 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Omni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis
Jan 31, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities, yet their performance is often capped by the coarse nature of existing alignment techniques. A critical bottleneck remains the lack of effective reward models (RMs): existing RMs are predominantly vision-centric, return opaque scalar scores, and rely on costly human annotations. We introduce \textbf{Omni-RRM}, the first open-source rubric-grounded reward model that produces structured, multi-dimension preference judgments with dimension-wise justifications across \textbf{text, image, video, and audio}. At the core of our approach is \textbf{Omni-Preference}, a large-scale dataset built via a fully automated pipeline: we synthesize candidate response pairs by contrasting models of different capabilities, and use strong teacher models to \emph{reconcile and filter} preferences while providing a modality-aware \emph{rubric-grounded rationale} for each pair. This eliminates the need for human-labeled training preferences. Omni-RRM is trained in two stages: supervised fine-tuning to learn the rubric-grounded outputs, followed by reinforcement learning (GRPO) to sharpen discrimination on difficult, low-contrast pairs. Comprehensive evaluations show that Omni-RRM achieves state-of-the-art accuracy on video (80.2\% on ShareGPT-V) and audio (66.8\% on Audio-HH-RLHF) benchmarks, and substantially outperforms existing open-source RMs on image tasks, with a 17.7\% absolute gain over its base model on overall accuracy. Omni-RRM also improves downstream performance via Best-of-$N$ selection and transfers to text-only preference benchmarks. Our data, code, and models are available at https://anonymous.4open.science/r/Omni-RRM-CC08.
TIDAL: Temporally Interleaved Diffusion and Action Loop for High-Frequency VLA Control
Jan 21, 2026Large-scale Vision-Language-Action (VLA) models offer semantic generalization but suffer from high inference latency, limiting them to low-frequency batch-and-execute paradigm. This frequency mismatch creates an execution blind spot, causing failures in dynamic environments where targets move during the open-loop execution window. We propose TIDAL (Temporally Interleaved Diffusion and Action Loop), a hierarchical framework that decouples semantic reasoning from high-frequency actuation. TIDAL operates as a backbone-agnostic module for diffusion-based VLAs, using a dual-frequency architecture to redistribute the computational budget. Specifically, a low-frequency macro-intent loop caches semantic embeddings, while a high-frequency micro-control loop interleaves single-step flow integration with execution. This design enables approximately 9 Hz control updates on edge hardware (vs. approximately 2.4 Hz baselines) without increasing marginal overhead. To handle the resulting latency shift, we introduce a temporally misaligned training strategy where the policy learns predictive compensation using stale semantic intent alongside real-time proprioception. Additionally, we address the insensitivity of static vision encoders to velocity by incorporating a differential motion predictor. TIDAL is architectural, making it orthogonal to system-level optimizations. Experiments show a 2x performance gain over open-loop baselines in dynamic interception tasks. Despite a marginal regression in static success rates, our approach yields a 4x increase in feedback frequency and extends the effective horizon of semantic embeddings beyond the native action chunk size. Under non-paused inference protocols, TIDAL remains robust where standard baselines fail due to latency.
Open World Knowledge Aided Single-Cell Foundation Model with Robust Cross-Modal Cell-Language Pre-training
Jan 09, 2026Recent advancements in single-cell multi-omics, particularly RNA-seq, have provided profound insights into cellular heterogeneity and gene regulation. While pre-trained language model (PLM) paradigm based single-cell foundation models have shown promise, they remain constrained by insufficient integration of in-depth individual profiles and neglecting the influence of noise within multi-modal data. To address both issues, we propose an Open-world Language Knowledge-Aided Robust Single-Cell Foundation Model (OKR-CELL). It is built based on a cross-modal Cell-Language pre-training framework, which comprises two key innovations: (1) leveraging Large Language Models (LLMs) based workflow with retrieval-augmented generation (RAG) enriches cell textual descriptions using open-world knowledge; (2) devising a Cross-modal Robust Alignment (CRA) objective that incorporates sample reliability assessment, curriculum learning, and coupled momentum contrastive learning to strengthen the model's resistance to noisy data. After pretraining on 32M cell-text pairs, OKR-CELL obtains cutting-edge results across 6 evaluation tasks. Beyond standard benchmarks such as cell clustering, cell-type annotation, batch-effect correction, and few-shot annotation, the model also demonstrates superior performance in broader multi-modal applications, including zero-shot cell-type annotation and bidirectional cell-text retrieval.
