 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVerRL: Breaking the Consensus Trap in Label-Free Reasoning via Generator-Verifier Co-Evolution
Mar 18, 2026Label-free reinforcement learning enables large language models to improve reasoning capabilities without ground-truth supervision, typically by treating majority-voted answers as pseudo-labels. However, we identify a critical failure mode: as training maximizes self-consistency, output diversity collapses, causing the model to confidently reinforce systematic errors that evade detection. We term this the consensus trap. To escape it, we propose CoVerRL, a framework where a single model alternates between generator and verifier roles, with each capability bootstrapping the other. Majority voting provides noisy but informative supervision for training the verifier, while the improving verifier progressively filters self-consistent errors from pseudo-labels. This co-evolution creates a virtuous cycle that maintains high reward accuracy throughout training. Experiments across Qwen and Llama model families demonstrate that CoVerRL outperforms label-free baselines by 4.7-5.9\% on mathematical reasoning benchmarks. Moreover, self-verification accuracy improves from around 55\% to over 85\%, confirming that both capabilities genuinely co-evolve.
Deep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
Feb 15, 2026Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
An Empirical Study of Consistency Regularization for End-to-End Speech-to-Text Translation
Aug 28, 2023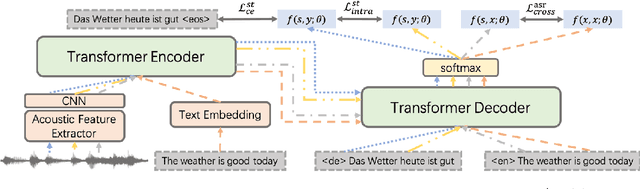
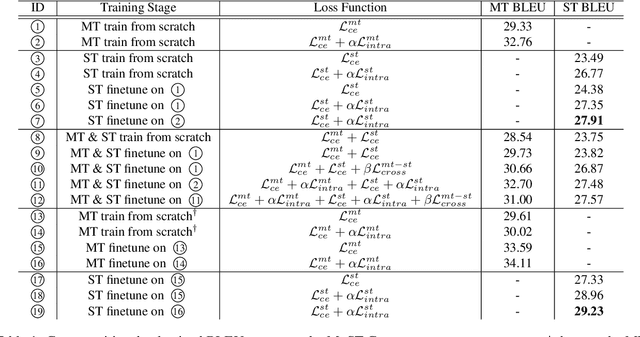
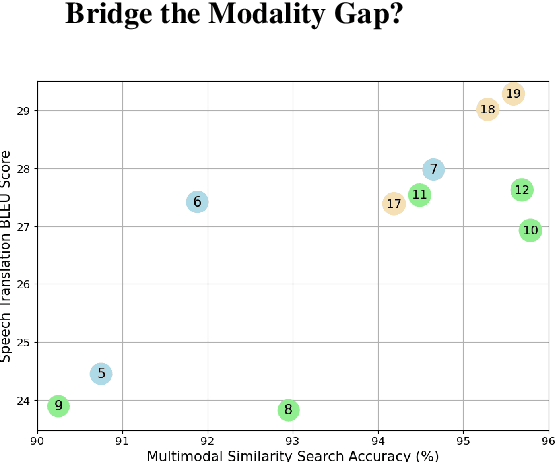
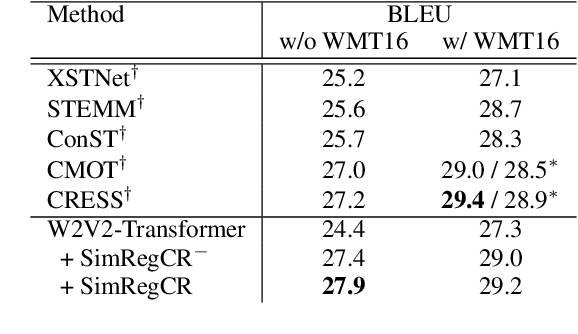
Consistency regularization methods, such as R-Drop (Liang et al., 2021) and CrossConST (Gao et al., 2023), have achieved impressive supervised and zero-shot performance in the neural machine translation (NMT) field. Can we also boost end-to-end (E2E) speech-to-text translation (ST) by leveraging consistency regularization? In this paper, we conduct empirical studies on intra-modal