 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Mixture-of-Experts with Retrieval Augmentation for Protein Active Site Identification
Mar 02, 2026Accurate identification of protein active sites at the residue level is crucial for understanding protein function and advancing drug discovery. However, current methods face two critical challenges: vulnerability in single-instance prediction due to sparse training data, and inadequate modality reliability estimation that leads to performance degradation when unreliable modalities dominate fusion processes. To address these challenges, we introduce Multimodal Mixture-of-Experts with Retrieval Augmentation (MERA), the first retrieval-augmented framework for protein active site identification. MERA employs hierarchical multi-expert retrieval that dynamically aggregates contextual information from chain, sequence, and active-site perspectives through residue-level mixture-of-experts gating. To prevent modality degradation, we propose a reliability-aware fusion strategy based on Dempster-Shafer evidence theory that quantifies modality trustworthiness through belief mass functions and learnable discounting coefficients, enabling principled multimodal integration. Extensive experiments on ProTAD-Gen and TS125 datasets demonstrate that MERA achieves state-of-the-art performance, with 90% AUPRC on active site prediction and significant gains on peptide-binding site identification, validating the effectiveness of retrieval-augmented multi-expert modeling and reliability-guided fusion.
QuEPT: Quantized Elastic Precision Transformers with One-Shot Calibration for Multi-Bit Switching
Feb 13, 2026Elastic precision quantization enables multi-bit deployment via a single optimization pass, fitting diverse quantization scenarios.Yet, the high storage and optimization costs associated with the Transformer architecture, research on elastic quantization remains limited, particularly for large language models.This paper proposes QuEPT, an efficient post-training scheme that reconstructs block-wise multi-bit errors with one-shot calibration on a small data slice. It can dynamically adapt to various predefined bit-widths by cascading different low-rank adapters, and supports real-time switching between uniform quantization and mixed precision quantization without repeated optimization. To enhance accuracy and robustness, we introduce Multi-Bit Token Merging (MB-ToMe) to dynamically fuse token features across different bit-widths, improving robustness during bit-width switching. Additionally, we propose Multi-Bit Cascaded Low-Rank adapters (MB-CLoRA) to strengthen correlations between bit-width groups, further improve the overall performance of QuEPT. Extensive experiments demonstrate that QuEPT achieves comparable or better performance to existing state-of-the-art post-training quantization methods.Our code is available at https://github.com/xuke225/QuEPT
See, Plan, Snap: Evaluating Multimodal GUI Agents in Scratch
Feb 11, 2026Block-based programming environments such as Scratch play a central role in low-code education, yet evaluating the capabilities of AI agents to construct programs through Graphical User Interfaces (GUIs) remains underexplored. We introduce ScratchWorld, a benchmark for evaluating multimodal GUI agents on program-by-construction tasks in Scratch. Grounded in the Use-Modify-Create pedagogical framework, ScratchWorld comprises 83 curated tasks spanning four distinct problem categories: Create, Debug, Extend, and Compute. To rigorously diagnose the source of agent failures, the benchmark employs two complementary interaction modes: primitive mode requires fine-grained drag-and-drop manipulation to directly assess visuomotor control, while composite mode uses high-level semantic APIs to disentangle program reasoning from GUI execution. To ensure reliable assessment, we propose an execution-based evaluation protocol that validates the functional correctness of the constructed Scratch programs through runtime tests within the browser environment. Extensive experiments across state-of-the-art multimodal language models and GUI agents reveal a substantial reasoning--acting gap, highlighting persistent challenges in fine-grained GUI manipulation despite strong planning capabilities.
