 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity or Precision? A Deep Dive into Next Token Prediction
Dec 28, 2025Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of large language models (LLMs). The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
A Survey on Text-Driven 360-Degree Panorama Generation
Feb 20, 2025



The advent of text-driven 360-degree panorama generation, enabling the synthesis of 360-degree panoramic images directly from textual descriptions, marks a transformative advancement in immersive visual content creation. This innovation significantly simplifies the traditionally complex process of producing such content. Recent progress in text-to-image diffusion models has accelerated the rapid development in this emerging field. This survey presents a comprehensive review of text-driven 360-degree panorama generation, offering an in-depth analysis of state-of-the-art algorithms and their expanding applications in 360-degree 3D scene generation. Furthermore, we critically examine current limitations and propose promising directions for future research. A curated project page with relevant resources and research papers is available at https://littlewhitesea.github.io/Text-Driven-Pano-Gen/.
Diffusion-Inspired Cold Start with Sufficient Prior in Computerized Adaptive Testing
Nov 19, 2024Computerized Adaptive Testing (CAT) aims to select the most appropriate questions based on the examinee's ability and is widely used in online education. However, existing CAT systems often lack initial understanding of the examinee's ability, requiring random probing questions. This can lead to poorly matched questions, extending the test duration and negatively impacting the examinee's mindset, a phenomenon referred to as the Cold Start with Insufficient Prior (CSIP) task. This issue occurs because CAT systems do not effectively utilize the abundant prior information about the examinee available from other courses on online platforms. These response records, due to the commonality of cognitive states across different knowledge domains, can provide valuable prior information for the target domain. However, no prior work has explored solutions for the CSIP task. In response to this gap, we propose Diffusion Cognitive States TransfeR Framework (DCSR), a novel domain transfer framework based on Diffusion Models (DMs) to address the CSIP task. Specifically, we construct a cognitive state transition bridge between domains, guided by the common cognitive states of examinees, encouraging the model to reconstruct the initial ability state in the target domain. To enrich the expressive power of the generated data, we analyze the causal relationships in the generation process from a causal perspective. Redundant and extraneous cognitive states can lead to limited transfer and negative transfer effects. Our DCSR can seamlessly apply the generated initial ability states in the target domain to existing question selection algorithms, thus improving the cold start performance of the CAT system. Extensive experiments conducted on five real-world datasets demonstrate that DCSR significantly outperforms existing baseline methods in addressing the CSIP task.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Knowledge Graph Enhanced Language Agents for Recommendation
Oct 25, 2024



Language agents have recently been used to simulate human behavior and user-item interactions for recommendation systems. However, current language agent simulations do not understand the relationships between users and items, leading to inaccurate user profiles and ineffective recommendations. In this work, we explore the utility of Knowledge Graphs (KGs), which contain extensive and reliable relationships between users and items, for recommendation. Our key insight is that the paths in a KG can capture complex relationships between users and items, eliciting the underlying reasons for user preferences and enriching user profiles. Leveraging this insight, we propose Knowledge Graph Enhanced Language Agents(KGLA), a framework that unifies language agents and KG for recommendation systems. In the simulated recommendation scenario, we position the user and item within the KG and integrate KG paths as natural language descriptions into the simulation. This allows language agents to interact with each other and discover sufficient rationale behind their interactions, making the simulation more accurate and aligned with real-world cases, thus improving recommendation performance. Our experimental results show that KGLA significantly improves recommendation performance (with a 33%-95% boost in NDCG@1 among three widely used benchmarks) compared to the previous best baseline method.
360PanT: Training-Free Text-Driven 360-Degree Panorama-to-Panorama Translation
Sep 12, 2024



Preserving boundary continuity in the translation of 360-degree panoramas remains a significant challenge for existing text-driven image-to-image translation methods. These methods often produce visually jarring discontinuities at the translated panorama's boundaries, disrupting the immersive experience. To address this issue, we propose 360PanT, a training-free approach to text-based 360-degree panorama-to-panorama translation with boundary continuity. Our 360PanT achieves seamless translations through two key components: boundary continuity encoding and seamless tiling translation with spatial control. Firstly, the boundary continuity encoding embeds critical boundary continuity information of the input 360-degree panorama into the noisy latent representation by constructing an extended input image. Secondly, leveraging this embedded noisy latent representation and guided by a target prompt, the seamless tiling translation with spatial control enables the generation of a translated image with identical left and right halves while adhering to the extended input's structure and semantic layout. This process ensures a final translated 360-degree panorama with seamless boundary continuity. Experimental results on both real-world and synthesized datasets demonstrate the effectiveness of our 360PanT in translating 360-degree panoramas. Code is available at \href{https://github.com/littlewhitesea/360PanT}{https://github.com/littlewhitesea/360PanT}.
TrajWeaver: Trajectory Recovery with State Propagation Diffusion Model
Sep 01, 2024