and cross-modal consistency and propose two training strategies, SimRegCR and SimZeroCR, for E2E ST in regular and zero-shot scenarios. Experiments on the MuST-C benchmark show that our approaches achieve state-of-the-art (SOTA) performance in most translation directions. The analyses prove that regularization brought by the intra-modal consistency, instead of modality gap, is crucial for the regular E2E ST, and the cross-modal consistency could close the modality gap and boost the zero-shot E2E ST performance.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021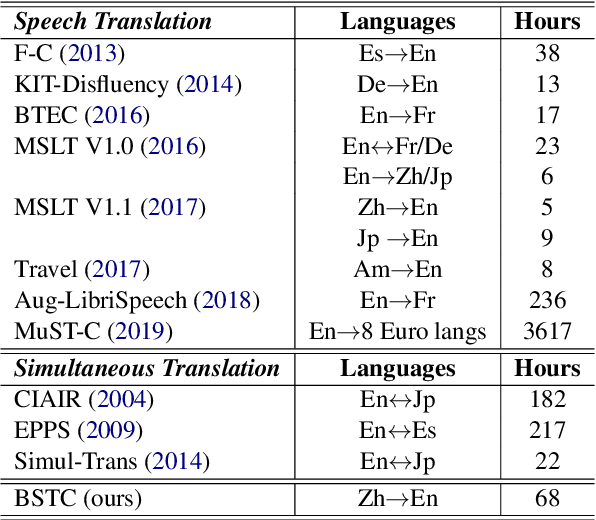
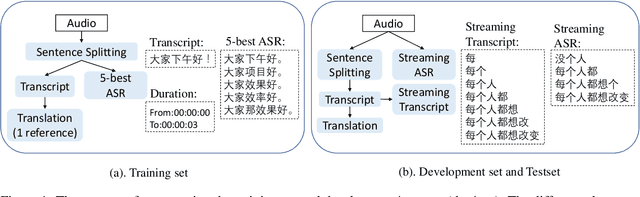

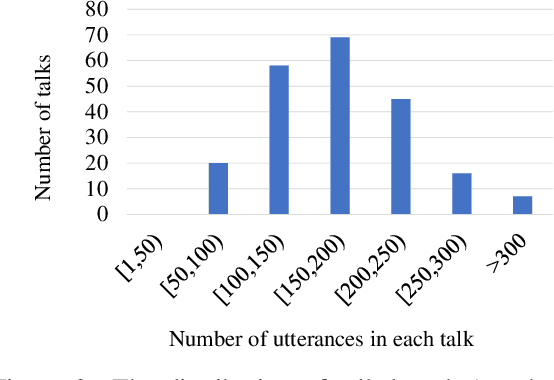
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
DuTongChuan: Context-aware Translation Model for Simultaneous Interpreting
Aug 16, 2019


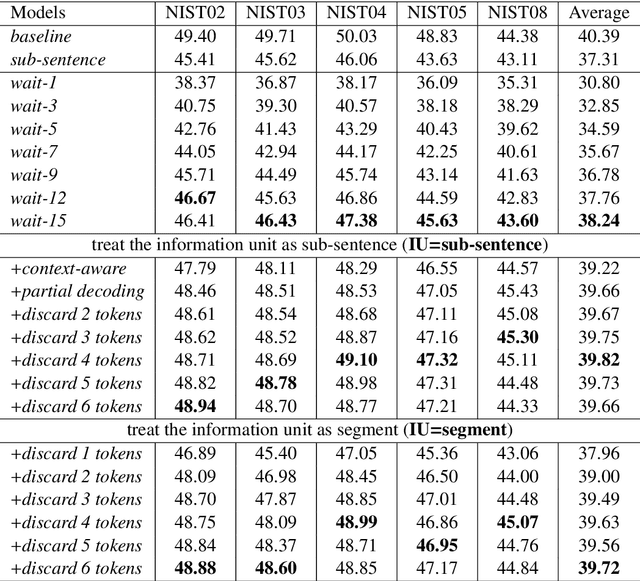
In this paper, we present DuTongChuan, a novel context-aware translation model for simultaneous interpreting. This model allows to constantly read streaming text from the Automatic Speech Recognition (ASR) model and simultaneously determine the boundaries of Information Units (IUs) one after another. The detected IU is then translated into a fluent translation with two simple yet effective decoding strategies: partial decoding and context-aware decoding. In practice, by controlling the granularity of IUs and the size of the context, we can get a good trade-off between latency and translation quality easily. Elaborate evaluation from human translators reveals that our system achieves promising translation quality (85.71% for Chinese-English, and 86.36% for English-Chinese), specially in the sense of surprisingly good discourse coherence. According to an End-to-End (speech-to-speech simultaneous interpreting) evaluation, this model presents impressive performance in reducing latency (to less than 3 seconds at most times). Furthermore, we successfully deploy this model in a variety of Baidu's products which have hundreds of millions of users, and we release it as a service in our AI platform.