Closing the Confusion Loop: CLIP-Guided Alignment for Source-Free Domain Adaptation
Feb 09, 2026Source-Free Domain Adaptation (SFDA) tackles the problem of adapting a pre-trained source model to an unlabeled target domain without accessing any source data, which is quite suitable for the field of data security. Although recent advances have shown that pseudo-labeling strategies can be effective, they often fail in fine-grained scenarios due to subtle inter-class similarities. A critical but underexplored issue is the presence of asymmetric and dynamic class confusion, where visually similar classes are unequally and inconsistently misclassified by the source model. Existing methods typically ignore such confusion patterns, leading to noisy pseudo-labels and poor target discrimination. To address this, we propose CLIP-Guided Alignment(CGA), a novel framework that explicitly models and mitigates class confusion in SFDA. Generally, our method consists of three parts: (1) MCA: detects first directional confusion pairs by analyzing the predictions of the source model in the target domain; (2) MCC: leverages CLIP to construct confusion-aware textual prompts (e.g. a truck that looks like a bus), enabling more context-sensitive pseudo-labeling; and (3) FAM: builds confusion-guided feature banks for both CLIP and the source model and aligns them using contrastive learning to reduce ambiguity in the representation space. Extensive experiments on various datasets demonstrate that CGA consistently outperforms state-of-the-art SFDA methods, with especially notable gains in confusion-prone and fine-grained scenarios. Our results highlight the importance of explicitly modeling inter-class confusion for effective source-free adaptation. Our code can be find at https://github.com/soloiro/CGA
Trustworthy Intelligent Education: A Systematic Perspective on Progress, Challenges, and Future Directions
Jan 29, 2026In recent years, trustworthiness has garnered increasing attention and exploration in the field of intelligent education, due to the inherent sensitivity of educational scenarios, such as involving minors and vulnerable groups, highly personalized learning data, and high-stakes educational outcomes. However, existing research either focuses on task-specific trustworthy methods without a holistic view of trustworthy intelligent education, or provides survey-level discussions that remain high-level and fragmented, lacking a clear and systematic categorization. To address these limitations, in this paper, we present a systematic and structured review of trustworthy intelligent education. Specifically, We first organize intelligent education into five representative task categories: learner ability assessment, learning resource recommendation, learning analytics, educational content understanding, and instructional assistance. Building on this task landscape, we review existing studies from five trustworthiness perspectives, including safety and privacy, robustness, fairness, explainability, and sustainability, and summarize and categorize the research methodologies and solution strategies therein. Finally, we summarize key challenges and discuss future research directions. This survey aims to provide a coherent reference framework and facilitate a clearer understanding of trustworthiness in intelligent education.
Breaking Robustness Barriers in Cognitive Diagnosis: A One-Shot Neural Architecture Search Perspective
Jan 08, 2026With the advancement of network technologies, intelligent tutoring systems (ITS) have emerged to deliver increasingly precise and tailored personalized learning services. Cognitive diagnosis (CD) has emerged as a core research task in ITS, aiming to infer learners' mastery of specific knowledge concepts by modeling the mapping between learning behavior data and knowledge states. However, existing research prioritizes model performance enhancement while neglecting the pervasive noise contamination in observed response data, significantly hindering practical deployment. Furthermore, current cognitive diagnosis models (CDMs) rely heavily on researchers' domain expertise for structural design, which fails to exhaustively explore architectural possibilities, thus leaving model architectures' full potential untapped. To address this issue, we propose OSCD, an evolutionary multi-objective One-Shot neural architecture search method for Cognitive Diagnosis, designed to efficiently and robustly improve the model's capability in assessing learner proficiency. Specifically, OSCD operates through two distinct stages: training and searching. During the training stage, we construct a search space encompassing diverse architectural combinations and train a weight-sharing supernet represented via the complete binary tree topology, enabling comprehensive exploration of potential architectures beyond manual design priors. In the searching stage, we formulate the optimal architecture search under heterogeneous noise scenarios as a multi-objective optimization problem (MOP), and develop an optimization framework integrating a Pareto-optimal solution search strategy with cross-scenario performance evaluation for resolution. Extensive experiments on real-world educational datasets validate the effectiveness and robustness of the optimal architectures discovered by our OSCD model for CD tasks.