Fact-Checking with Large Language Models via Probabilistic Certainty and Consistency
Jan 05, 2026Large language models (LLMs) are increasingly used in applications requiring factual accuracy, yet their outputs often contain hallucinated responses. While fact-checking can mitigate these errors, existing methods typically retrieve external evidence indiscriminately, overlooking the model's internal knowledge and potentially introducing irrelevant noise. Moreover, current systems lack targeted mechanisms to resolve specific uncertainties in the model's reasoning. Inspired by how humans fact-check, we argue that LLMs should adaptively decide whether to rely on internal knowledge or initiate retrieval based on their confidence in a given claim. We introduce Probabilistic Certainty and Consistency (PCC), a framework that estimates factual confidence by jointly modeling an LLM's probabilistic certainty and reasoning consistency. These confidence signals enable an adaptive verification strategy: the model answers directly when confident, triggers targeted retrieval when uncertain or inconsistent, and escalates to deep search when ambiguity is high. Our confidence-guided routing mechanism ensures that retrieval is invoked only when necessary, improving both efficiency and reliability. Extensive experiments across three challenging benchmarks show that PCC achieves better uncertainty quantification than verbalized confidence and consistently outperforms strong LLM-based fact-checking baselines. Furthermore, we demonstrate that PCC generalizes well across various LLMs.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
CangLing-KnowFlow: A Unified Knowledge-and-Flow-fused Agent for Comprehensive Remote Sensing Applications
Dec 17, 2025The automated and intelligent processing of massive remote sensing (RS) datasets is critical in Earth observation (EO). Existing automated systems are normally task-specific, lacking a unified framework to manage diverse, end-to-end workflows--from data preprocessing to advanced interpretation--across diverse RS applications. To address this gap, this paper introduces CangLing-KnowFlow, a unified intelligent agent framework that integrates a Procedural Knowledge Base (PKB), Dynamic Workflow Adjustment, and an Evolutionary Memory Module. The PKB, comprising 1,008 expert-validated workflow cases across 162 practical RS tasks, guides planning and substantially reduces hallucinations common in general-purpose agents. During runtime failures, the Dynamic Workflow Adjustment autonomously diagnoses and replans recovery strategies, while the Evolutionary Memory Module continuously learns from these events, iteratively enhancing the agent's knowledge and performance. This synergy enables CangLing-KnowFlow to adapt, learn, and operate reliably across diverse, complex tasks. We evaluated CangLing-KnowFlow on the KnowFlow-Bench, a novel benchmark of 324 workflows inspired by real-world applications, testing its performance across 13 top Large Language Model (LLM) backbones, from open-source to commercial. Across all complex tasks, CangLing-KnowFlow surpassed the Reflexion baseline by at least 4% in Task Success Rate. As the first most comprehensive validation along this emerging field, this research demonstrates the great potential of CangLing-KnowFlow as a robust, efficient, and scalable automated solution for complex EO challenges by leveraging expert knowledge (Knowledge) into adaptive and verifiable procedures (Flow).