DeepTransport: Learning Spatial-Temporal Dependency for Traffic Condition Forecasting
Sep 27, 2017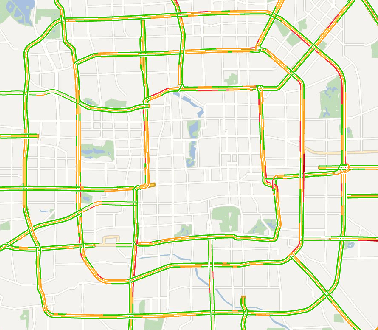
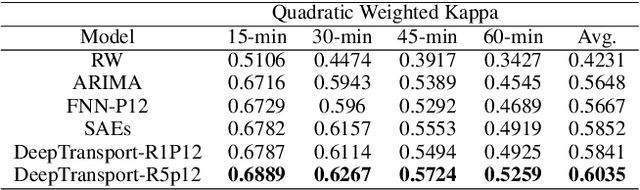
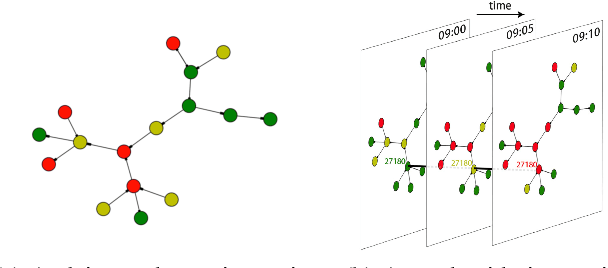
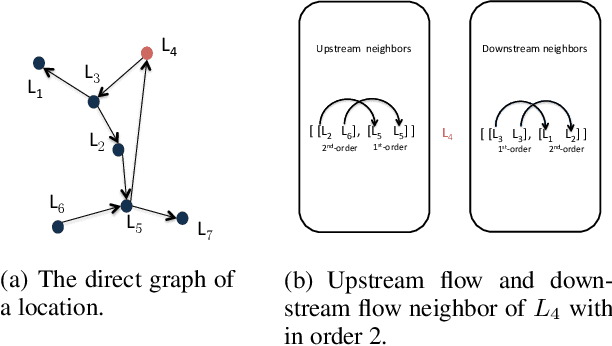
Predicting traffic conditions has been recently explored as a way to relieve traffic congestion. Several pioneering approaches have been proposed based on traffic observations of the target location as well as its adjacent regions, but they obtain somewhat limited accuracy due to lack of mining road topology. To address the effect attenuation problem, we propose to take account of the traffic of surrounding locations(wider than adjacent range). We propose an end-to-end framework called DeepTransport, in which Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) are utilized to obtain spatial-temporal traffic information within a transport network topology. In addition, attention mechanism is introduced to align spatial and temporal information. Moreover, we constructed and released a real-world large traffic condition dataset with 5-minute resolution. Our experiments on this dataset demonstrate our method captures the complex relationship in temporal and spatial domain. It significantly outperforms traditional statistical methods and a state-of-the-art deep learning method.