UniABG: Unified Adversarial View Bridging and Graph Correspondence for Unsupervised Cross-View Geo-Localization
Nov 15, 2025Cross-view geo-localization (CVGL) matches query images ($\textit{e.g.}$, drone) to geographically corresponding opposite-view imagery ($\textit{e.g.}$, satellite). While supervised methods achieve strong performance, their reliance on extensive pairwise annotations limits scalability. Unsupervised alternatives avoid annotation costs but suffer from noisy pseudo-labels due to intrinsic cross-view domain gaps. To address these limitations, we propose $\textit{UniABG}$, a novel dual-stage unsupervised cross-view geo-localization framework integrating adversarial view bridging with graph-based correspondence calibration. Our approach first employs View-Aware Adversarial Bridging (VAAB) to model view-invariant features and enhance pseudo-label robustness. Subsequently, Heterogeneous Graph Filtering Calibration (HGFC) refines cross-view associations by constructing dual inter-view structure graphs, achieving reliable view correspondence. Extensive experiments demonstrate state-of-the-art unsupervised performance, showing that UniABG improves Satellite $\rightarrow$ Drone AP by +10.63\% on University-1652 and +16.73\% on SUES-200, even surpassing supervised baselines. The source code is available at https://github.com/chenqi142/UniABG
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025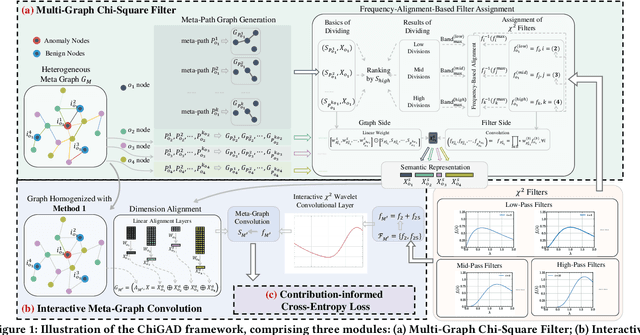
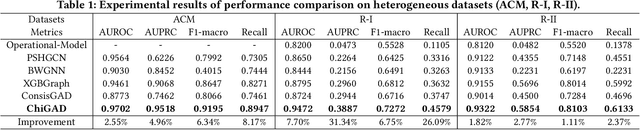
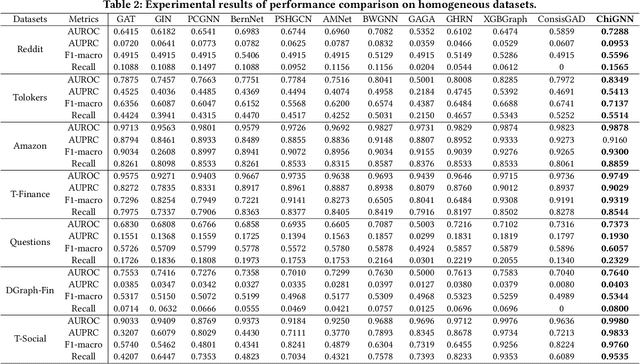
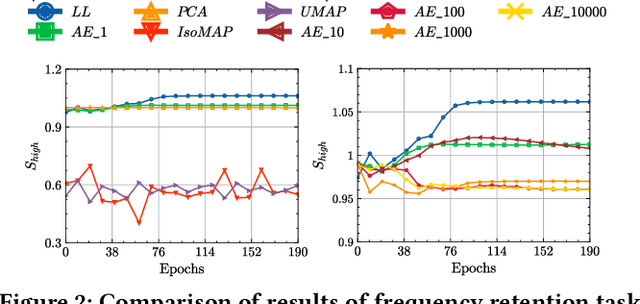
Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
SpaceGNN: Multi-Space Graph Neural Network for Node Anomaly Detection with Extremely Limited Labels
Feb 05, 2025



Node Anomaly Detection (NAD) has gained significant attention in the deep learning community due to its diverse applications in real-world scenarios. Existing NAD methods primarily embed graphs within a single Euclidean space, while overlooking the potential of non-Euclidean spaces. Besides, to address the prevalent issue of limited supervision in real NAD tasks, previous methods tend to leverage synthetic data to collect auxiliary information, which is not an effective solution as shown in our experiments. To overcome these challenges, we introduce a novel SpaceGNN model designed for NAD tasks with extremely limited labels. Specifically, we provide deeper insights into a task-relevant framework by empirically analyzing the benefits of different spaces for node representations, based on which, we design a Learnable Space Projection function that effectively encodes nodes into suitable spaces. Besides, we introduce the concept of weighted homogeneity, which we empirically and theoretically validate as an effective coefficient during information propagation. This concept inspires the design of the Distance Aware Propagation module. Furthermore, we propose the Multiple Space Ensemble module, which extracts comprehensive information for NAD under conditions of extremely limited supervision. Our findings indicate that this module is more beneficial than data augmentation techniques for NAD. Extensive experiments conducted on 9 real datasets confirm the superiority of SpaceGNN, which outperforms the best rival by an average of 8.55% in AUC and 4.31% in F1 scores. Our code is available at https://github.com/xydong127/SpaceGNN.
