 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Multipath Component-Enhanced Signal Processing for Integrated Sensing and Communication Systems
Jun 09, 2025Integrated sensing and communication (ISAC) has gained traction in academia and industry. Recently, multipath components (MPCs), as a type of spatial resource, have the potential to improve the sensing performance in ISAC systems, especially in richly scattering environments. In this paper, we propose to leverage MPC and Khatri-Rao space-time (KRST) code within a single ISAC system to realize high-accuracy sensing for multiple dynamic targets and multi-user communication. Specifically, we propose a novel MPC-enhanced sensing processing scheme with symbol-level fusion, referred to as the "SL-MPS" scheme, to achieve high-accuracy localization of multiple dynamic targets and empower the single ISAC system with a new capability of absolute velocity estimation for multiple targets with a single sensing attempt. Furthermore, the KRST code is applied to flexibly balance communication and sensing performance in richly scattering environments. To evaluate the contribution of MPCs, the closed-form Cram\'er-Rao lower bounds (CRLBs) of location and absolute velocity estimation are derived. Simulation results illustrate that the proposed SL-MPS scheme is more robust and accurate in localization and absolute velocity estimation compared with the existing state-of-the-art schemes.
Autoregressive Meta-Actions for Unified Controllable Trajectory Generation
May 29, 2025



Controllable trajectory generation guided by high-level semantic decisions, termed meta-actions, is crucial for autonomous driving systems. A significant limitation of existing frameworks is their reliance on invariant meta-actions assigned over fixed future time intervals, causing temporal misalignment with the actual behavior trajectories. This misalignment leads to irrelevant associations between the prescribed meta-actions and the resulting trajectories, disrupting task coherence and limiting model performance. To address this challenge, we introduce Autoregressive Meta-Actions, an approach integrated into autoregressive trajectory generation frameworks that provides a unified and precise definition for meta-action-conditioned trajectory prediction. Specifically, We decompose traditional long-interval meta-actions into frame-level meta-actions, enabling a sequential interplay between autoregressive meta-action prediction and meta-action-conditioned trajectory generation. This decomposition ensures strict alignment between each trajectory segment and its corresponding meta-action, achieving a consistent and unified task formulation across the entire trajectory span and significantly reducing complexity. Moreover, we propose a staged pre-training process to decouple the learning of basic motion dynamics from the integration of high-level decision control, which offers flexibility, stability, and modularity. Experimental results validate our framework's effectiveness, demonstrating improved trajectory adaptivity and responsiveness to dynamic decision-making scenarios. We provide the video document and dataset, which are available at https://arma-traj.github.io/.
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Mar 19, 2025Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE's 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE's correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE's good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
Multipath Component-Aided Signal Processing for Integrated Sensing and Communication Systems
Dec 31, 2024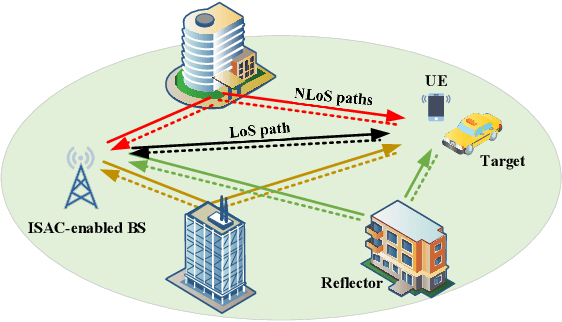
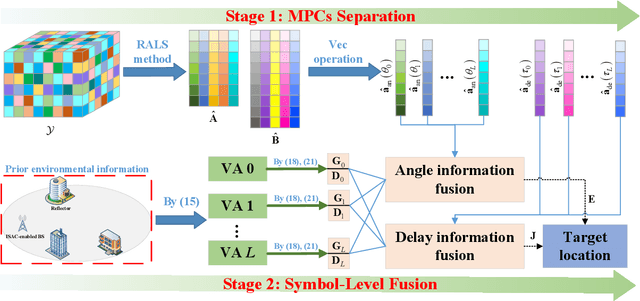
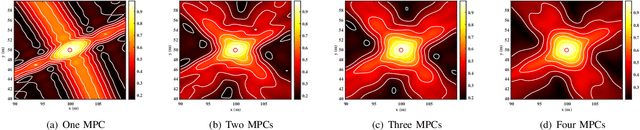
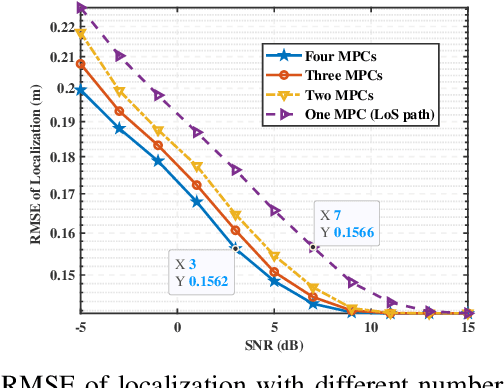
Integrated sensing and communication (ISAC) has emerged as a pivotal enabling technology for sixth-generation (6G) mobile communication system. The ISAC research in dense urban areas has been plaguing by severe multipath interference, propelling the thorough research of ISAC multipath interference elimination. However, transforming the multipath component (MPC) from enemy into friend is a viable and mutually beneficial option. In this paper, we preliminarily explore the MPC-aided ISAC signal processing and apply a space-time code to improve the ISAC performance. Specifically, we propose a symbol-level fusion for MPC-aided localization (SFMC) scheme to achieve robust and high-accuracy localization, and apply a Khatri-Rao space-time (KRST) code to improve the communication and sensing performance in rich multipath environment. Simulation results demonstrate that the proposed SFMC scheme has more robust localization performance with higher accuracy, compared with the existing state-of-the-art schemes. The proposed SFMC would benefit highly reliable communication and sub-meter level localization in rich multipath scenarios.
StreamMOTP: Streaming and Unified Framework for Joint 3D Multi-Object Tracking and Trajectory Prediction
Jun 28, 20243D multi-object tracking and trajectory prediction are two crucial modules in autonomous driving systems. Generally, the two tasks are handled separately in traditional paradigms and a few methods have started to explore modeling these two tasks in a joint manner recently. However, these approaches suffer from the limitations of single-frame training and inconsistent coordinate representations between tracking and prediction tasks. In this paper, we propose a streaming and unified framework for joint 3D Multi-Object Tracking and trajectory Prediction (StreamMOTP) to address the above challenges. Firstly, we construct the model in a streaming manner and exploit a memory bank to preserve and leverage the long-term latent features for tracked objects more effectively. Secondly, a relative spatio-temporal positional encoding strategy is introduced to bridge the gap of coordinate representations between the two tasks and maintain the pose-invariance for trajectory prediction. Thirdly, we further improve the quality and consistency of predicted trajectories with a dual-stream predictor. We conduct extensive experiments on popular nuSences dataset and the experimental results demonstrate the effectiveness and superiority of StreamMOTP, which outperforms previous methods significantly on both tasks. Furthermore, we also prove that the proposed framework has great potential and advantages in actual applications of autonomous driving.
Localization-Guided Track: A Deep Association Multi-Object Tracking Framework Based on Localization Confidence of Detections
Sep 18, 2023



