 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHG2P: Hippocampus-inspired High-reward Graph and Model-Free Q-Gradient Penalty for Path Planning and Motion Control
Oct 12, 2024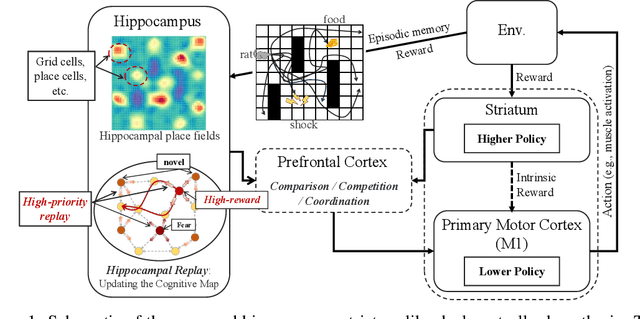
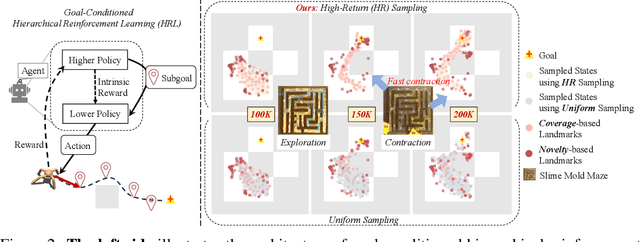
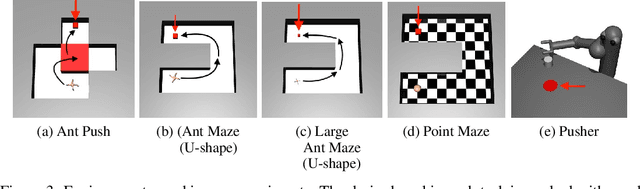
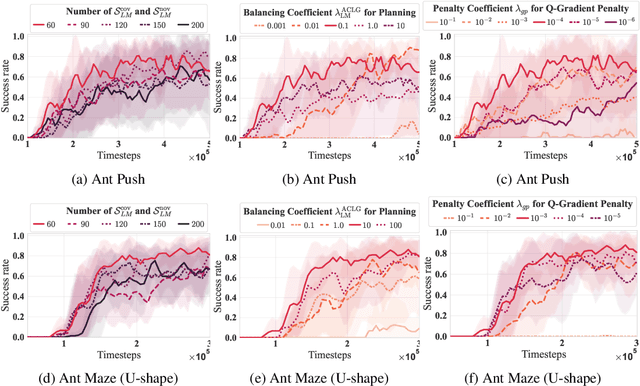
Goal-conditioned hierarchical reinforcement learning (HRL) decomposes complex reaching tasks into a sequence of simple subgoal-conditioned tasks, showing significant promise for addressing long-horizon planning in large-scale environments. This paper bridges the goal-conditioned HRL based on graph-based planning to brain mechanisms, proposing a hippocampus-striatum-like dual-controller hypothesis. Inspired by the brain mechanisms of organisms (i.e., the high-reward preferences observed in hippocampal replay) and instance-based theory, we propose a high-return sampling strategy for constructing memory graphs, improving sample efficiency. Additionally, we derive a model-free lower-level Q-function gradient penalty to resolve the model dependency issues present in prior work, improving the generalization of Lipschitz constraints in applications. Finally, we integrate these two extensions, High-reward Graph and model-free Gradient Penalty (HG2P), into the state-of-the-art framework ACLG, proposing a novel goal-conditioned HRL framework, HG2P+ACLG. Experimentally, the results demonstrate that our method outperforms state-of-the-art goal-conditioned HRL algorithms on a variety of long-horizon navigation tasks and robotic manipulation tasks.
