 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Investigating the (De)Composition Capabilities of Large Language Models in Natural-to-Formal Language Conversion
Jan 24, 2025



To achieve generalized and robust natural-to-formal language conversion (N2F), large language models (LLMs) need to have strong capabilities of decomposition and composition in N2F when faced with an unfamiliar formal language and be able to cope with compositional gaps and counter-intuitive symbolic names. To investigate whether LLMs have this set of basic capabilities in N2F, we propose the DEDC framework. This framework semi-automatically performs sample and task construction, allowing decoupled evaluation of the set of decomposition and composition capabilities of LLMs in N2F. Based on this framework, we evaluate and analyze the most advanced LLMs, and the main findings include that: (1) the LLMs are deficient in both decomposition and composition; (2) the LLMs show a wide coverage of error types that can be attributed to deficiencies in natural language understanding and the learning and use of symbolic systems; (3) compositional gaps and counter-intuitive symbolic names both affect the decomposition and composition of the LLMs. Our work provides a new perspective for investigating the basic capabilities of decomposition and composition of LLMs in N2F. The detailed analysis of deficiencies and attributions can help subsequent improvements of LLMs.
Confidence v.s. Critique: A Decomposition of Self-Correction Capability for LLMs
Dec 27, 2024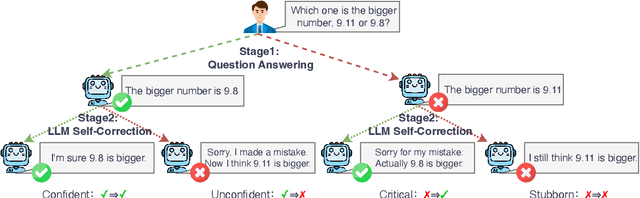
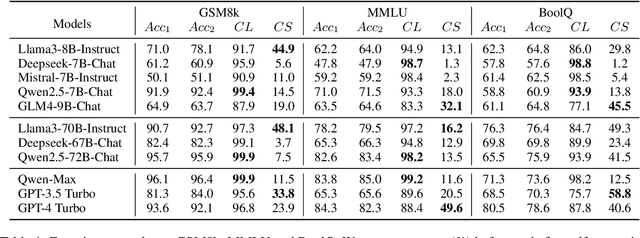
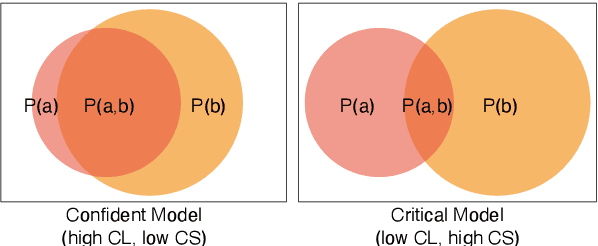

Large Language Models (LLMs) can correct their self-generated responses, but a decline in accuracy after self-correction is also witnessed. To have a deeper understanding of self-correction, we endeavor to decompose, evaluate, and analyze the self-correction behaviors of LLMs. By enumerating and analyzing answer correctness before and after self-correction, we decompose the self-correction capability into confidence (being confident to correct answers) and critique (turning wrong answers to correct) capabilities, and propose two metrics from a probabilistic perspective to measure these 2 capabilities, along with another metric for overall self-correction capability evaluation. Based on our decomposition and evaluation metrics, we conduct extensive experiments and draw some empirical conclusions. For example, we find different models can exhibit distinct behaviors: some models are confident while others are more critical. We also find the trade-off between the two capabilities (i.e. improving one can lead to a decline in the other) when manipulating model self-correction behavior by prompts or in-context learning. Further, we find a simple yet efficient strategy to improve self-correction capability by transforming Supervision Fine-Tuning (SFT) data format, and our strategy outperforms vanilla SFT in both capabilities and achieves much higher accuracy after self-correction. Our code will be publicly available on GitHub.
