 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
IRCAN: Mitigating Knowledge Conflicts in LLM Generation via Identifying and Reweighting Context-Aware Neurons
Jun 26, 2024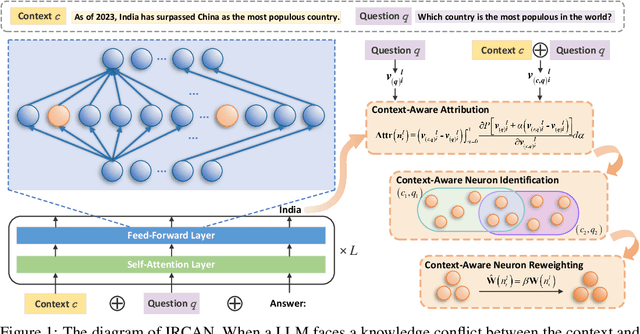
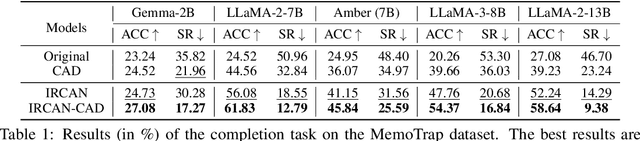
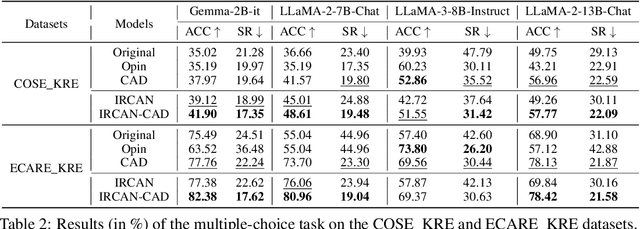
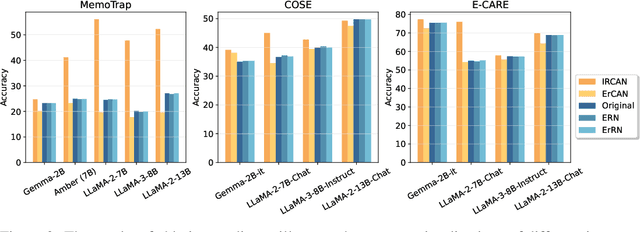
It is widely acknowledged that large language models (LLMs) encode a vast reservoir of knowledge after being trained on mass data. Recent studies disclose knowledge conflicts in LLM generation, wherein outdated or incorrect parametric knowledge (i.e., encoded knowledge) contradicts new knowledge provided in the context. To mitigate such knowledge conflicts, we propose a novel framework, IRCAN (Identifying and Reweighting Context-Aware Neurons) to capitalize on neurons that are crucial in processing contextual cues. Specifically, IRCAN first identifies neurons that significantly contribute to context processing, utilizing a context-aware attribution score derived from integrated gradients. Subsequently, the identified context-aware neurons are strengthened via reweighting. In doing so, we steer LLMs to generate context-sensitive outputs with respect to the new knowledge provided in the context. Extensive experiments conducted across a variety of models and tasks demonstrate that IRCAN not only achieves remarkable improvements in handling knowledge conflicts but also offers a scalable, plug-andplay solution that can be integrated seamlessly with existing models.
CORECODE: A Common Sense Annotated Dialogue Dataset with Benchmark Tasks for Chinese Large Language Models
Dec 20, 2023



As an indispensable ingredient of intelligence, commonsense reasoning is crucial for large language models (LLMs) in real-world scenarios. In this paper, we propose CORECODE, a dataset that contains abundant commonsense knowledge manually annotated on dyadic dialogues, to evaluate the commonsense reasoning and commonsense conflict detection capabilities of Chinese LLMs. We categorize commonsense knowledge in everyday conversations into three dimensions: entity, event, and social interaction. For easy and consistent annotation, we standardize the form of commonsense knowledge annotation in open-domain dialogues as "domain: slot = value". A total of 9 domains and 37 slots are defined to capture diverse commonsense knowledge. With these pre-defined domains and slots, we collect 76,787 commonsense knowledge annotations from 19,700 dialogues through crowdsourcing. To evaluate and enhance the commonsense reasoning capability for LLMs on the curated dataset, we establish a series of dialogue-level reasoning and detection tasks, including commonsense knowledge filling, commonsense knowledge generation, commonsense conflict phrase detection, domain identification, slot identification, and event causal inference. A wide variety of existing open-source Chinese LLMs are evaluated with these tasks on our dataset. Experimental results demonstrate that these models are not competent to predict CORECODE's plentiful reasoning content, and even ChatGPT could only achieve 0.275 and 0.084 accuracy on the domain identification and slot identification tasks under the zero-shot setting. We release the data and codes of CORECODE at https://github.com/danshi777/CORECODE to promote commonsense reasoning evaluation and study of LLMs in the context of daily conversations.
Evaluating Large Language Models: A Comprehensive Survey
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.