 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Polarized Material Cues for Robust Car Detection
Jan 05, 2024



Car detection is an important task that serves as a crucial prerequisite for many automated driving functions. The large variations in lighting/weather conditions and vehicle densities of the scenes pose significant challenges to existing car detection algorithms to meet the highly accurate perception demand for safety, due to the unstable/limited color information, which impedes the extraction of meaningful/discriminative features of cars. In this work, we present a novel learning-based car detection method that leverages trichromatic linear polarization as an additional cue to disambiguate such challenging cases. A key observation is that polarization, characteristic of the light wave, can robustly describe intrinsic physical properties of the scene objects in various imaging conditions and is strongly linked to the nature of materials for cars (e.g., metal and glass) and their surrounding environment (e.g., soil and trees), thereby providing reliable and discriminative features for robust car detection in challenging scenes. To exploit polarization cues, we first construct a pixel-aligned RGB-Polarization car detection dataset, which we subsequently employ to train a novel multimodal fusion network. Our car detection network dynamically integrates RGB and polarization features in a request-and-complement manner and can explore the intrinsic material properties of cars across all learning samples. We extensively validate our method and demonstrate that it outperforms state-of-the-art detection methods. Experimental results show that polarization is a powerful cue for car detection.
Progressive Glass Segmentation
Sep 06, 2022



Glass is very common in the real world. Influenced by the uncertainty about the glass region and the varying complex scenes behind the glass, the existence of glass poses severe challenges to many computer vision tasks, making glass segmentation as an important computer vision task. Glass does not have its own visual appearances but only transmit/reflect the appearances of its surroundings, making it fundamentally different from other common objects. To address such a challenging task, existing methods typically explore and combine useful cues from different levels of features in the deep network. As there exists a characteristic gap between level-different features, i.e., deep layer features embed more high-level semantics and are better at locating the target objects while shallow layer features have larger spatial sizes and keep richer and more detailed low-level information, fusing these features naively thus would lead to a sub-optimal solution. In this paper, we approach the effective features fusion towards accurate glass segmentation in two steps. First, we attempt to bridge the characteristic gap between different levels of features by developing a Discriminability Enhancement (DE) module which enables level-specific features to be a more discriminative representation, alleviating the features incompatibility for fusion. Second, we design a Focus-and-Exploration Based Fusion (FEBF) module to richly excavate useful information in the fusion process by highlighting the common and exploring the difference between level-different features.
Learning Individual Interactions from Population Dynamics with Discrete-Event Simulation Model
May 04, 2022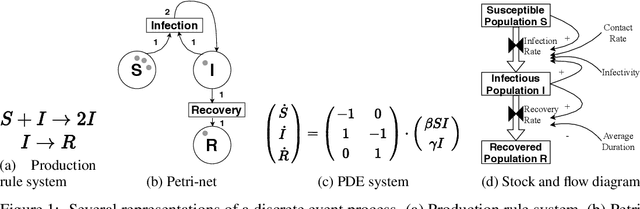
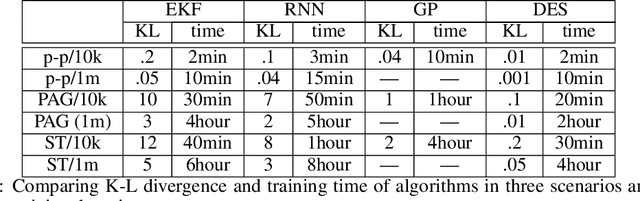

The abundance of data affords researchers to pursue more powerful computational tools to learn the dynamics of complex system, such as neural networks, engineered systems and social networks. Traditional machine learning approaches capture complex system dynamics either with dynamic Bayesian networks and state space models, which is hard to scale because it is non-trivial to prescribe the dynamics with a sparse graph or a system of differential equations; or a deep neural networks, where the distributed representation of the learned dynamics is hard to interpret. In this paper, we will explore the possibility of learning a discrete-event simulation representation of complex system dynamics assuming multivariate normal distribution of the state variables, based on the observation that many complex system dynamics can be decomposed into a sequence of local interactions, which individually change the system state only minimally but in sequence generate complex and diverse dynamics. Our results show that the algorithm can data-efficiently capture complex network dynamics in several fields with meaningful events.
TDM: Trustworthy Decision-Making via Interpretability Enhancement
Aug 13, 2021