KiGRAS: Kinematic-Driven Generative Model for Realistic Agent Simulation
Jul 17, 2024Trajectory generation is a pivotal task in autonomous driving. Recent studies have introduced the autoregressive paradigm, leveraging the state transition model to approximate future trajectory distributions. This paradigm closely mirrors the real-world trajectory generation process and has achieved notable success. However, its potential is limited by the ineffective representation of realistic trajectories within the redundant state space. To address this limitation, we propose the Kinematic-Driven Generative Model for Realistic Agent Simulation (KiGRAS). Instead of modeling in the state space, KiGRAS factorizes the driving scene into action probability distributions at each time step, providing a compact space to represent realistic driving patterns. By establishing physical causality from actions (cause) to trajectories (effect) through the kinematic model, KiGRAS eliminates massive redundant trajectories. All states derived from actions in the cause space are constrained to be physically feasible. Furthermore, redundant trajectories representing identical action sequences are mapped to the same representation, reflecting their underlying actions. This approach significantly reduces task complexity and ensures physical feasibility. KiGRAS achieves state-of-the-art performance in Waymo's SimAgents Challenge, ranking first on the WOMD leaderboard with significantly fewer parameters than other models. The video documentation is available at \url{https://kigras-mach.github.io/KiGRAS/}.
StreamMOTP: Streaming and Unified Framework for Joint 3D Multi-Object Tracking and Trajectory Prediction
Jun 28, 20243D multi-object tracking and trajectory prediction are two crucial modules in autonomous driving systems. Generally, the two tasks are handled separately in traditional paradigms and a few methods have started to explore modeling these two tasks in a joint manner recently. However, these approaches suffer from the limitations of single-frame training and inconsistent coordinate representations between tracking and prediction tasks. In this paper, we propose a streaming and unified framework for joint 3D Multi-Object Tracking and trajectory Prediction (StreamMOTP) to address the above challenges. Firstly, we construct the model in a streaming manner and exploit a memory bank to preserve and leverage the long-term latent features for tracked objects more effectively. Secondly, a relative spatio-temporal positional encoding strategy is introduced to bridge the gap of coordinate representations between the two tasks and maintain the pose-invariance for trajectory prediction. Thirdly, we further improve the quality and consistency of predicted trajectories with a dual-stream predictor. We conduct extensive experiments on popular nuSences dataset and the experimental results demonstrate the effectiveness and superiority of StreamMOTP, which outperforms previous methods significantly on both tasks. Furthermore, we also prove that the proposed framework has great potential and advantages in actual applications of autonomous driving.
SPOR: A Comprehensive and Practical Evaluation Method for Compositional Generalization in Data-to-Text Generation
May 17, 2024



Compositional generalization is an important ability of language models and has many different manifestations. For data-to-text generation, previous research on this ability is limited to a single manifestation called Systematicity and lacks consideration of large language models (LLMs), which cannot fully cover practical application scenarios. In this work, we propose SPOR, a comprehensive and practical evaluation method for compositional generalization in data-to-text generation. SPOR includes four aspects of manifestations (Systematicity, Productivity, Order invariance, and Rule learnability) and allows high-quality evaluation without additional manual annotations based on existing datasets. We demonstrate SPOR on two different datasets and evaluate some existing language models including LLMs. We find that the models are deficient in various aspects of the evaluation and need further improvement. Our work shows the necessity for comprehensive research on different manifestations of compositional generalization in data-to-text generation and provides a framework for evaluation.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
MacFormer: Map-Agent Coupled Transformer for Real-time and Robust Trajectory Prediction
Aug 31, 2023Predicting the future behavior of agents is a fundamental task in autonomous vehicle domains. Accurate prediction relies on comprehending the surrounding map, which significantly regularizes agent behaviors. However, existing methods have limitations in exploiting the map and exhibit a strong dependence on historical trajectories, which yield unsatisfactory prediction performance and robustness. Additionally, their heavy network architectures impede real-time applications. To tackle these problems, we propose Map-Agent Coupled Transformer (MacFormer) for real-time and robust trajectory prediction. Our framework explicitly incorporates map constraints into the network via two carefully designed modules named coupled map and reference extractor. A novel multi-task optimization strategy (MTOS) is presented to enhance learning of topology and rule constraints. We also devise bilateral query scheme in context fusion for a more efficient and lightweight network. We evaluated our approach on Argoverse 1, Argoverse 2, and nuScenes real-world benchmarks, where it all achieved state-of-the-art performance with the lowest inference latency and smallest model size. Experiments also demonstrate that our framework is resilient to imperfect tracklet inputs. Furthermore, we show that by combining with our proposed strategies, classical models outperform their baselines, further validating the versatility of our framework.
