 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Machine Translation with Open Large Language Models at Practical Scale: An Empirical Study
Feb 04, 2025Large language models (LLMs) have shown continuously improving multilingual capabilities, and even small-scale open-source models have demonstrated rapid performance enhancement. In this paper, we systematically explore the abilities of open LLMs with less than ten billion parameters to handle multilingual machine translation (MT) tasks. We conduct comprehensive evaluations on six popular LLMs and find that models like Gemma2-9B exhibit impressive multilingual translation capabilities. We then introduce the Parallel-First Monolingual-Second (PFMS) data mixing strategy in the continual pretraining stage to further enhance the MT performance and present GemmaX2-28, a 9B model achieving top-tier multilingual translation performance across 28 languages. Specifically, GemmaX2-28 consistently outperforms the state-of-the-art (SOTA) models such as TowerInstruct and XALMA and achieves competitive performance with Google Translate and GPT-4-turbo.
Multilingual Large Language Models: A Systematic Survey
Nov 19, 2024This paper provides a comprehensive survey of the latest research on multilingual large language models (MLLMs). MLLMs not only are able to understand and generate language across linguistic boundaries, but also represent an important advancement in artificial intelligence. We first discuss the architecture and pre-training objectives of MLLMs, highlighting the key components and methodologies that contribute to their multilingual capabilities. We then discuss the construction of multilingual pre-training and alignment datasets, underscoring the importance of data quality and diversity in enhancing MLLM performance. An important focus of this survey is on the evaluation of MLLMs. We present a detailed taxonomy and roadmap covering the assessment of MLLMs' cross-lingual knowledge, reasoning, alignment with human values, safety, interpretability and specialized applications. Specifically, we extensively discuss multilingual evaluation benchmarks and datasets, and explore the use of LLMs themselves as multilingual evaluators. To enhance MLLMs from black to white boxes, we also address the interpretability of multilingual capabilities, cross-lingual transfer and language bias within these models. Finally, we provide a comprehensive review of real-world applications of MLLMs across diverse domains, including biology, medicine, computer science, mathematics and law. We showcase how these models have driven innovation and improvements in these specialized fields while also highlighting the challenges and opportunities in deploying MLLMs within diverse language communities and application scenarios. We listed the paper related in this survey and publicly available at https://github.com/tjunlp-lab/Awesome-Multilingual-LLMs-Papers.
FuxiTranyu: A Multilingual Large Language Model Trained with Balanced Data
Aug 13, 2024
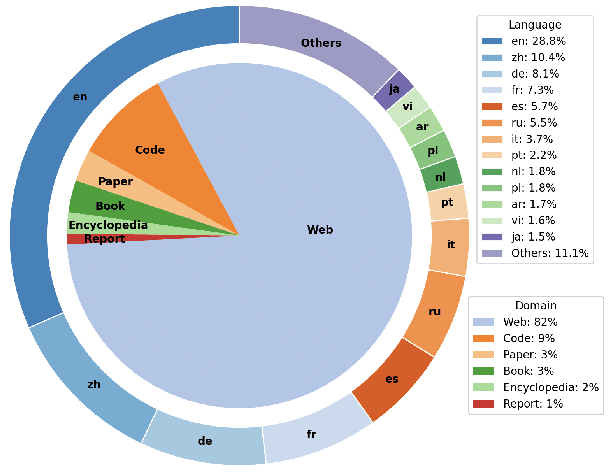
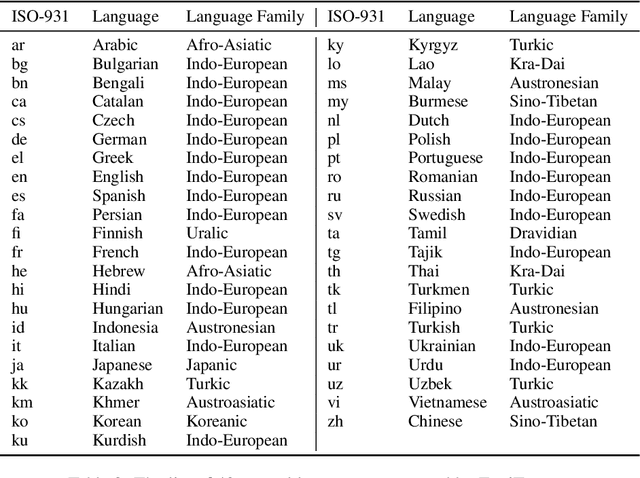
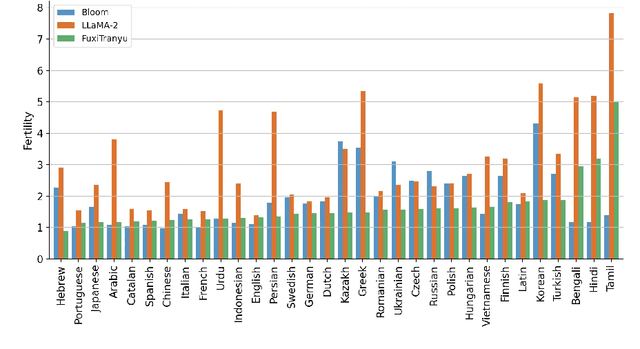
Large language models (LLMs) have demonstrated prowess in a wide range of tasks. However, many LLMs exhibit significant performance discrepancies between high- and low-resource languages. To mitigate this challenge, we present FuxiTranyu, an open-source multilingual LLM, which is designed to satisfy the need of the research community for balanced and high-performing multilingual capabilities. FuxiTranyu-8B, the base model with 8 billion parameters, is trained from scratch on a meticulously balanced multilingual data repository that contains 600 billion tokens covering 43 natural languages and 16 programming languages. In addition to the base model, we also develop two instruction-tuned models: FuxiTranyu-8B-SFT that is fine-tuned on a diverse multilingual instruction dataset, and FuxiTranyu-8B-DPO that is further refined with DPO on a preference dataset for enhanced alignment ability. Extensive experiments on a wide range of multilingual benchmarks demonstrate the competitive performance of FuxiTranyu against existing multilingual LLMs, e.g., BLOOM-7B, PolyLM-13B, Llama-2-Chat-7B and Mistral-7B-Instruct. Interpretability analyses at both the neuron and representation level suggest that FuxiTranyu is able to learn consistent multilingual representations across different languages. To promote further research into multilingual LLMs and their working mechanisms, we release both the base and instruction-tuned FuxiTranyu models together with 58 pretraining checkpoints at HuggingFace and Github.
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Jun 11, 2024Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.