In currently available literature, no tracking-by-detection (TBD) paradigm-based tracking method has considered the localization confidence of detection boxes. In most TBD-based methods, it is considered that objects of low detection confidence are highly occluded and thus it is a normal practice to directly disregard such objects or to reduce their priority in matching. In addition, appearance similarity is not a factor to consider for matching these objects. However, in terms of the detection confidence fusing classification and localization, objects of low detection confidence may have inaccurate localization but clear appearance; similarly, objects of high detection confidence may have inaccurate localization or unclear appearance; yet these objects are not further classified. In view of these issues, we propose Localization-Guided Track (LG-Track). Firstly, localization confidence is applied in MOT for the first time, with appearance clarity and localization accuracy of detection boxes taken into account, and an effective deep association mechanism is designed; secondly, based on the classification confidence and localization confidence, a more appropriate cost matrix can be selected and used; finally, extensive experiments have been conducted on MOT17 and MOT20 datasets. The results show that our proposed method outperforms the compared state-of-art tracking methods. For the benefit of the community, our code has been made publicly at https://github.com/mengting2023/LG-Track.
You Only Need Two Detectors to Achieve Multi-Modal 3D Multi-Object Tracking
Apr 18, 2023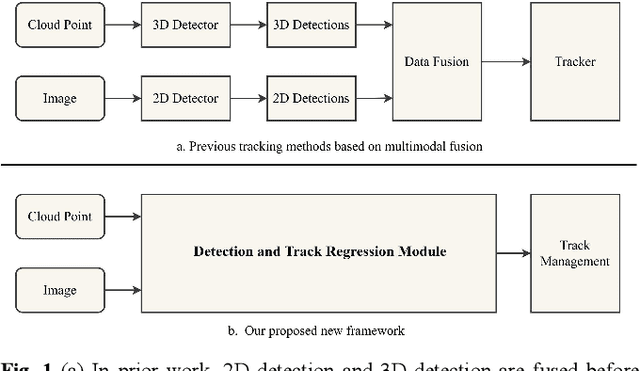
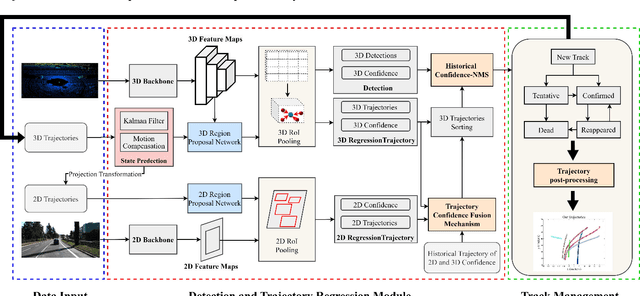