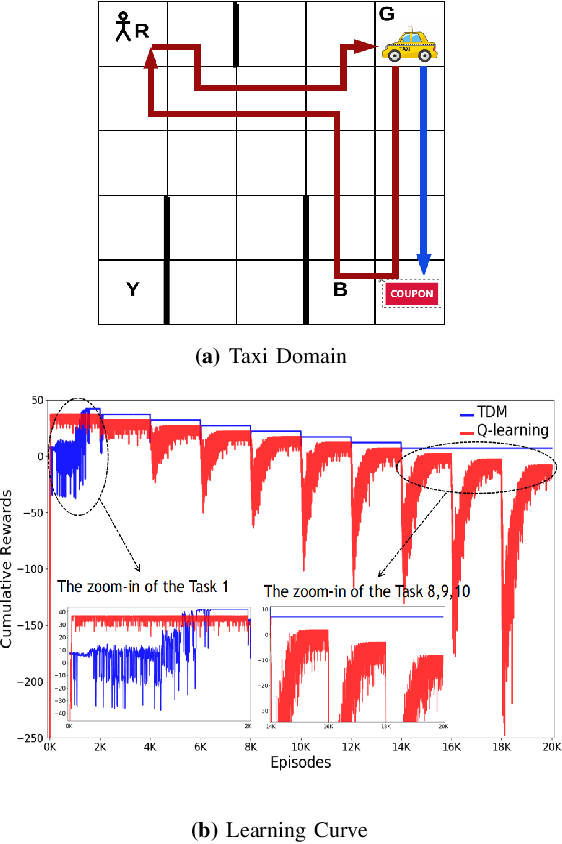

Human-robot interactive decision-making is increasingly becoming ubiquitous, and trust is an influential factor in determining the reliance on autonomy. However, it is not reasonable to trust systems that are beyond our comprehension, and typical machine learning and data-driven decision-making are black-box paradigms that impede interpretability. Therefore, it is critical to establish computational trustworthy decision-making mechanisms enhanced by interpretability-aware strategies. To this end, we propose a Trustworthy Decision-Making (TDM) framework, which integrates symbolic planning into sequential decision-making. The framework learns interpretable subtasks that result in a complex, higher-level composite task that can be formally evaluated using the proposed trust metric. TDM enables the subtask-level interpretability by design and converges to an optimal symbolic plan from the learned subtasks. Moreover, a TDM-based algorithm is introduced to demonstrate the unification of symbolic planning with other sequential-decision making algorithms, reaping the benefits of both. Experimental results validate the effectiveness of trust-score-based planning while improving the interpretability of subtasks.
Transformer-based Conditional Variational Autoencoder for Controllable Story Generation
Jan 04, 2021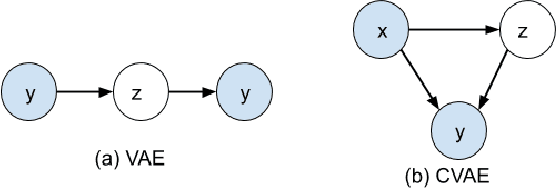


We investigate large-scale latent variable models (LVMs) for neural story generation -- an under-explored application for open-domain long text -- with objectives in two threads: generation effectiveness and controllability. LVMs, especially the variational autoencoder (VAE), have achieved both effective and controllable generation through exploiting flexible distributional latent representations. Recently, Transformers and its variants have achieved remarkable effectiveness without explicit latent representation learning, thus lack satisfying controllability in generation. In this paper, we advocate to revive latent variable modeling, essentially the power of representation learning, in the era of Transformers to enhance controllability without hurting state-of-the-art generation effectiveness. Specifically, we integrate latent representation vectors with a Transformer-based pre-trained architecture to build conditional variational autoencoder (CVAE). Model components such as encoder, decoder and the variational posterior are all built on top of pre-trained language models -- GPT2 specifically in this paper. Experiments demonstrate state-of-the-art conditional generation ability of our model, as well as its excellent representation learning capability and controllability.
Outline to Story: Fine-grained Controllable Story Generation from Cascaded Events
Jan 04, 2021



