 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Enhanced Language Agents for Recommendation
Oct 25, 2024



Language agents have recently been used to simulate human behavior and user-item interactions for recommendation systems. However, current language agent simulations do not understand the relationships between users and items, leading to inaccurate user profiles and ineffective recommendations. In this work, we explore the utility of Knowledge Graphs (KGs), which contain extensive and reliable relationships between users and items, for recommendation. Our key insight is that the paths in a KG can capture complex relationships between users and items, eliciting the underlying reasons for user preferences and enriching user profiles. Leveraging this insight, we propose Knowledge Graph Enhanced Language Agents(KGLA), a framework that unifies language agents and KG for recommendation systems. In the simulated recommendation scenario, we position the user and item within the KG and integrate KG paths as natural language descriptions into the simulation. This allows language agents to interact with each other and discover sufficient rationale behind their interactions, making the simulation more accurate and aligned with real-world cases, thus improving recommendation performance. Our experimental results show that KGLA significantly improves recommendation performance (with a 33%-95% boost in NDCG@1 among three widely used benchmarks) compared to the previous best baseline method.
Transformer-based Conditional Variational Autoencoder for Controllable Story Generation
Jan 04, 2021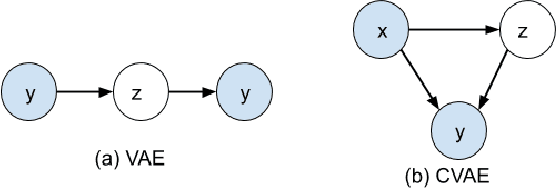


We investigate large-scale latent variable models (LVMs) for neural story generation -- an under-explored application for open-domain long text -- with objectives in two threads: generation effectiveness and controllability. LVMs, especially the variational autoencoder (VAE), have achieved both effective and controllable generation through exploiting flexible distributional latent representations. Recently, Transformers and its variants have achieved remarkable effectiveness without explicit latent representation learning, thus lack satisfying controllability in generation. In this paper, we advocate to revive latent variable modeling, essentially the power of representation learning, in the era of Transformers to enhance controllability without hurting state-of-the-art generation effectiveness. Specifically, we integrate latent representation vectors with a Transformer-based pre-trained architecture to build conditional variational autoencoder (CVAE). Model components such as encoder, decoder and the variational posterior are all built on top of pre-trained language models -- GPT2 specifically in this paper. Experiments demonstrate state-of-the-art conditional generation ability of our model, as well as its excellent representation learning capability and controllability.
Outline to Story: Fine-grained Controllable Story Generation from Cascaded Events
Jan 04, 2021



Large-scale pretrained language models have shown thrilling generation capabilities, especially when they generate consistent long text in thousands of words with ease. However, users of these models can only control the prefix of sentences or certain global aspects of generated text. It is challenging to simultaneously achieve fine-grained controllability and preserve the state-of-the-art unconditional text generation capability. In this paper, we first propose a new task named "Outline to Story" (O2S) as a test bed for fine-grained controllable generation of long text, which generates a multi-paragraph story from cascaded events, i.e. a sequence of outline events that guide subsequent paragraph generation. We then create dedicate datasets for future benchmarks, built by state-of-the-art keyword extraction techniques. Finally, we propose an extremely simple yet strong baseline method for the O2S task, which fine tunes pre-trained language models on augmented sequences of outline-story pairs with simple language modeling objective. Our method does not introduce any new parameters or perform any architecture modification, except several special tokens as delimiters to build augmented sequences. Extensive experiments on various datasets demonstrate state-of-the-art conditional story generation performance with our model, achieving better fine-grained controllability and user flexibility. Our paper is among the first ones by our knowledge to propose a model and to create datasets for the task of "outline to story". Our work also instantiates research interest of fine-grained controllable generation of open-domain long text, where controlling inputs are represented by short text.
DeepLung: Deep 3D Dual Path Nets for Automated Pulmonary Nodule Detection and Classification
Jan 25, 2018

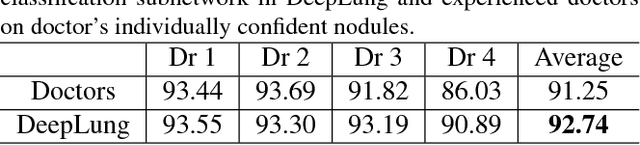
In this work, we present a fully automated lung computed tomography (CT) cancer diagnosis system, DeepLung. DeepLung consists of two components, nodule detection (identifying the locations of candidate nodules) and classification (classifying candidate nodules into benign or malignant). Considering the 3D nature of lung CT data and the compactness of dual path networks (DPN), two deep 3D DPN are designed for nodule detection and classification respectively. Specifically, a 3D Faster Regions with Convolutional Neural Net (R-CNN) is designed for nodule detection with 3D dual path blocks and a U-net-like encoder-decoder structure to effectively learn nodule features. For nodule classification, gradient boosting machine (GBM) with 3D dual path network features is proposed. The nodule classification subnetwork was validated on a public dataset from LIDC-IDRI, on which it achieved better performance than state-of-the-art approaches and surpassed the performance of experienced doctors based on image modality. Within the DeepLung system, candidate nodules are detected first by the nodule detection subnetwork, and nodule diagnosis is conducted by the classification subnetwork. Extensive experimental results demonstrate that DeepLung has performance comparable to experienced doctors both for the nodule-level and patient-level diagnosis on the LIDC-IDRI dataset.\footnote{https://github.com/uci-cbcl/DeepLung.git}
DeepLung: 3D Deep Convolutional Nets for Automated Pulmonary Nodule Detection and Classification
Sep 16, 2017

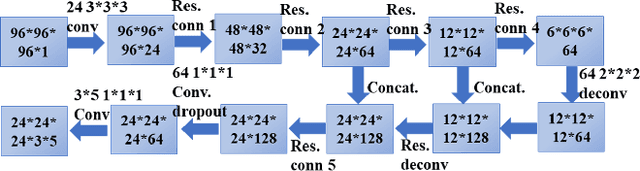

In this work, we present a fully automated lung CT cancer diagnosis system, DeepLung. DeepLung contains two parts, nodule detection and classification. Considering the 3D nature of lung CT data, two 3D networks are designed for the nodule detection and classification respectively. Specifically, a 3D Faster R-CNN is designed for nodule detection with a U-net-like encoder-decoder structure to effectively learn nodule features. For nodule classification, gradient boosting machine (GBM) with 3D dual path network (DPN) features is proposed. The nodule classification subnetwork is validated on a public dataset from LIDC-IDRI, on which it achieves better performance than state-of-the-art approaches, and surpasses the average performance of four experienced doctors. For the DeepLung system, candidate nodules are detected first by the nodule detection subnetwork, and nodule diagnosis is conducted by the classification subnetwork. Extensive experimental results demonstrate the DeepLung is comparable to the experienced doctors both for the nodule-level and patient-level diagnosis on the LIDC-IDRI dataset.