 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATP-Bench: Towards Agentic Tool Planning for MLLM Interleaved Generation
Mar 31, 2026Interleaved text-and-image generation represents a significant frontier for Multimodal Large Language Models (MLLMs), offering a more intuitive way to convey complex information. Current paradigms rely on either image generation or retrieval augmentation, yet they typically treat the two as mutually exclusive paths, failing to unify factuality with creativity. We argue that the next milestone in this field is Agentic Tool Planning, where the model serves as a central controller that autonomously determines when, where, and which tools to invoke to produce interleaved responses for visual-critical queries. To systematically evaluate this paradigm, we introduce ATP-Bench, a novel benchmark comprising 7,702 QA pairs (including 1,592 VQA pairs) across eight categories and 25 visual-critical intents, featuring human-verified queries and ground truths. Furthermore, to evaluate agentic planning independent of end-to-end execution and changing tool backends, we propose a Multi-Agent MLLM-as-a-Judge (MAM) system. MAM evaluates tool-call precision, identifies missed opportunities for tool use, and assesses overall response quality without requiring ground-truth references. Our extensive experiments on 10 state-of-the-art MLLMs reveal that models struggle with coherent interleaved planning and exhibit significant variations in tool-use behavior, highlighting substantial room for improvement and providing actionable guidance for advancing interleaved generation. Dataset and code are available at https://github.com/Qwen-Applications/ATP-Bench.
MIRAGE: A Multi-modal Benchmark for Spatial Perception, Reasoning, and Intelligence
May 15, 2025Spatial perception and reasoning are core components of human cognition, encompassing object recognition, spatial relational understanding, and dynamic reasoning. Despite progress in computer vision, existing benchmarks reveal significant gaps in models' abilities to accurately recognize object attributes and reason about spatial relationships, both essential for dynamic reasoning. To address these limitations, we propose MIRAGE, a multi-modal benchmark designed to evaluate models' capabilities in Counting (object attribute recognition), Relation (spatial relational reasoning), and Counting with Relation. Through diverse and complex scenarios requiring fine-grained recognition and reasoning, MIRAGE highlights critical limitations in state-of-the-art models, underscoring the need for improved representations and reasoning frameworks. By targeting these foundational abilities, MIRAGE provides a pathway toward spatiotemporal reasoning in future research.
Balancing property optimization and constraint satisfaction for constrained multi-property molecular optimization
Nov 19, 2024



Molecular optimization, which aims to discover improved molecules from a vast chemical search space, is a critical step in chemical development. Various artificial intelligence technologies have demonstrated high effectiveness and efficiency on molecular optimization tasks. However, few of these technologies focus on balancing property optimization with constraint satisfaction, making it difficult to obtain high-quality molecules that not only possess desirable properties but also meet various constraints. To address this issue, we propose a constrained multi-property molecular optimization framework (CMOMO), which is a flexible and efficient method to simultaneously optimize multiple molecular properties while satisfying several drug-like constraints. CMOMO improves multiple properties of molecules with constraints based on dynamic cooperative optimization, which dynamically handles the constraints across various scenarios. Besides, CMOMO evaluates multiple properties within discrete chemical spaces cooperatively with the evolution of molecules within an implicit molecular space to guide the evolutionary search. Experimental results show the superior performance of the proposed CMOMO over five state-of-the-art molecular optimization methods on two benchmark tasks of simultaneously optimizing multiple non-biological activity properties while satisfying two structural constraints. Furthermore, the practical applicability of CMOMO is verified on two practical tasks, where it identified a collection of candidate ligands of $\beta$2-adrenoceptor GPCR and candidate inhibitors of glycogen synthase kinase-3$\beta$ with high properties and under drug-like constraints.
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
Aug 21, 2024Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable perceptual and reasoning abilities, typically comprising a Vision Encoder, an Adapter, and a Large Language Model (LLM). The adapter serves as the critical bridge between the visual and language components. However, training adapters with image-level supervision often results in significant misalignment, undermining the LLMs' capabilities and limiting the potential of Multimodal LLMs. To address this, we introduce Supervised Embedding Alignment (SEA), a token-level alignment method that leverages vision-language pre-trained models, such as CLIP, to align visual tokens with the LLM's embedding space through contrastive learning. This approach ensures a more coherent integration of visual and language representations, enhancing the performance and interpretability of multimodal LLMs while preserving their inherent capabilities. Extensive experiments show that SEA effectively improves MLLMs, particularly for smaller models, without adding extra data or inference computation. SEA also lays the groundwork for developing more general and adaptable solutions to enhance multimodal systems.
