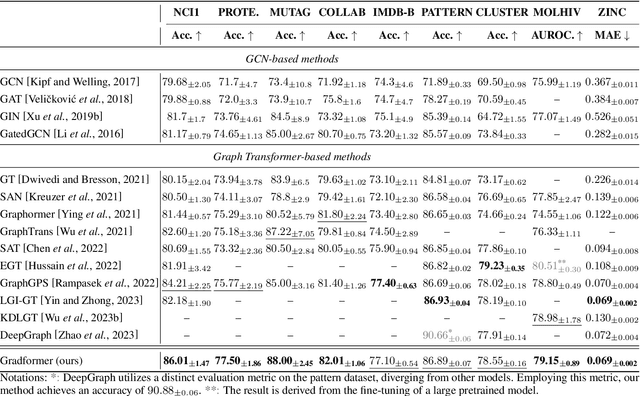
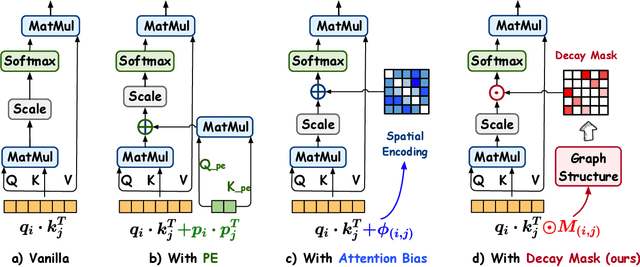
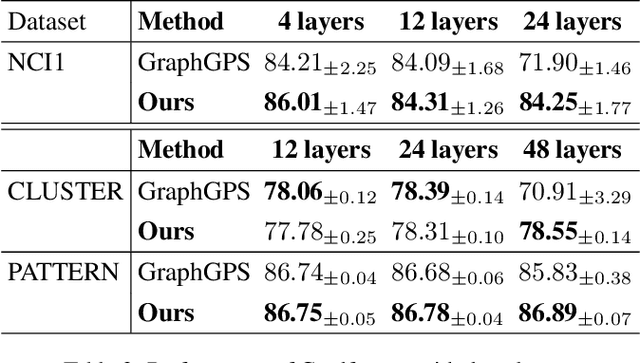
Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.