 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVDrive: Latent Visual Representation Enhanced Vision-Language-Action Autonomous Driving Model
May 21, 2026Vision-Language-Action (VLA) models have emerged as a promising framework for end-to-end autonomous driving. However, existing VLAs typically rely on sparse action supervision, which underutilizes their powerful scene understanding and reasoning capabilities. Recent attempts to incorporate dense visual supervision via world modeling often overemphasize pixel-level image reconstruction, neglecting semantically meaningful scene representation learning. In this work, we propose LVDrive, a Latent Visual representation enhanced VLA framework for autonomous driving. LVDrive introduces a future scene prediction task into the VLA paradigm, where future representations are learned entirely in a high-level latent space under auxiliary supervision from a pretrained vision backbone. Departing from inefficient autoregressive generation, we jointly model future scene and motion prediction within a unified embedding space, processed in a single forward pass to conduct the future-aware reasoning. We further design a two-stage trajectory decoding strategy that explicitly leverages the learned latent future representations to refine trajectory generation. Extensive experiments on the challenging Bench2Drive benchmark demonstrate that LVDrive achieves significant improvements in closed-loop driving performance, outperforming both action supervised methods and image-reconstruction-based world model approaches.
DriveVA: Video Action Models are Zero-Shot Drivers
Apr 05, 2026Generalization is a central challenge in autonomous driving, as real-world deployment requires robust performance under unseen scenarios, sensor domains, and environmental conditions. Recent world-model-based planning methods have shown strong capabilities in scene understanding and multi-modal future prediction, yet their generalization across datasets and sensor configurations remains limited. In addition, their loosely coupled planning paradigm often leads to poor video-trajectory consistency during visual imagination. To overcome these limitations, we propose DriveVA, a novel autonomous driving world model that jointly decodes future visual forecasts and action sequences in a shared latent generative process. DriveVA inherits rich priors on motion dynamics and physical plausibility from well-pretrained large-scale video generation models to capture continuous spatiotemporal evolution and causal interaction patterns. To this end, DriveVA employs a DiT-based decoder to jointly predict future action sequences (trajectories) and videos, enabling tighter alignment between planning and scene evolution. We also introduce a video continuation strategy to strengthen long-duration rollout consistency. DriveVA achieves an impressive closed-loop performance of 90.9 PDM score on the challenge NAVSIM. Extensive experiments also demonstrate the zero-shot capability and cross-domain generalization of DriveVA, which reduces average L2 error and collision rate by 78.9% and 83.3% on nuScenes and 52.5% and 52.4% on the Bench2drive built on CARLA v2 compared with the state-of-the-art world-model-based planner.
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025


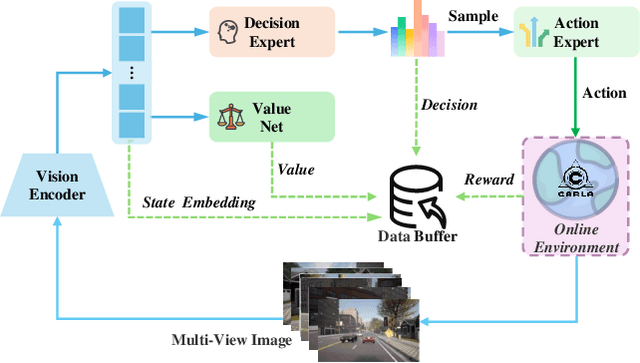
Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
PillarNeSt: Embracing Backbone Scaling and Pretraining for Pillar-based 3D Object Detection
Nov 29, 2023This paper shows the effectiveness of 2D backbone scaling and pretraining for pillar-based 3D object detectors. Pillar-based methods mainly employ randomly initialized 2D convolution neural network (ConvNet) for feature extraction and fail to enjoy the benefits from the backbone scaling and pretraining in the image domain. To show the scaling-up capacity in point clouds, we introduce the dense ConvNet pretrained on large-scale image datasets (e.g., ImageNet) as the 2D backbone of pillar-based detectors. The ConvNets are adaptively designed based on the model size according to the specific features of point clouds, such as sparsity and irregularity. Equipped with the pretrained ConvNets, our proposed pillar-based detector, termed PillarNeSt, outperforms the existing 3D object detectors by a large margin on the nuScenes and Argoversev2 datasets. Our code shall be released upon acceptance.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021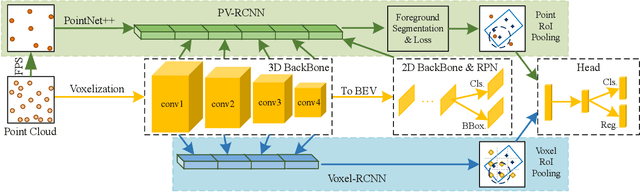
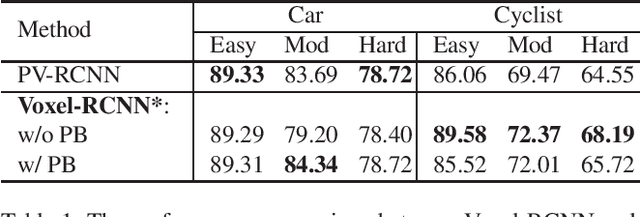
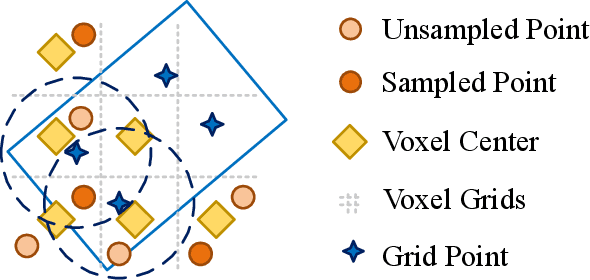

Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.