Multiscale Superpixel Structured Difference Graph Convolutional Network for VL Representation
Oct 25, 2023



Within the multimodal field, the key to integrating vision and language lies in establishing a good alignment strategy. Recently, benefiting from the success of self-supervised learning, significant progress has been made in multimodal semantic representation based on pre-trained models for vision and language. However, there is still room for improvement in visual semantic representation. The lack of spatial semantic coherence and vulnerability to noise makes it challenging for current pixel or patch-based methods to accurately extract complex scene boundaries. To this end, this paper develops superpixel as a comprehensive compact representation of learnable image data, which effectively reduces the number of visual primitives for subsequent processing by clustering perceptually similar pixels. To mine more precise topological relations, we propose a Multiscale Difference Graph Convolutional Network (MDGCN). It parses the entire image as a fine-to-coarse hierarchical structure of constituent visual patterns, and captures multiscale features by progressively merging adjacent superpixels as graph nodes. Moreover, we predict the differences between adjacent nodes through the graph structure, facilitating key information aggregation of graph nodes to reason actual semantic relations. Afterward, we design a multi-level fusion rule in a bottom-up manner to avoid understanding deviation by learning complementary spatial information at different regional scales. Our proposed method can be well applied to multiple downstream task learning. Extensive experiments demonstrate that our method is competitive with other state-of-the-art methods in visual reasoning. Our code will be released upon publication.
Guided Cooperation in Hierarchical Reinforcement Learning via Model-based Rollout
Sep 24, 2023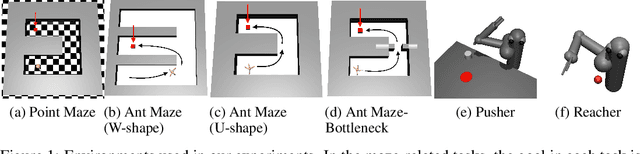
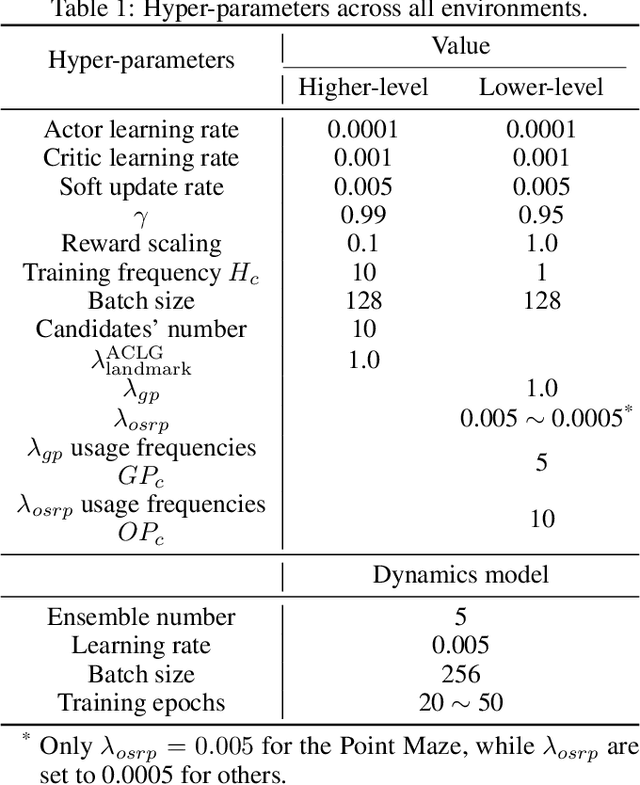
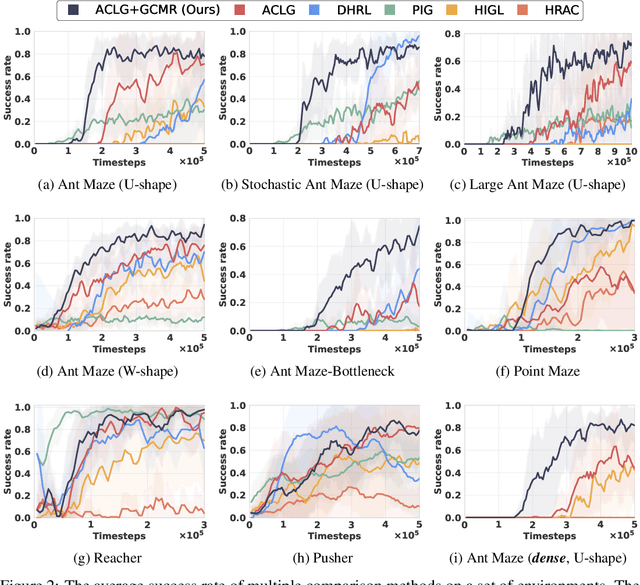
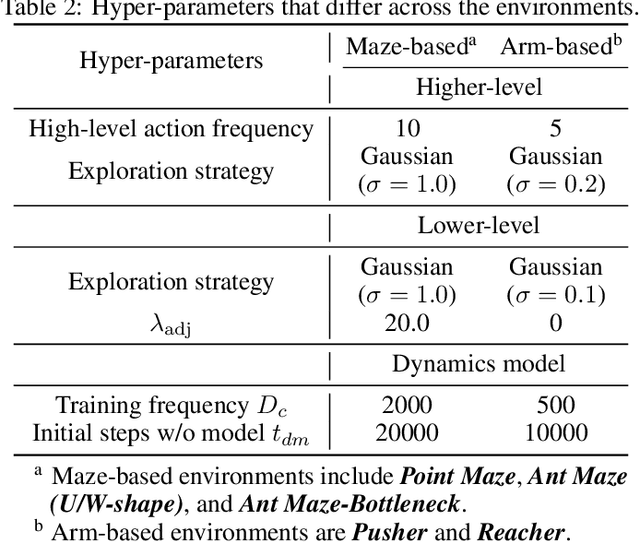
Goal-conditioned hierarchical reinforcement learning (HRL) presents a promising approach for enabling effective exploration in complex long-horizon reinforcement learning (RL) tasks via temporal abstraction. Yet, most goal-conditioned HRL algorithms focused on the subgoal discovery, regardless of inter-level coupling. In essence, for hierarchical systems, the increased inter-level communication and coordination can induce more stable and robust policy improvement. Here, we present a goal-conditioned HRL framework with Guided Cooperation via Model-based Rollout (GCMR), which estimates forward dynamics to promote inter-level cooperation. The GCMR alleviates the