 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeB-SLAM: Neural Blocks-based Salable RGB-D SLAM for Unknown Scenes
May 24, 2024
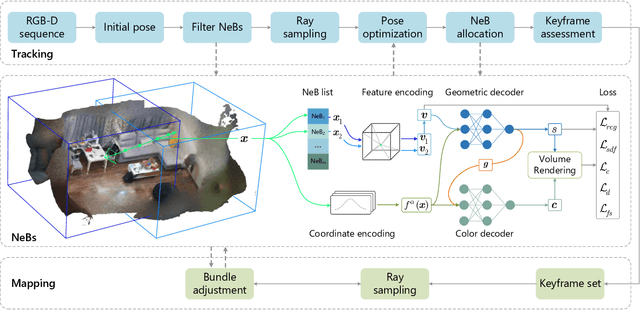
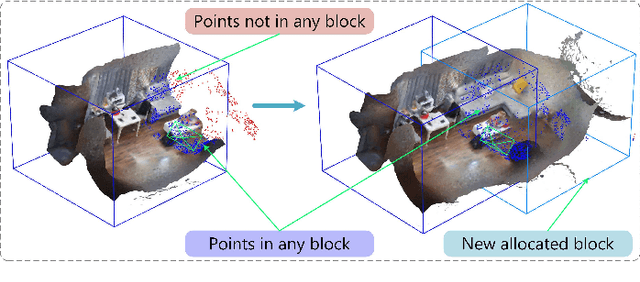

Neural implicit representations have recently demonstrated considerable potential in the field of visual simultaneous localization and mapping (SLAM). This is due to their inherent advantages, including low storage overhead and representation continuity. However, these methods necessitate the size of the scene as input, which is impractical for unknown scenes. Consequently, we propose NeB-SLAM, a neural block-based scalable RGB-D SLAM for unknown scenes. Specifically, we first propose a divide-and-conquer mapping strategy that represents the entire unknown scene as a set of sub-maps. These sub-maps are a set of neural blocks of fixed size. Then, we introduce an adaptive map growth strategy to achieve adaptive allocation of neural blocks during camera tracking and gradually cover the whole unknown scene. Finally, extensive evaluations on various datasets demonstrate that our method is competitive in both mapping and tracking when targeting unknown environments.
Artificial-Spiking Hierarchical Networks for Vision-Language Representation Learning
Aug 18, 2023With the success of self-supervised learning, multimodal foundation models have rapidly adapted a wide range of downstream tasks driven by vision and language (VL) pretraining. State-of-the-art methods achieve impressive performance by pre-training on large-scale datasets. However, bridging the semantic gap between the two modalities remains a nonnegligible challenge for VL tasks. In this work, we propose an efficient computation framework for multimodal alignment by introducing a novel visual semantic module to further improve the performance of the VL tasks. Specifically, we propose a flexible model, namely Artificial-Spiking Hierarchical Networks (ASH-Nets), which combines the complementary advantages of Artificial neural networks (ANNs) and Spiking neural networks (SNNs) to enrich visual semantic representations. In particular, a visual concrete encoder and a semantic abstract encoder are constructed to learn continuous and discrete latent variables to enhance the flexibility of semantic encoding. Considering the spatio-temporal properties of SNNs modeling, we introduce a contrastive learning method to optimize the inputs of similar samples. This can improve the computational efficiency of the hierarchical network, while the augmentation of hard samples is beneficial to the learning of visual representations. Furthermore, the Spiking to Text Uni-Alignment Learning (STUA) pre-training method is proposed, which only relies on text features to enhance the encoding ability of abstract semantics. We validate the performance on multiple well-established downstream VL tasks. Experiments show that the proposed ASH-Nets achieve competitive results.