 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExPosST: Explicit Positioning with Adaptive Masking for LLM-Based Simultaneous Machine Translation
Mar 16, 2026Large language models (LLMs) have recently demonstrated promising performance in simultaneous machine translation (SimulMT). However, applying decoder-only LLMs to SimulMT introduces a positional mismatch, which leads to a dilemma between decoding efficiency and positional consistency. Existing approaches often rely on specific positional encodings or carefully designed prompting schemes, and thus fail to simultaneously achieve inference efficiency, positional consistency, and broad model compatibility. In this work, we propose ExPosST, a general framework that resolves this dilemma through explicit position allocation. ExPosST reserves fixed positional slots for incoming source tokens, enabling efficient decoding with KV cache across different positional encoding methods. To further bridge the gap between fine-tuning and inference, we introduce a policy-consistent fine-tuning strategy that aligns training with inference-time decoding behavior. Experiments across multiple language pairs demonstrate that ExPosST effectively supports simultaneous translation under diverse policies.
CoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
Feb 27, 2026Mobile Agents can autonomously execute user instructions, which requires hybrid-capabilities reasoning, including screen summary, subtask planning, action decision and action function. However, existing agents struggle to achieve both decoupled enhancement and balanced integration of these capabilities. To address these challenges, we propose Channel-of-Mobile-Experts (CoME), a novel agent architecture consisting of four distinct experts, each aligned with a specific reasoning stage, CoME activates the corresponding expert to generate output tokens in each reasoning stage via output-oriented activation. To empower CoME with hybrid-capabilities reasoning, we introduce a progressive training strategy: Expert-FT enables decoupling and enhancement of different experts' capability; Router-FT aligns expert activation with the different reasoning stage; CoT-FT facilitates seamless collaboration and balanced optimization across multiple capabilities. To mitigate error propagation in hybrid-capabilities reasoning, we propose InfoGain-Driven DPO (Info-DPO), which uses information gain to evaluate the contribution of each intermediate step, thereby guiding CoME toward more informative reasoning. Comprehensive experiments show that CoME outperforms dense mobile agents and MoE methods on both AITZ and AMEX datasets.
Scaling Model and Data for Multilingual Machine Translation with Open Large Language Models
Feb 12, 2026Open large language models (LLMs) have demonstrated improving multilingual capabilities in recent years. In this paper, we present a study of open LLMs for multilingual machine translation (MT) across a range of languages, and investigate the effects of model scaling and data scaling when adapting open LLMs to multilingual MT through continual pretraining and instruction finetuning. Based on the Gemma3 model family, we develop MiLMMT-46, which achieves top-tier multilingual translation performance across 46 languages. Extensive experiments show that MiLMMT-46 consistently outperforms recent state-of-the-art (SOTA) models, including Seed-X, HY-MT-1.5, and TranslateGemma, and achieves competitive performance with strong proprietary systems such as Google Translate and Gemini 3 Pro.
MobileBench-OL: A Comprehensive Chinese Benchmark for Evaluating Mobile GUI Agents in Real-World Environment
Jan 29, 2026Recent advances in mobile Graphical User Interface (GUI) agents highlight the growing need for comprehensive evaluation benchmarks. While new online benchmarks offer more realistic testing than offline ones, they tend to focus on the agents' task instruction-following ability while neglecting their reasoning and exploration ability. Moreover, these benchmarks do not consider the random noise in real-world mobile environments. This leads to a gap between benchmarks and real-world environments. To addressing these limitations, we propose MobileBench-OL, an online benchmark with 1080 tasks from 80 Chinese apps. It measures task execution, complex reasoning, and noise robustness of agents by including 5 subsets, which set multiple evaluation dimensions. We also provide an auto-eval framework with a reset mechanism, enabling stable and repeatable real-world benchmarking. Evaluating 12 leading GUI agents on MobileBench-OL shows significant room for improvement to meet real-world requirements. Human evaluation further confirms that MobileBench-OL can reliably measure the performance of leading GUI agents in real environments. Our data and code will be released upon acceptance.
STEP: Success-Rate-Aware Trajectory-Efficient Policy Optimization
Nov 17, 2025Multi-turn interaction remains challenging for online reinforcement learning. A common solution is trajectory-level optimization, which treats each trajectory as a single training sample. However, this approach can be inefficient and yield misleading learning signals: it applies uniform sampling across tasks regardless of difficulty, penalizes correct intermediate actions in failed trajectories, and incurs high sample-collection costs. To address these issues, we propose STEP (Success-rate-aware Trajectory-Efficient Policy optimization), a framework that dynamically allocates sampling based on per-task success rates and performs step-level optimization. STEP maintains a smoothed success-rate record to guide adaptive trajectory resampling, allocating more effort to harder tasks. It then computes success-rate-weighted advantages and decomposes trajectories into step-level samples. Finally, it applies a step-level GRPO augmentation to refine updates for low-success tasks. Experiments on OSWorld and AndroidWorld show that STEP substantially improves sample efficiency and training stability over trajectory-level GRPO, converging faster and generalizing better under the same sampling budget.