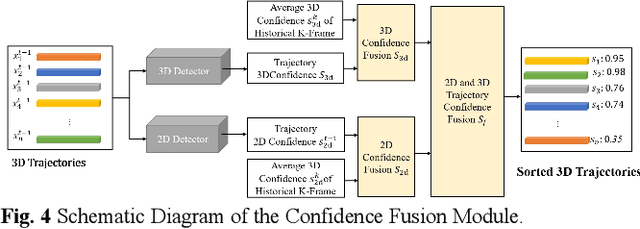
Firstly, a new multi-object tracking framework is proposed in this paper based on multi-modal fusion. By integrating object detection and multi-object tracking into the same model, this framework avoids the complex data association process in the classical TBD paradigm, and requires no additional training. Secondly, confidence of historical trajectory regression is explored, possible states of a trajectory in the current frame (weak object or strong object) are analyzed and a confidence fusion module is designed to guide non-maximum suppression of trajectory and detection for ordered association. Finally, extensive experiments are conducted on the KITTI and Waymo datasets. The results show that the proposed method can achieve robust tracking by using only two modal detectors and it is more accurate than many of the latest TBD paradigm-based multi-modal tracking methods. The source codes of the proposed method are available at https://github.com/wangxiyang2022/YONTD-MOT
3D Multi-Object Tracking Based on Uncertainty-Guided Data Association
Mar 03, 2023



In the existing literature, most 3D multi-object tracking algorithms based on the tracking-by-detection framework employed deterministic tracks and detections for similarity calculation in the data association stage. Namely, the inherent uncertainties existing in tracks and detections are overlooked. In this work, we discard the commonly used deterministic tracks and deterministic detections for data association, instead, we propose to model tracks and detections as random vectors in which uncertainties are taken into account. Then, based on the Jensen-Shannon divergence, the similarity between two multidimensional distributions, i.e. track and detection, is evaluated for data association purposes. Lastly, the level of track uncertainty is incorporated in our cost function design to guide the data association process. Comparative experiments have been conducted on two typical datasets, KITTI and nuScenes, and the results indicated that our proposed method outperformed the compared state-of-the-art 3D tracking algorithms. For the benefit of the community, our code has been made available at https://github.com/hejiawei2023/UG3DMOT.
DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion with Deep Association
Feb 24, 2022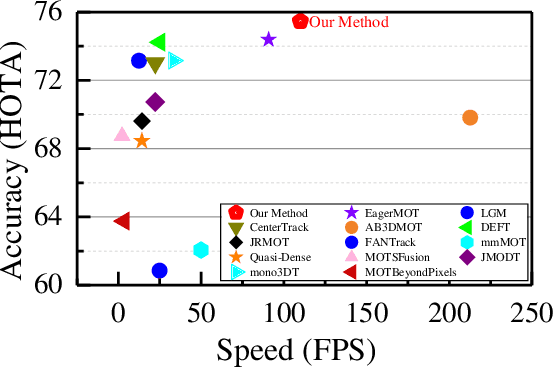
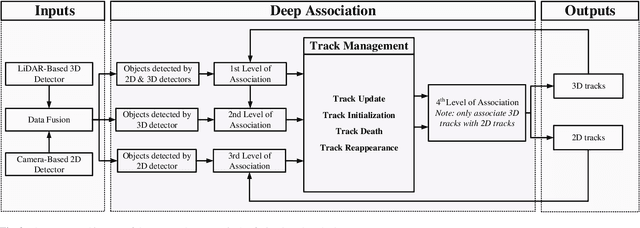
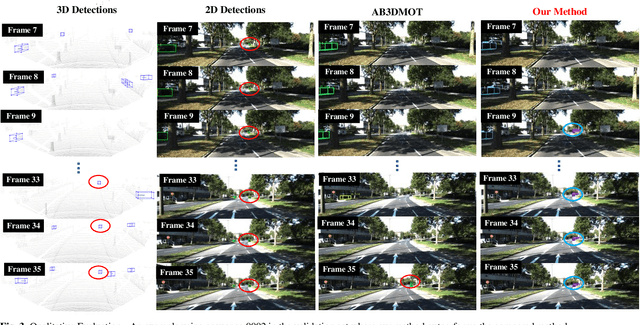

In the recent literature, on the one hand, many 3D multi-object tracking (MOT) works have focused on tracking accuracy and neglected computation speed, commonly by designing rather complex cost functions and feature extractors. On the other hand, some methods have focused too much on computation speed at the expense of tracking accuracy. In view of these issues, this paper proposes a robust and fast camera-LiDAR fusion-based MOT method that achieves a good trade-off between accuracy and speed. Relying on the characteristics of camera and LiDAR sensors, an effective deep association mechanism is designed and embedded in the proposed MOT method. This association mechanism realizes tracking of an object in a 2D domain when the object is far away and only detected by the camera, and updating of the 2D trajectory with 3D information obtained when the object appears in the LiDAR field of view to achieve a smooth fusion of 2D and 3D trajectories. Extensive experiments based on the KITTI dataset indicate that our proposed method presents obvious advantages over the state-of-the-art MOT methods in terms of both tracking accuracy and processing speed. Our code is made publicly available for the benefit of the community