With the proliferation of location-aware devices, large amount of trajectories have been generated when agents such as people, vehicles and goods flow around the urban environment. These raw trajectories, typically collected from various sources such as GPS in cars, personal mobile devices, and public transport, are often sparse and fragmented due to limited sampling rates, infrastructure coverage and data loss. In this context, trajectory recovery aims to reconstruct such sparse raw trajectories into their dense and continuous counterparts, so that fine-grained movement of agents across space and time can be captured faithfully. Existing trajectory recovery approaches typically rely on the prior knowledge of travel mode or motion patterns, and often fail in densely populated urban areas where accurate maps are absent. In this paper, we present a new recovery framework called TrajWeaver based on probabilistic diffusion models, which is able to recover dense and refined trajectories from the sparse raw ones, conditioned on various auxiliary features such as Areas of Interest along the way, user identity and waybill information. The core of TrajWeaver is a novel State Propagation Diffusion Model (SPDM), which introduces a new state propagation mechanism on top of the standard diffusion models, so that knowledge computed in earlier diffusion steps can be reused later, improving the recovery performance while reducing the number of steps needed. Extensive experiments show that the proposed TrajWeaver can recover from raw trajectories of various lengths, sparsity levels and heterogeneous travel modes, and outperform the state-of-the-art baselines significantly in recovery accuracy. Our code is available at: https://anonymous.4open.science/r/TrajWeaver/
Multimodal Gen-AI for Fundamental Investment Research
Dec 24, 2023This report outlines a transformative initiative in the financial investment industry, where the conventional decision-making process, laden with labor-intensive tasks such as sifting through voluminous documents, is being reimagined. Leveraging language models, our experiments aim to automate information summarization and investment idea generation. We seek to evaluate the effectiveness of fine-tuning methods on a base model (Llama2) to achieve specific application-level goals, including providing insights into the impact of events on companies and sectors, understanding market condition relationships, generating investor-aligned investment ideas, and formatting results with stock recommendations and detailed explanations. Through state-of-the-art generative modeling techniques, the ultimate objective is to develop an AI agent prototype, liberating human investors from repetitive tasks and allowing a focus on high-level strategic thinking. The project encompasses a diverse corpus dataset, including research reports, investment memos, market news, and extensive time-series market data. We conducted three experiments applying unsupervised and supervised LoRA fine-tuning on the llama2_7b_hf_chat as the base model, as well as instruction fine-tuning on the GPT3.5 model. Statistical and human evaluations both show that the fine-tuned versions perform better in solving text modeling, summarization, reasoning, and finance domain questions, demonstrating a pivotal step towards enhancing decision-making processes in the financial domain. Code implementation for the project can be found on GitHub: https://github.com/Firenze11/finance_lm.
Customizing 360-Degree Panoramas through Text-to-Image Diffusion Models
Nov 07, 2023


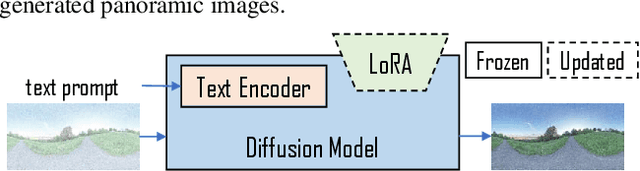
Personalized text-to-image (T2I) synthesis based on diffusion models has attracted significant attention in recent research. However, existing methods primarily concentrate on customizing subjects or styles, neglecting the exploration of global geometry. In this study, we propose an approach that focuses on the customization of 360-degree panoramas, which inherently possess global geometric properties, using a T2I diffusion model. To achieve this, we curate a paired image-text dataset specifically designed for the task and subsequently employ it to fine-tune a pre-trained T2I diffusion model with LoRA. Nevertheless, the fine-tuned model alone does not ensure the continuity between the leftmost and rightmost sides of the synthesized images, a crucial characteristic of 360-degree panoramas. To address this issue, we propose a method called StitchDiffusion. Specifically, we perform pre-denoising operations twice at each time step of the denoising process on the stitch block consisting of the leftmost and rightmost image regions. Furthermore, a global cropping is adopted to synthesize seamless 360-degree panoramas. Experimental results demonstrate the effectiveness of our customized model combined with the proposed StitchDiffusion in generating high-quality 360-degree panoramic images. Moreover, our customized model exhibits exceptional generalization ability in producing scenes unseen in the fine-tuning dataset. Code is available at https://github.com/littlewhitesea/StitchDiffusion.