state-transition error within off-policy correction through a model-based rollout, further improving the sample efficiency. Meanwhile, to avoid being disrupted by these corrected but possibly unseen or faraway goals, lower-level Q-function gradients are constrained using a gradient penalty with a model-inferred upper bound, leading to a more stable behavioral policy. Besides, we propose a one-step rollout-based planning to further facilitate inter-level cooperation, where the higher-level Q-function is used to guide the lower-level policy by estimating the value of future states so that global task information is transmitted downwards to avoid local pitfalls. Experimental results demonstrate that incorporating the proposed GCMR framework with ACLG, a disentangled variant of HIGL, yields more stable and robust policy improvement than baselines and substantially outperforms previous state-of-the-art (SOTA) HRL algorithms in both hard-exploration problems and robotic control.
Artificial-Spiking Hierarchical Networks for Vision-Language Representation Learning
Aug 18, 2023With the success of self-supervised learning, multimodal foundation models have rapidly adapted a wide range of downstream tasks driven by vision and language (VL) pretraining. State-of-the-art methods achieve impressive performance by pre-training on large-scale datasets. However, bridging the semantic gap between the two modalities remains a nonnegligible challenge for VL tasks. In this work, we propose an efficient computation framework for multimodal alignment by introducing a novel visual semantic module to further improve the performance of the VL tasks. Specifically, we propose a flexible model, namely Artificial-Spiking Hierarchical Networks (ASH-Nets), which combines the complementary advantages of Artificial neural networks (ANNs) and Spiking neural networks (SNNs) to enrich visual semantic representations. In particular, a visual concrete encoder and a semantic abstract encoder are constructed to learn continuous and discrete latent variables to enhance the flexibility of semantic encoding. Considering the spatio-temporal properties of SNNs modeling, we introduce a contrastive learning method to optimize the inputs of similar samples. This can improve the computational efficiency of the hierarchical network, while the augmentation of hard samples is beneficial to the learning of visual representations. Furthermore, the Spiking to Text Uni-Alignment Learning (STUA) pre-training method is proposed, which only relies on text features to enhance the encoding ability of abstract semantics. We validate the performance on multiple well-established downstream VL tasks. Experiments show that the proposed ASH-Nets achieve competitive results.