GaitFormer: Revisiting Intrinsic Periodicity for Gait Recognition
Jul 25, 2023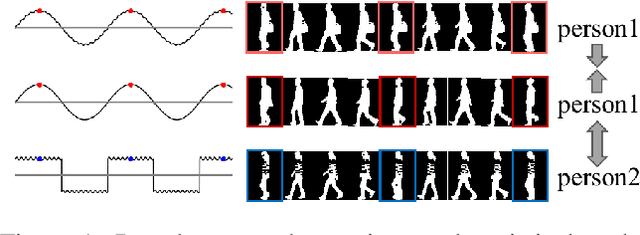
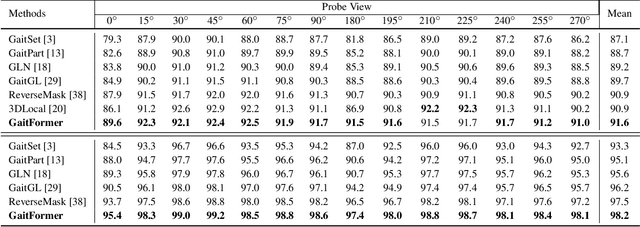
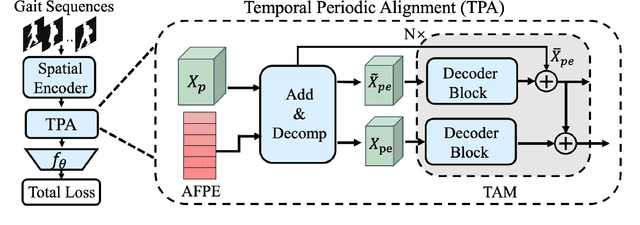
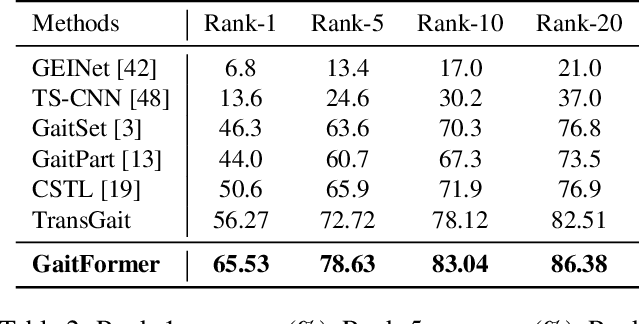
Gait recognition aims to distinguish different walking patterns by analyzing video-level human silhouettes, rather than relying on appearance information. Previous research on gait recognition has primarily focused on extracting local or global spatial-temporal representations, while overlooking the intrinsic periodic features of gait sequences, which, when fully utilized, can significantly enhance performance. In this work, we propose a plug-and-play strategy, called Temporal Periodic Alignment (TPA), which leverages the periodic nature and fine-grained temporal dependencies of gait patterns. The TPA strategy comprises two key components. The first component is Adaptive Fourier-transform Position Encoding (AFPE), which adaptively converts features and discrete-time signals into embeddings that are sensitive to periodic walking patterns. The second component is the Temporal Aggregation Module (TAM), which separates embeddings into trend and seasonal components, and extracts meaningful temporal correlations to identify primary components, while filtering out random noise. We present a simple and effective baseline method for gait recognition, based on the TPA strategy. Extensive experiments conducted on three popular public datasets (CASIA-B, OU-MVLP, and GREW) demonstrate that our proposed method achieves state-of-the-art performance on multiple benchmark tests.