 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Cooperation in Hierarchical Reinforcement Learning via Model-based Rollout
Paper and Code
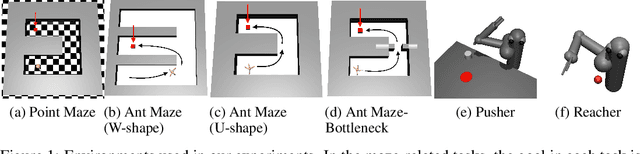
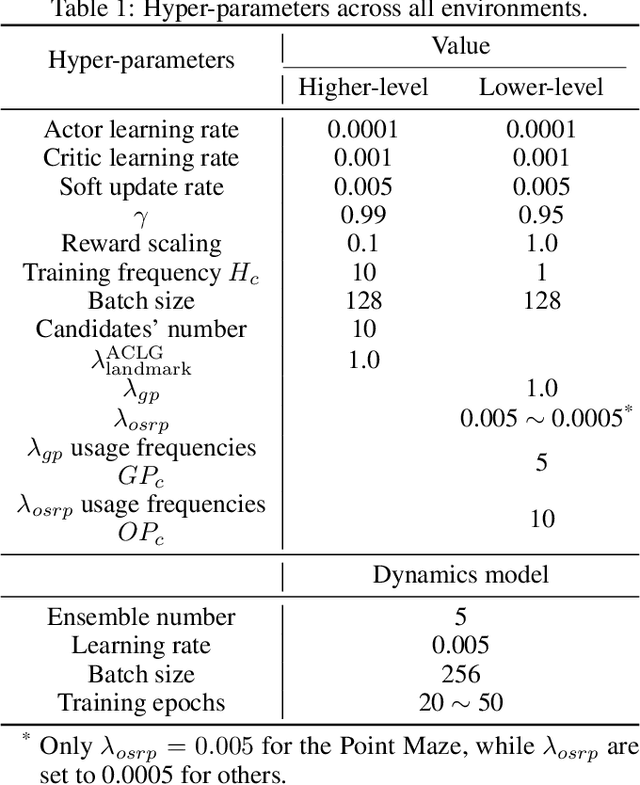
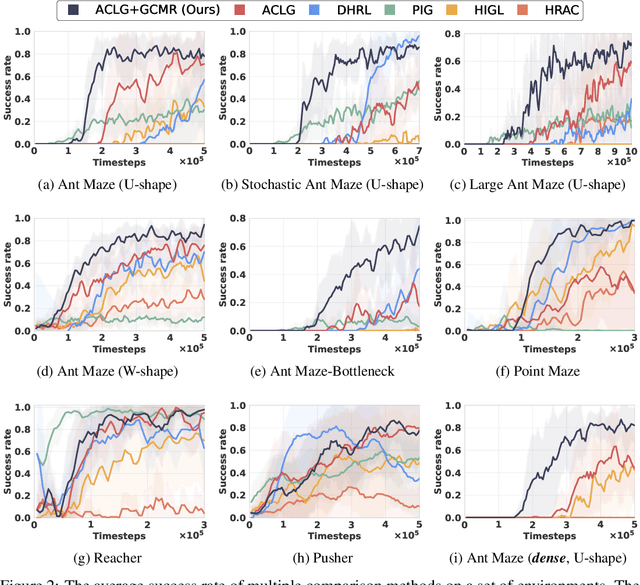
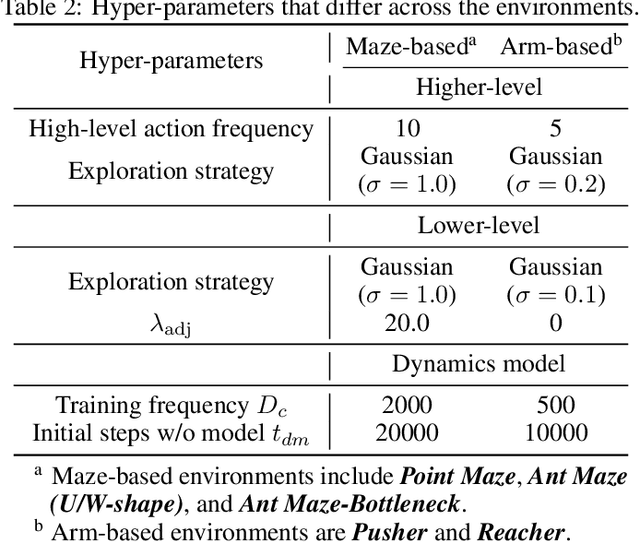
Goal-conditioned hierarchical reinforcement learning (HRL) presents a promising approach for enabling effective exploration in complex long-horizon reinforcement learning (RL) tasks via temporal abstraction. Yet, most goal-conditioned HRL algorithms focused on the subgoal discovery, regardless of inter-level coupling. In essence, for hierarchical systems, the increased inter-level communication and coordination can induce more stable and robust policy improvement. Here, we present a goal-conditioned HRL framework with Guided Cooperation via Model-based Rollout (GCMR), which estimates forward dynamics to promote inter-level cooperation. The GCMR alleviates the state-transition error within off-policy correction through a model-based rollout, further improving the sample efficiency. Meanwhile, to avoid being disrupted by these corrected but possibly unseen or faraway goals, lower-level Q-function gradients are constrained using a gradient penalty with a model-inferred upper bound, leading to a more stable behavioral policy. Besides, we propose a one-step rollout-based planning to further facilitate inter-level cooperation, where the higher-level Q-function is used to guide the lower-level policy by estimating the value of future states so that global task information is transmitted downwards to avoid local pitfalls. Experimental results demonstrate that incorporating the proposed GCMR framework with ACLG, a disentangled variant of HIGL, yields more stable and robust policy improvement than baselines and substantially outperforms previous state-of-the-art (SOTA) HRL algorithms in both hard-exploration problems and robotic control.