 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Consistency Regularization for End-to-End Speech-to-Text Translation
Paper and Code
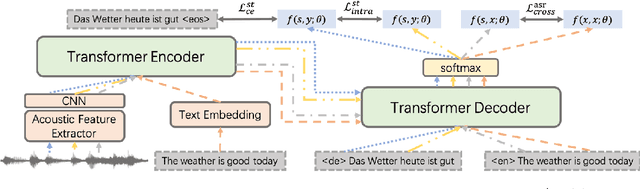
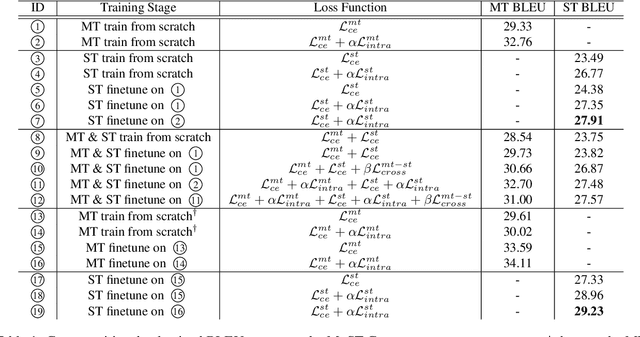
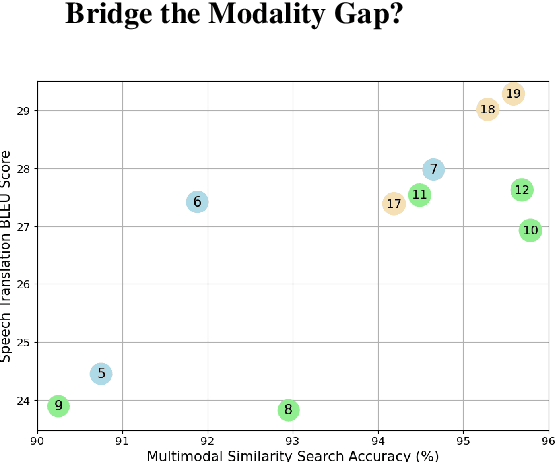
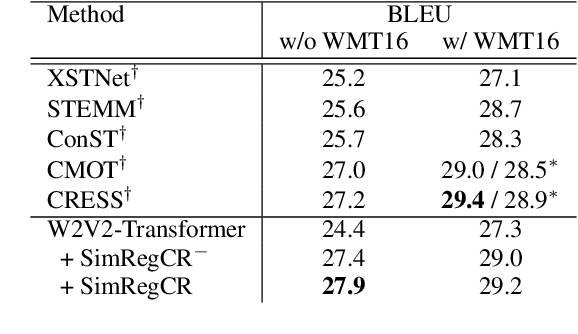
Consistency regularization methods, such as R-Drop (Liang et al., 2021) and CrossConST (Gao et al., 2023), have achieved impressive supervised and zero-shot performance in the neural machine translation (NMT) field. Can we also boost end-to-end (E2E) speech-to-text translation (ST) by leveraging consistency regularization? In this paper, we conduct empirical studies on intra-modal and cross-modal consistency and propose two training strategies, SimRegCR and SimZeroCR, for E2E ST in regular and zero-shot scenarios. Experiments on the MuST-C benchmark show that our approaches achieve state-of-the-art (SOTA) performance in most translation directions. The analyses prove that regularization brought by the intra-modal consistency, instead of modality gap, is crucial for the regular E2E ST, and the cross-modal consistency could close the modality gap and boost the zero-shot E2E ST performance.