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
BacktrackAgent: Enhancing GUI Agent with Error Detection and Backtracking Mechanism
May 27, 2025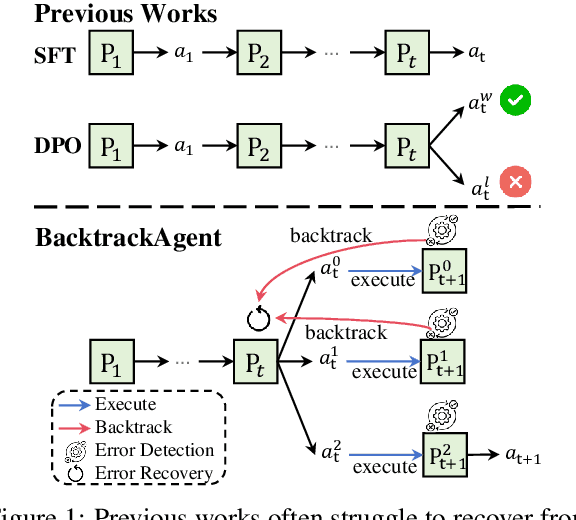
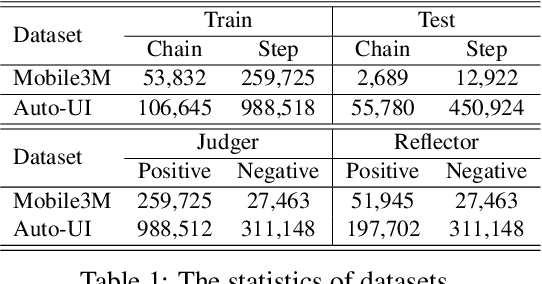
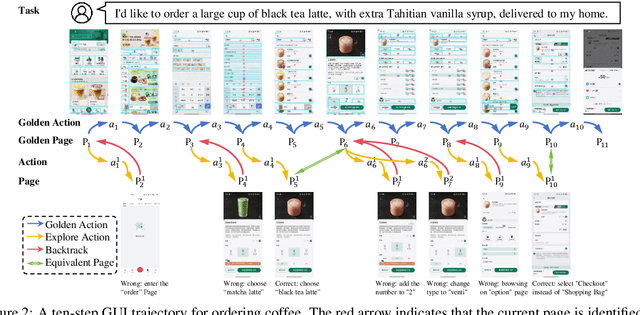
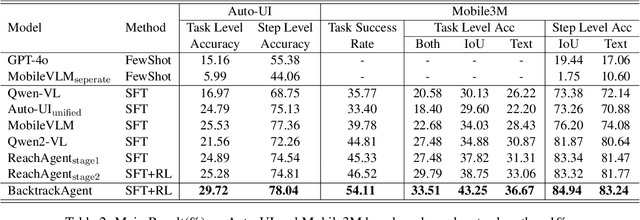
Graphical User Interface (GUI) agents have gained substantial attention due to their impressive capabilities to complete tasks through multiple interactions within GUI environments. However, existing agents primarily focus on enhancing the accuracy of individual actions and often lack effective mechanisms for detecting and recovering from errors. To address these shortcomings, we propose the BacktrackAgent, a robust framework that incorporates a backtracking mechanism to improve task completion efficiency. BacktrackAgent includes verifier, judger, and reflector components as modules for error detection and recovery, while also applying judgment rewards to further enhance the agent's performance. Additionally, we develop a training dataset specifically designed for the backtracking mechanism, which considers the outcome pages after action executions. Experimental results show that BacktrackAgent has achieved performance improvements in both task success rate and step accuracy on Mobile3M and Auto-UI benchmarks. Our data and code will be released upon acceptance.
Enhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025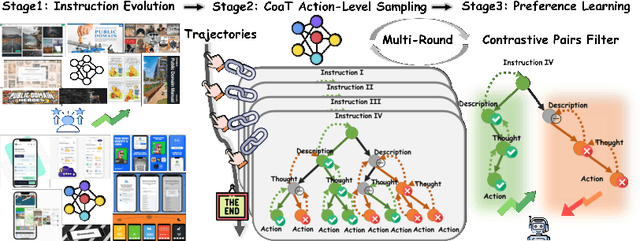
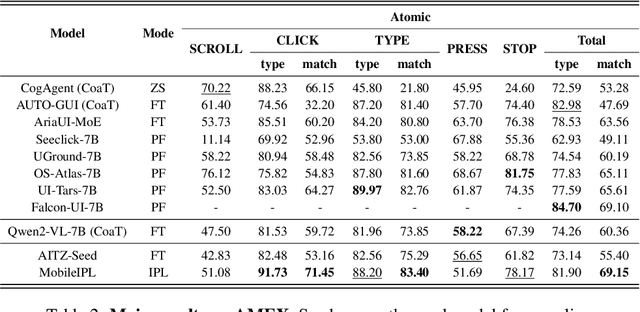
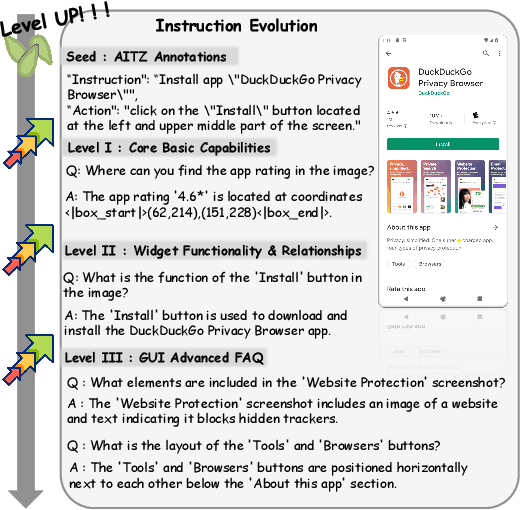
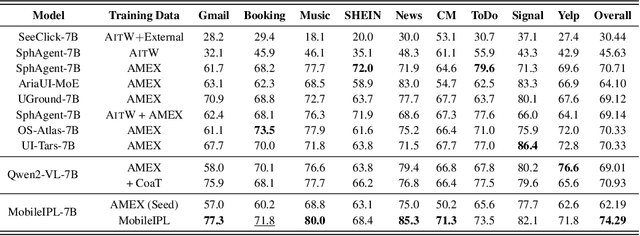
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
Multilingual Machine Translation with Open Large Language Models at Practical Scale: An Empirical Study
Feb 04, 2025Large language models (LLMs) have shown continuously improving multilingual capabilities, and even small-scale open-source models have demonstrated rapid performance enhancement. In this paper, we systematically explore the abilities of open LLMs with less than ten billion parameters to handle multilingual machine translation (MT) tasks. We conduct comprehensive evaluations on six popular LLMs and find that models like Gemma2-9B exhibit impressive multilingual translation capabilities. We then introduce the Parallel-First Monolingual-Second (PFMS) data mixing strategy in the continual pretraining stage to further enhance the MT performance and present GemmaX2-28, a 9B model achieving top-tier multilingual translation performance across 28 languages. Specifically, GemmaX2-28 consistently outperforms the state-of-the-art (SOTA) models such as TowerInstruct and XALMA and achieves competitive performance with Google Translate and GPT-4-turbo.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024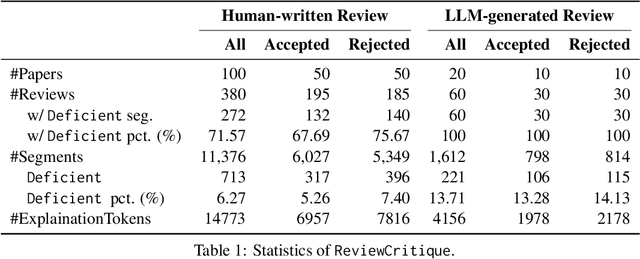
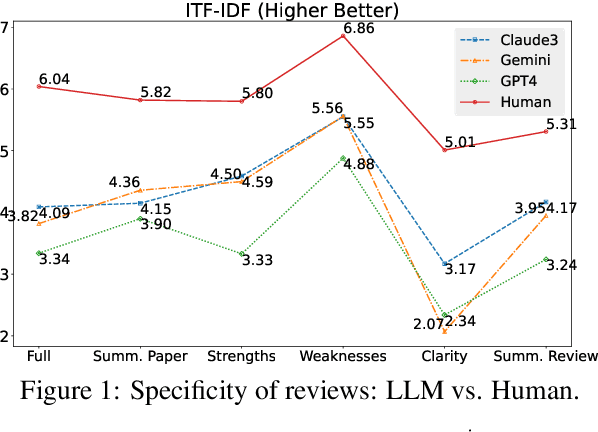

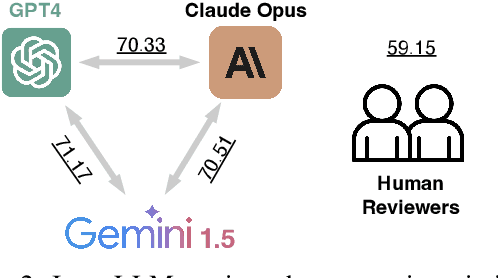
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.