Learning states enhanced knowledge tracing: Simulating the diversity in real-world learning process
Dec 27, 2024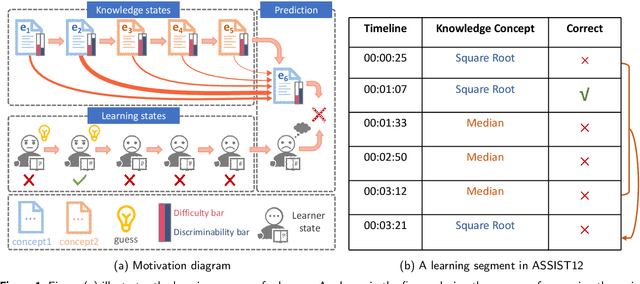
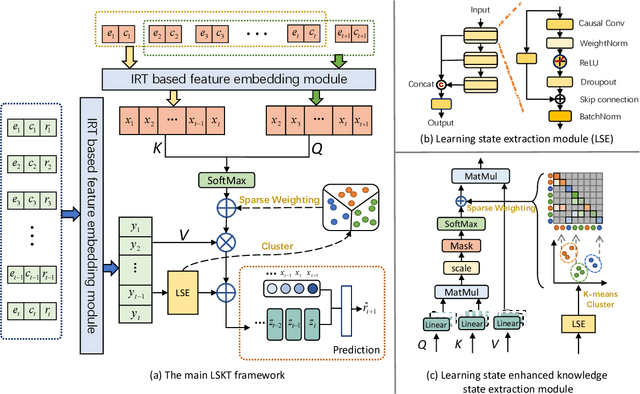
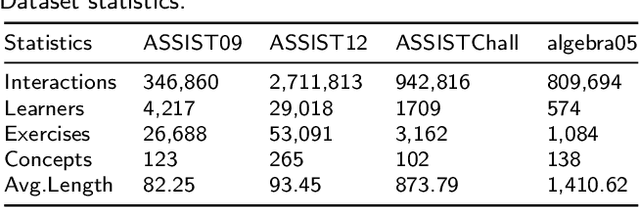
The Knowledge Tracing (KT) task focuses on predicting a learner's future performance based on the historical interactions. The knowledge state plays a key role in learning process. However, considering that the knowledge state is influenced by various learning factors in the interaction process, such as the exercises similarities, responses reliability and the learner's learning state. Previous models still face two major limitations. First, due to the exercises differences caused by various complex reasons and the unreliability of responses caused by guessing behavior, it is hard to locate the historical interaction which is most relevant to the current answered exercise. Second, the learning state is also a key factor to influence the knowledge state, which is always ignored by previous methods. To address these issues, we propose a new method named Learning State Enhanced Knowledge Tracing (LSKT). Firstly, to simulate the potential differences in interactions, inspired by Item Response Theory~(IRT) paradigm, we designed three different embedding methods ranging from coarse-grained to fine-grained views and conduct comparative analysis on them. Secondly, we design a learning state extraction module to capture the changing learning state during the learning process of the learner. In turn, with the help of the extracted learning state, a more detailed knowledge state could be captured. Experimental results on four real-world datasets show that our LSKT method outperforms the current state-of-the-art methods.