LOIS: Looking Out of Instance Semantics for Visual Question Answering
Jul 26, 2023Visual question answering (VQA) has been intensively studied as a multimodal task that requires effort in bridging vision and language to infer answers correctly. Recent attempts have developed various attention-based modules for solving VQA tasks. However, the performance of model inference is largely bottlenecked by visual processing for semantics understanding. Most existing detection methods rely on bounding boxes, remaining a serious challenge for VQA models to understand the causal nexus of object semantics in images and correctly infer contextual information. To this end, we propose a finer model framework without bounding boxes in this work, termed Looking Out of Instance Semantics (LOIS) to tackle this important issue. LOIS enables more fine-grained feature descriptions to produce visual facts. Furthermore, to overcome the label ambiguity caused by instance masks, two types of relation attention modules: 1) intra-modality and 2) inter-modality, are devised to infer the correct answers from the different multi-view features. Specifically, we implement a mutual relation attention module to model sophisticated and deeper visual semantic relations between instance objects and background information. In addition, our proposed attention model can further analyze salient image regions by focusing on important word-related questions. Experimental results on four benchmark VQA datasets prove that our proposed method has favorable performance in improving visual reasoning capability.
Task-oriented Memory-efficient Pruning-Adapter
Apr 06, 2023

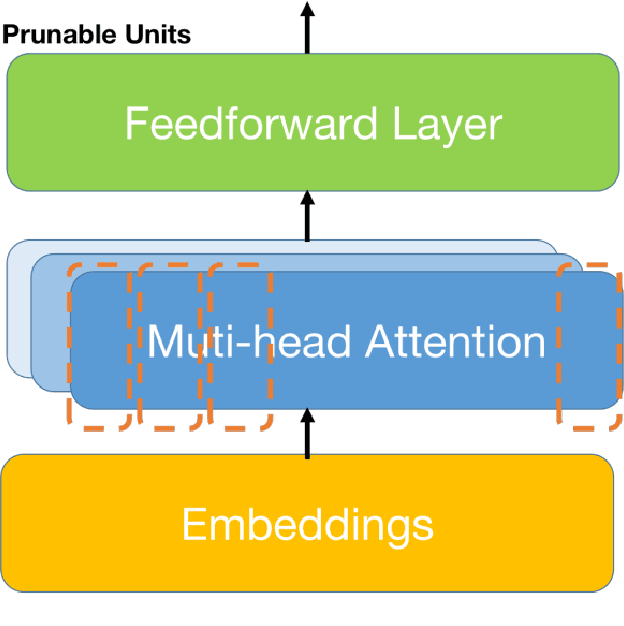

The Outstanding performance and growing size of Large Language Models has led to increased attention in parameter efficient learning. The two predominant approaches are Adapters and Pruning. Adapters are to freeze the model and give it a new weight matrix on the side, which can significantly reduce the time and memory of training, but the cost is that the evaluation and testing will increase the time and memory consumption. Pruning is to cut off some weight and re-distribute the remaining weight, which sacrifices the complexity of training at the cost of extremely high memory and training time, making the cost of evaluation and testing relatively low. So efficiency of training and inference can't be obtained in the same time. In this work, we propose a task-oriented Pruning-Adapter method that achieve a high memory efficiency of training and memory, and speeds up training time and ensures no significant decrease in accuracy in GLUE tasks, achieving training and inference efficiency at the same time.
Pixel Difference Convolutional Network for RGB-D Semantic Segmentation
Feb 23, 2023RGB-D semantic segmentation can be advanced with convolutional neural networks due to the availability of Depth data. Although objects cannot be easily discriminated by just the 2D appearance, with the local pixel difference and geometric patterns in Depth, they can be well separated in some cases. Considering the fixed grid kernel structure, CNNs are limited to lack the ability to capture detailed, fine-grained information and thus cannot achieve accurate pixel-level semantic segmentation. To solve this problem, we propose a Pixel Difference Convolutional Network (PDCNet) to capture detailed intrinsic patterns by aggregating both intensity and gradient information in the local range for Depth data and global range for RGB data, respectively. Precisely, PDCNet consists of a Depth branch and an RGB branch. For the Depth branch, we propose a Pixel Difference Convolution (PDC) to consider local and detailed geometric information in Depth data via aggregating both intensity and gradient information. For the RGB branch, we contribute a lightweight Cascade Large Kernel (CLK) to extend PDC, namely CPDC, to enjoy global contexts for RGB data and further boost performance. Consequently, both modal data's local and global pixel differences are seamlessly incorporated into PDCNet during the information propagation process. Experiments on two challenging benchmark datasets, i.e., NYUDv2 and SUN RGB-D reveal that our PDCNet achieves state-of-the-art performance for the semantic segmentation task.