Towards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
A Review of Learning-Based Motion Planning: Toward a Data-Driven Optimal Control Approach
Dec 12, 2025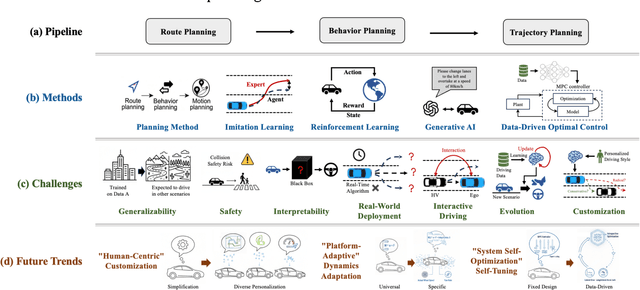
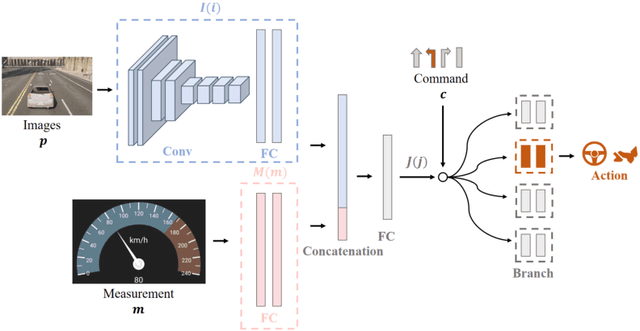
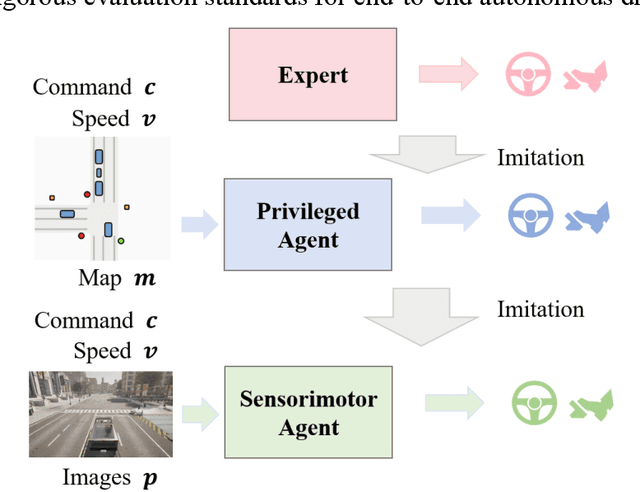
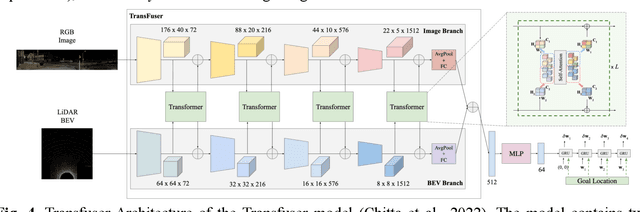
Motion planning for high-level autonomous driving is constrained by a fundamental trade-off between the transparent, yet brittle, nature of pipeline methods and the adaptive, yet opaque, "black-box" characteristics of modern learning-based systems. This paper critically synthesizes the evolution of the field -- from pipeline methods through imitation learning, reinforcement learning, and generative AI -- to demonstrate how this persistent dilemma has hindered the development of truly trustworthy systems. To resolve this impasse, we conduct a comprehensive review of learning-based motion planning methods. Based on this review, we outline a data-driven optimal control paradigm as a unifying framework that synergistically integrates the verifiable structure of classical control with the adaptive capacity of machine learning, leveraging real-world data to continuously refine key components such as system dynamics, cost functions, and safety constraints. We explore this framework's potential to enable three critical next-generation capabilities: "Human-Centric" customization, "Platform-Adaptive" dynamics adaptation, and "System Self-Optimization" via self-tuning. We conclude by proposing future research directions based on this paradigm, aimed at developing intelligent transportation systems that are simultaneously safe, interpretable, and capable of human-like autonomy.
Chat with UAV -- Human-UAV Interaction Based on Large Language Models
Dec 09, 2025The future of UAV interaction systems is evolving from engineer-driven to user-driven, aiming to replace traditional predefined Human-UAV Interaction designs. This shift focuses on enabling more personalized task planning and design, thereby achieving a higher quality of interaction experience and greater flexibility, which can be used in many fileds, such as agriculture, aerial photography, logistics, and environmental monitoring. However, due to the lack of a common language between users and the UAVs, such interactions are often difficult to be achieved. The developments of Large Language Models possess the ability to understand nature languages and Robots' (UAVs') behaviors, marking the possibility of personalized Human-UAV Interaction. Recently, some HUI frameworks based on LLMs have been proposed, but they commonly suffer from difficulties in mixed task planning and execution, leading to low adaptability in complex scenarios. In this paper, we propose a novel dual-agent HUI framework. This framework constructs two independent LLM agents (a task planning agent, and an execution agent) and applies different Prompt Engineering to separately handle the understanding, planning, and execution of tasks. To verify the effectiveness and performance of the framework, we have built a task database covering four typical application scenarios of UAVs and quantified the performance of the HUI framework using three independent metrics. Meanwhile different LLM models are selected to control the UAVs with compared performance. Our user study experimental results demonstrate that the framework improves the smoothness of HUI and the flexibility of task execution in the tasks scenario we set up, effectively meeting users' personalized needs.