Physical Model Guided Deep Image Deraining
Mar 30, 2020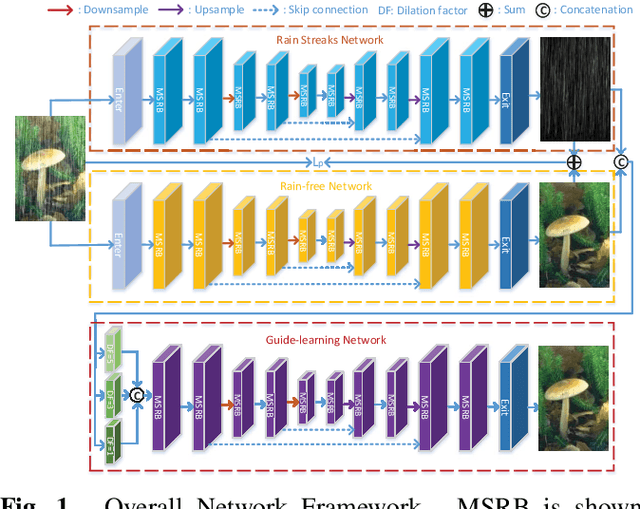
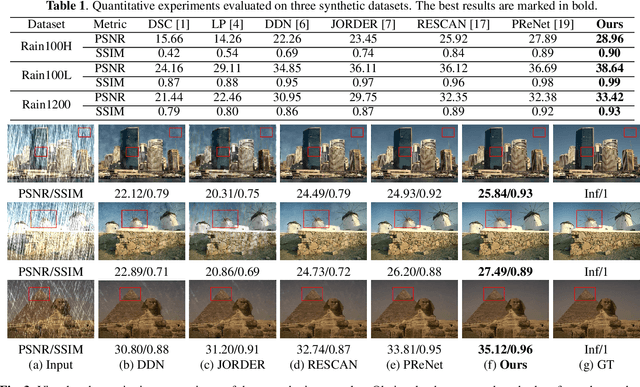
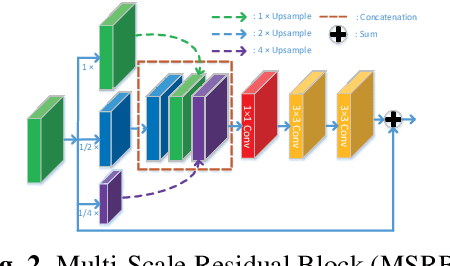
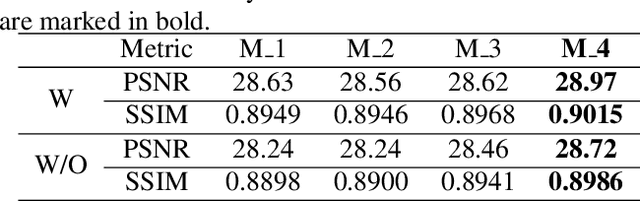
Single image deraining is an urgent task because the degraded rainy image makes many computer vision systems fail to work, such as video surveillance and autonomous driving. So, deraining becomes important and an effective deraining algorithm is needed. In this paper, we propose a novel network based on physical model guided learning for single image deraining, which consists of three sub-networks: rain streaks network, rain-free network, and guide-learning network. The concatenation of rain streaks and rain-free image that are estimated by rain streaks network, rain-free network, respectively, is input to the guide-learning network to guide further learning and the direct sum of the two estimated images is constrained with the input rainy image based on the physical model of rainy image. Moreover, we further develop the Multi-Scale Residual Block (MSRB) to better utilize multi-scale information and it is proved to boost the deraining performance. Quantitative and qualitative experimental results demonstrate that the proposed method outperforms the state-of-the-art deraining methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.