DCANet: Differential Convolution Attention Network for RGB-D Semantic Segmentation
Oct 13, 2022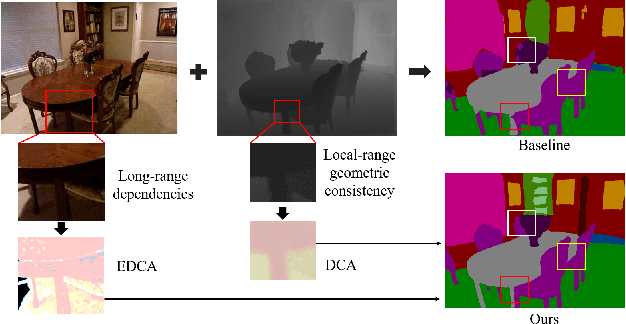
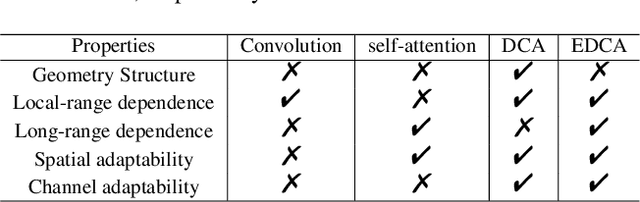
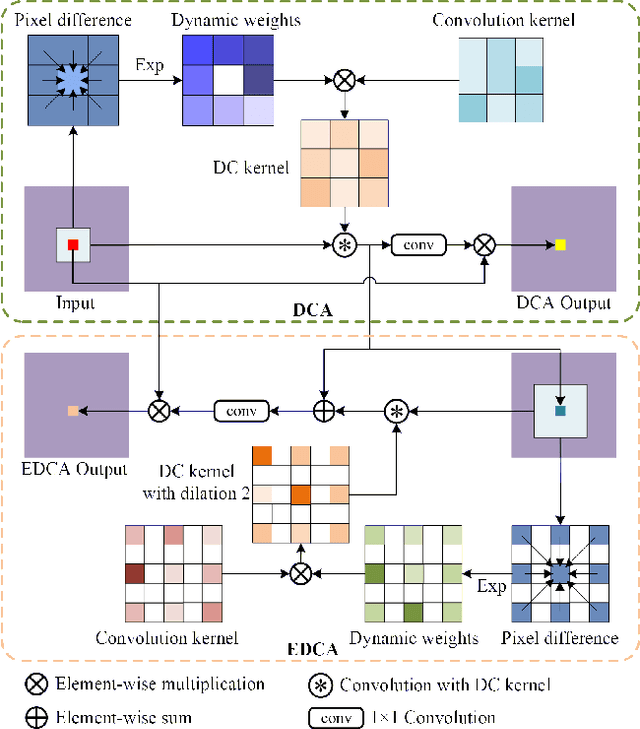
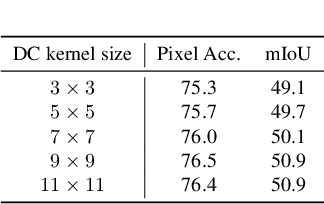
Combining RGB images and the corresponding depth maps in semantic segmentation proves the effectiveness in the past few years. Existing RGB-D modal fusion methods either lack the non-linear feature fusion ability or treat both modal images equally, regardless of the intrinsic distribution gap or information loss. Here we find that depth maps are suitable to provide intrinsic fine-grained patterns of objects due to their local depth continuity, while RGB images effectively provide a global view. Based on this, we propose a pixel differential convolution attention (DCA) module to consider geometric information and local-range correlations for depth data. Furthermore, we extend DCA to ensemble differential convolution attention (EDCA) which propagates long-range contextual dependencies and seamlessly incorporates spatial distribution for RGB data. DCA and EDCA dynamically adjust convolutional weights by pixel difference to enable self-adaptive in local and long range, respectively. A two-branch network built with DCA and EDCA, called Differential Convolutional Network (DCANet), is proposed to fuse local and global information of two-modal data. Consequently, the individual advantage of RGB and depth data are emphasized. Our DCANet is shown to set a new state-of-the-art performance for RGB-D semantic segmentation on two challenging benchmark datasets, i.e., NYUDv2 and SUN-RGBD.