 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
A Consumer-tier based Visual-Brain Machine Interface for Augmented Reality Glasses Interactions
Aug 29, 2023



Objective.Visual-Brain Machine Interface(V-BMI) has provide a novel interaction technique for Augmented Reality (AR) industries. Several state-of-arts work has demonstates its high accuracy and real-time interaction capbilities. However, most of the studies employ EEGs devices that are rigid and difficult to apply in real-life AR glasseses application sceniraros. Here we develop a consumer-tier Visual-Brain Machine Inteface(V-BMI) system specialized for Augmented Reality(AR) glasses interactions. Approach. The developed system consists of a wearable hardware which takes advantages of fast set-up, reliable recording and comfortable wearable experience that specificized for AR glasses applications. Complementing this hardware, we have devised a software framework that facilitates real-time interactions within the system while accommodating a modular configuration to enhance scalability. Main results. The developed hardware is only 110g and 120x85x23 mm, which with 1 Tohm and peak to peak voltage is less than 1.5 uV, and a V-BMI based angry bird game and an Internet of Thing (IoT) AR applications are deisgned, we demonstrated such technology merits of intuitive experience and efficiency interaction. The real-time interaction accuracy is between 85 and 96 percentages in a commercial AR glasses (DTI is 2.24s and ITR 65 bits-min ). Significance. Our study indicates the developed system can provide an essential hardware-software framework for consumer based V-BMI AR glasses. Also, we derive several pivotal design factors for a consumer-grade V-BMI-based AR system: 1) Dynamic adaptation of stimulation patterns-classification methods via computer vision algorithms is necessary for AR glasses applications; and 2) Algorithmic localization to foster system stability and latency reduction.
PSNet: a deep learning model based digital phase shifting algorithm from a single fringe image
Mar 14, 2023



As the gold standard for phase retrieval, phase-shifting algorithm (PS) has been widely used in optical interferometry, fringe projection profilometry, etc. However, capturing multiple fringe patterns in PS limits the algorithm to only a narrow range of application. To this end, a deep learning (DL) model based digital PS algorithm from only a single fringe image is proposed. By training on a simulated dataset of PS fringe patterns, the learnt model, denoted PSNet, can predict fringe patterns with other PS steps when given a pattern with the first PS step. Simulation and experiment results demonstrate the PSNet's promising performance on accurate prediction of digital PS patterns, and robustness to complex scenarios such as surfaces with varying curvature and reflectance.
CLTS+: A New Chinese Long Text Summarization Dataset with Abstractive Summaries
Jun 09, 2022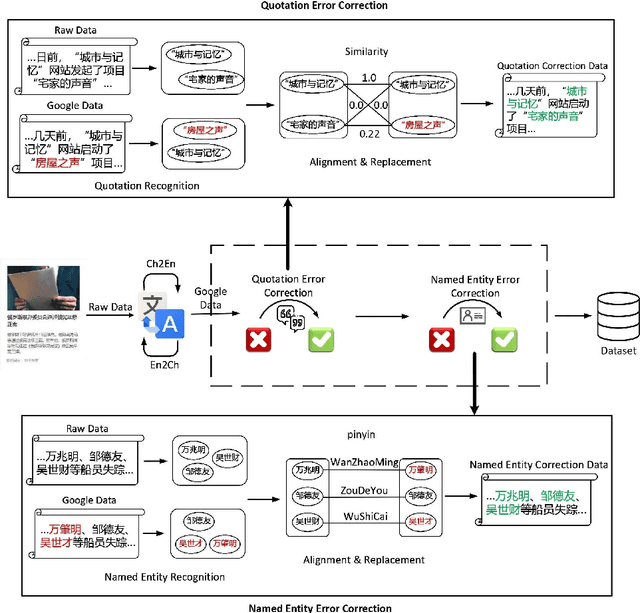


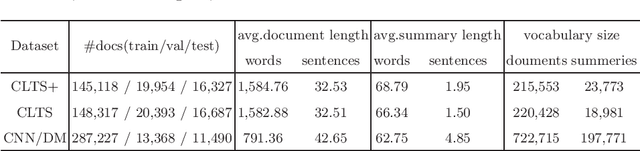
The abstractive methods lack of creative ability is particularly a problem in automatic text summarization. The summaries generated by models are mostly extracted from the source articles. One of the main causes for this problem is the lack of dataset with abstractiveness, especially for Chinese. In order to solve this problem, we paraphrase the reference summaries in CLTS, the Chinese Long Text Summarization dataset, correct errors of factual inconsistencies, and propose the first Chinese Long Text Summarization dataset with a high level of abstractiveness, CLTS+, which contains more than 180K article-summary pairs and is available online. Additionally, we introduce an intrinsic metric based on co-occurrence words to evaluate the dataset we constructed. We analyze the extraction strategies used in CLTS+ summaries against other datasets to quantify the abstractiveness and difficulty of our new data and train several baselines on CLTS+ to verify the utility of it for improving the creative ability of models.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021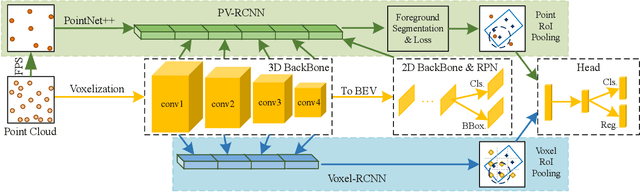
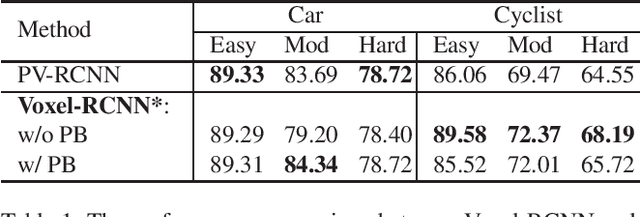
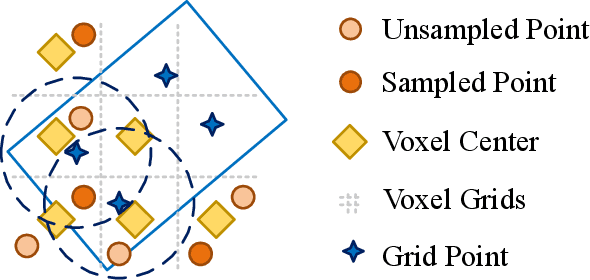

Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.