 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Agreement: Scoring Panel-Surfaced Biomedical Entity Candidates for Curator Triage
May 29, 2026Biomedical NER is deceptively simple for modern LLMs: plausible biomedical mentions are easy to surface, but corpus-convention correctness depends on annotation conventions, span boundaries, entity granularity, and type schemas. Multi-LLM agreement is a salience signal, not corpus-convention correctness. We introduce a candidate-level panel-output benchmark for panel-surfaced candidate verification, where the unit is an aligned candidate surfaced by an explicitly defined multi-model panel rather than a standalone extractor output. The benchmark aligns eight LLMs' predictions over five public biomedical NER datasets into a candidate master table. BioConCal is an in-domain supervised scorer that instantiates this layer with inference-time gold-free agreement, mention, surface-availability, and document features for a fixed candidate stream. In domain, BioConCal improves AUROC from 0.753 for raw agreement to 0.910. At a validation-selected 0.95 precision target it selects 1,340 candidates at empirical test precision 0.939, compared with 293 for raw agreement. This corresponds to candidate-level recall 0.592 and corpus-level recall 0.523 against a within-panel row-label ceiling of 0.883. The main benefit is not recovering entities missed by every panel member, but reshaping a noisy panel stream into a higher-yield review queue. Under entity-type shift, thresholds require target-domain validation, and exact character localization remains a separate deterministic post-processing step.
Uno-Orchestra: Parsimonious Agent Routing via Selective Delegation
May 06, 2026Large language model (LLM) multi-agent systems typically rely on rigid orchestration, committing either to flat per-query routing or to hand-engineered task decomposition, so decomposition depth, worker choice, and inference budget are not jointly optimized under one objective. We introduce Uno-Orchestra, a unified orchestration policy that selectively decomposes a task and dispatches each subtask to an admissible (model, primitive) pair, with both decisions learned together from curated RL trajectories grounded in real worker interactions. Against 22 baselines on a 13-benchmark suite spanning math, code, knowledge, long-context, and agentic tool-use, Uno-Orchestra reaches 77.0% macro pass@1, roughly 16% above the strongest workflow baseline, at roughly an order of magnitude lower per-query cost, advancing the accuracy-efficiency frontier of selective delegation.
From Experience to Skill: Multi-Agent Generative Engine Optimization via Reusable Strategy Learning
Apr 21, 2026Generative engines (GEs) are reshaping information access by replacing ranked links with citation-grounded answers, yet current Generative Engine Optimization (GEO) methods optimize each instance in isolation, unable to accumulate or transfer effective strategies across tasks and engines. We reframe GEO as a strategy learning problem and propose MAGEO, a multi-agent framework in which coordinated planning, editing, and fidelity-aware evaluation serve as the execution layer, while validated editing patterns are progressively distilled into reusable, engine-specific optimization skills. To enable controlled assessment, we introduce a Twin Branch Evaluation Protocol for causal attribution of content edits and DSV-CF, a dual-axis metric that unifies semantic visibility with attribution accuracy. We further release MSME-GEO-Bench, a multi-scenario, multi-engine benchmark grounded in real-world queries. Experiments on three mainstream engines show that MAGEO substantially outperforms heuristic baselines in both visibility and citation fidelity, with ablations confirming that engine-specific preference modeling and strategy reuse are central to these gains, suggesting a scalable learning-driven paradigm for trustworthy GEO. Code is available at https://github.com/Wu-beining/MAGEO
Sparse but not Simpler: A Multi-Level Interpretability Analysis of Vision Transformers
Mar 16, 2026Sparse neural networks are often hypothesized to be more interpretable than dense models, motivated by findings that weight sparsity can produce compact circuits in language models. However, it remains unclear whether structural sparsity itself leads to improved semantic interpretability. In this work, we systematically evaluate the relationship between weight sparsity and interpretability in Vision Transformers using DeiT-III B/16 models pruned with Wanda. To assess interpretability comprehensively, we introduce \textbf{IMPACT}, a multi-level framework that evaluates interpretability across four complementary levels: neurons, layer representations, task circuits, and model-level attribution. Layer representations are analyzed using BatchTopK sparse autoencoders, circuits are extracted via learnable node masking, and explanations are evaluated with transformer attribution using insertion and deletion metrics. Our results reveal a clear structural effect but limited interpretability gains. Sparse models produce circuits with approximately $2.5\times$ fewer edges than dense models, yet the fraction of active nodes remains similar or higher, indicating that pruning redistributes computation rather than isolating simpler functional modules. Consistent with this observation, sparse models show no systematic improvements in neuron-level selectivity, SAE feature interpretability, or attribution faithfulness. These findings suggest that structural sparsity alone does not reliably yield more interpretable vision models, highlighting the importance of evaluation frameworks that assess interpretability beyond circuit compactness.
