 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Multilingual Large Language Models: A Systematic Survey
Nov 19, 2024This paper provides a comprehensive survey of the latest research on multilingual large language models (MLLMs). MLLMs not only are able to understand and generate language across linguistic boundaries, but also represent an important advancement in artificial intelligence. We first discuss the architecture and pre-training objectives of MLLMs, highlighting the key components and methodologies that contribute to their multilingual capabilities. We then discuss the construction of multilingual pre-training and alignment datasets, underscoring the importance of data quality and diversity in enhancing MLLM performance. An important focus of this survey is on the evaluation of MLLMs. We present a detailed taxonomy and roadmap covering the assessment of MLLMs' cross-lingual knowledge, reasoning, alignment with human values, safety, interpretability and specialized applications. Specifically, we extensively discuss multilingual evaluation benchmarks and datasets, and explore the use of LLMs themselves as multilingual evaluators. To enhance MLLMs from black to white boxes, we also address the interpretability of multilingual capabilities, cross-lingual transfer and language bias within these models. Finally, we provide a comprehensive review of real-world applications of MLLMs across diverse domains, including biology, medicine, computer science, mathematics and law. We showcase how these models have driven innovation and improvements in these specialized fields while also highlighting the challenges and opportunities in deploying MLLMs within diverse language communities and application scenarios. We listed the paper related in this survey and publicly available at https://github.com/tjunlp-lab/Awesome-Multilingual-LLMs-Papers.
FuxiTranyu: A Multilingual Large Language Model Trained with Balanced Data
Aug 13, 2024
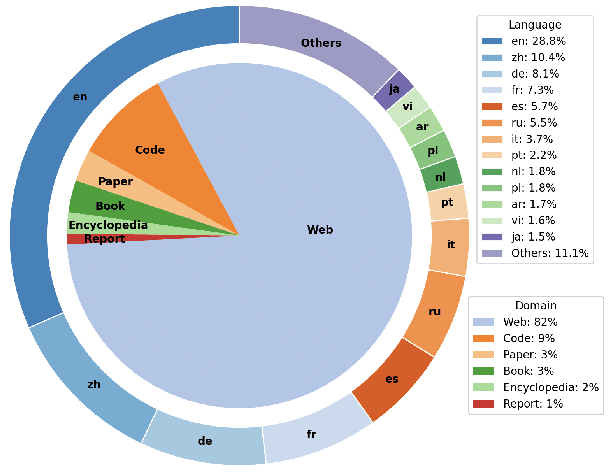
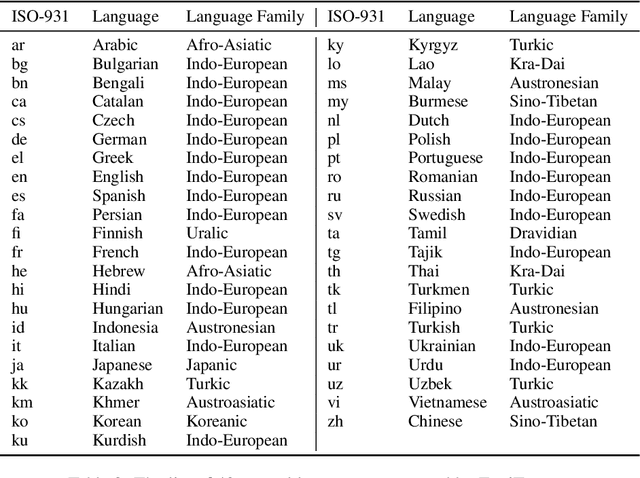
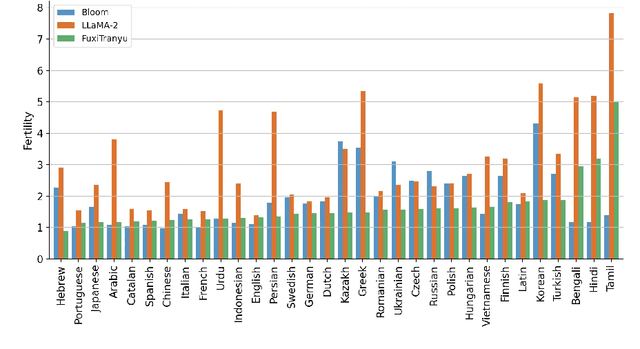
Large language models (LLMs) have demonstrated prowess in a wide range of tasks. However, many LLMs exhibit significant performance discrepancies between high- and low-resource languages. To mitigate this challenge, we present FuxiTranyu, an open-source multilingual LLM, which is designed to satisfy the need of the research community for balanced and high-performing multilingual capabilities. FuxiTranyu-8B, the base model with 8 billion parameters, is trained from scratch on a meticulously balanced multilingual data repository that contains 600 billion tokens covering 43 natural languages and 16 programming languages. In addition to the base model, we also develop two instruction-tuned models: FuxiTranyu-8B-SFT that is fine-tuned on a diverse multilingual instruction dataset, and FuxiTranyu-8B-DPO that is further refined with DPO on a preference dataset for enhanced alignment ability. Extensive experiments on a wide range of multilingual benchmarks demonstrate the competitive performance of FuxiTranyu against existing multilingual LLMs, e.g., BLOOM-7B, PolyLM-13B, Llama-2-Chat-7B and Mistral-7B-Instruct. Interpretability analyses at both the neuron and representation level suggest that FuxiTranyu is able to learn consistent multilingual representations across different languages. To promote further research into multilingual LLMs and their working mechanisms, we release both the base and instruction-tuned FuxiTranyu models together with 58 pretraining checkpoints at HuggingFace and Github.
Evaluating Large Language Models: A Comprehensive Survey
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.
Is Robustness Transferable across Languages in Multilingual Neural Machine Translation?
Oct 31, 2023Robustness, the ability of models to maintain performance in the face of perturbations, is critical for developing reliable NLP systems. Recent studies have shown promising results in improving the robustness of models through adversarial training and data augmentation. However, in machine translation, most of these studies have focused on bilingual machine translation with a single translation direction. In this paper, we investigate the transferability of robustness across different languages in multilingual neural machine translation. We propose a robustness transfer analysis protocol and conduct a series of experiments. In particular, we use character-, word-, and multi-level noises to attack the specific translation direction of the multilingual neural machine translation model and evaluate the robustness of other translation directions. Our findings demonstrate that the robustness gained in one translation direction can indeed transfer to other translation directions. Additionally, we empirically find scenarios where robustness to character-level noise and word-level noise is more likely to transfer.