Zero-Forgetting CISS via Dual-Phase Cognitive Cascades
Mar 14, 2026Continual semantic segmentation (CSS) is a cornerstone task in computer vision that enables a large number of downstream applications, but faces the catastrophic forgetting challenge. In conventional class-incremental semantic segmentation (CISS) frameworks using Softmax-based classification heads, catastrophic forgetting originates from Catastrophic forgetting and task affiliation probability. We formulate these problems and provide a theoretical analysis to more deeply understand the limitations in existing CISS methods, particularly Strict Parameter Isolation (SPI). To address these challenges, we follow a dual-phase intuition from human annotators, and introduce Cognitive Cascade Segmentation (CogCaS), a novel dual-phase cascade formulation for CSS tasks in the CISS setting. By decoupling the task into class-existence detection and class-specific segmentation, CogCaS enables more effective continual learning, preserving previously learned knowledge while incorporating new classes. Using two benchmark datasets PASCAL VOC 2012 and ADE20K, we have shown significant improvements in a variety of challenging scenarios, particularly those with long sequence of incremental tasks, when compared to exsiting state-of-the-art methods. Our code will be made publicly available upon paper acceptance.
Shape of Thought: Progressive Object Assembly via Visual Chain-of-Thought
Jan 28, 2026Multimodal models for text-to-image generation have achieved strong visual fidelity, yet they remain brittle under compositional structural constraints-notably generative numeracy, attribute binding, and part-level relations. To address these challenges, we propose Shape-of-Thought (SoT), a visual CoT framework that enables progressive shape assembly via coherent 2D projections without external engines at inference time. SoT trains a unified multimodal autoregressive model to generate interleaved textual plans and rendered intermediate states, helping the model capture shape-assembly logic without producing explicit geometric representations. To support this paradigm, we introduce SoT-26K, a large-scale dataset of grounded assembly traces derived from part-based CAD hierarchies, and T2S-CompBench, a benchmark for evaluating structural integrity and trace faithfulness. Fine-tuning on SoT-26K achieves 88.4% on component numeracy and 84.8% on structural topology, outperforming text-only baselines by around 20%. SoT establishes a new paradigm for transparent, process-supervised compositional generation. The code is available at https://anonymous.4open.science/r/16FE/. The SoT-26K dataset will be released upon acceptance.
Multimodal Interpretation of Remote Sensing Images: Dynamic Resolution Input Strategy and Multi-scale Vision-Language Alignment Mechanism
Dec 29, 2025Multimodal fusion of remote sensing images serves as a core technology for overcoming the limitations of single-source data and improving the accuracy of surface information extraction, which exhibits significant application value in fields such as environmental monitoring and urban planning. To address the deficiencies of existing methods, including the failure of fixed resolutions to balance efficiency and detail, as well as the lack of semantic hierarchy in single-scale alignment, this study proposes a Vision-language Model (VLM) framework integrated with two key innovations: the Dynamic Resolution Input Strategy (DRIS) and the Multi-scale Vision-language Alignment Mechanism (MS-VLAM).Specifically, the DRIS adopts a coarse-to-fine approach to adaptively allocate computational resources according to the complexity of image content, thereby preserving key fine-grained features while reducing redundant computational overhead. The MS-VLAM constructs a three-tier alignment mechanism covering object, local-region and global levels, which systematically captures cross-modal semantic consistency and alleviates issues of semantic misalignment and granularity imbalance.Experimental results on the RS-GPT4V dataset demonstrate that the proposed framework significantly improves the accuracy of semantic understanding and computational efficiency in tasks including image captioning and cross-modal retrieval. Compared with conventional methods, it achieves superior performance in evaluation metrics such as BLEU-4 and CIDEr for image captioning, as well as R@10 for cross-modal retrieval. This technical framework provides a novel approach for constructing efficient and robust multimodal remote sensing systems, laying a theoretical foundation and offering technical guidance for the engineering application of intelligent remote sensing interpretation.
Toward Faithfulness-guided Ensemble Interpretation of Neural Network
Sep 04, 2025Interpretable and faithful explanations for specific neural inferences are crucial for understanding and evaluating model behavior. Our work introduces \textbf{F}aithfulness-guided \textbf{E}nsemble \textbf{I}nterpretation (\textbf{FEI}), an innovative framework that enhances the breadth and effectiveness of faithfulness, advancing interpretability by providing superior visualization. Through an analysis of existing evaluation benchmarks, \textbf{FEI} employs a smooth approximation to elevate quantitative faithfulness scores. Diverse variations of \textbf{FEI} target enhanced faithfulness in hidden layer encodings, expanding interpretability. Additionally, we propose a novel qualitative metric that assesses hidden layer faithfulness. In extensive experiments, \textbf{FEI} surpasses existing methods, demonstrating substantial advances in qualitative visualization and quantitative faithfulness scores. Our research establishes a comprehensive framework for elevating faithfulness in neural network explanations, emphasizing both breadth and precision
Decoupling Continual Semantic Segmentation
Aug 07, 2025Continual Semantic Segmentation (CSS) requires learning new classes without forgetting previously acquired knowledge, addressing the fundamental challenge of catastrophic forgetting in dense prediction tasks. However, existing CSS methods typically employ single-stage encoder-decoder architectures where segmentation masks and class labels are tightly coupled, leading to interference between old and new class learning and suboptimal retention-plasticity balance. We introduce DecoupleCSS, a novel two-stage framework for CSS. By decoupling class-aware detection from class-agnostic segmentation, DecoupleCSS enables more effective continual learning, preserving past knowledge while learning new classes. The first stage leverages pre-trained text and image encoders, adapted using LoRA, to encode class-specific information and generate location-aware prompts. In the second stage, the Segment Anything Model (SAM) is employed to produce precise segmentation masks, ensuring that segmentation knowledge is shared across both new and previous classes. This approach improves the balance between retention and adaptability in CSS, achieving state-of-the-art performance across a variety of challenging tasks. Our code is publicly available at: https://github.com/euyis1019/Decoupling-Continual-Semantic-Segmentation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
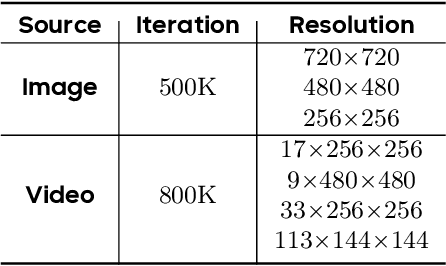
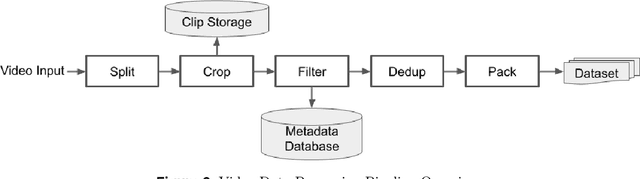

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/