Large-scale pretrained language models have shown thrilling generation capabilities, especially when they generate consistent long text in thousands of words with ease. However, users of these models can only control the prefix of sentences or certain global aspects of generated text. It is challenging to simultaneously achieve fine-grained controllability and preserve the state-of-the-art unconditional text generation capability. In this paper, we first propose a new task named "Outline to Story" (O2S) as a test bed for fine-grained controllable generation of long text, which generates a multi-paragraph story from cascaded events, i.e. a sequence of outline events that guide subsequent paragraph generation. We then create dedicate datasets for future benchmarks, built by state-of-the-art keyword extraction techniques. Finally, we propose an extremely simple yet strong baseline method for the O2S task, which fine tunes pre-trained language models on augmented sequences of outline-story pairs with simple language modeling objective. Our method does not introduce any new parameters or perform any architecture modification, except several special tokens as delimiters to build augmented sequences. Extensive experiments on various datasets demonstrate state-of-the-art conditional story generation performance with our model, achieving better fine-grained controllability and user flexibility. Our paper is among the first ones by our knowledge to propose a model and to create datasets for the task of "outline to story". Our work also instantiates research interest of fine-grained controllable generation of open-domain long text, where controlling inputs are represented by short text.
Stable and Efficient Policy Evaluation
Jun 06, 2020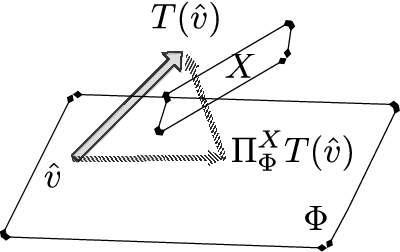
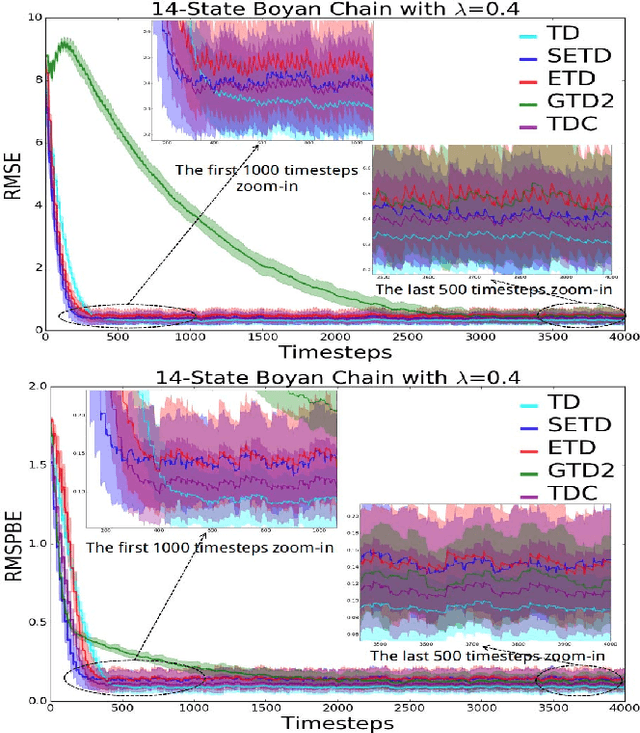
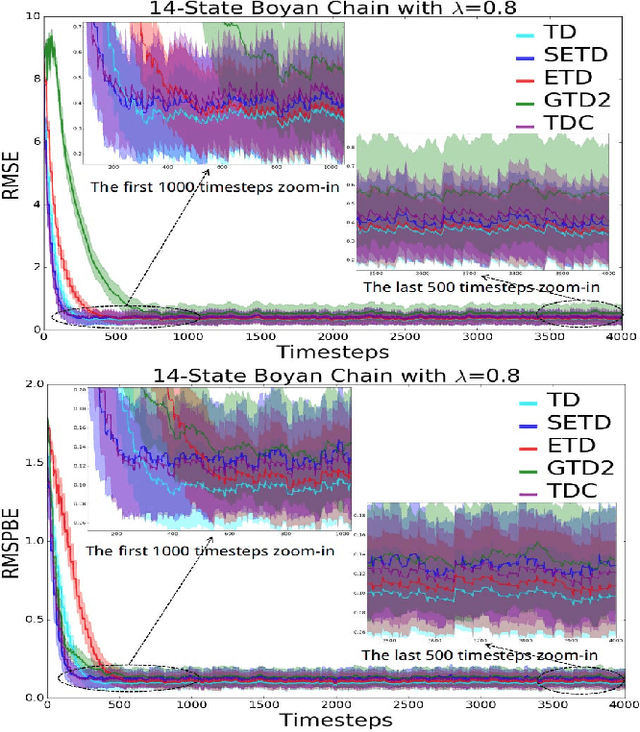
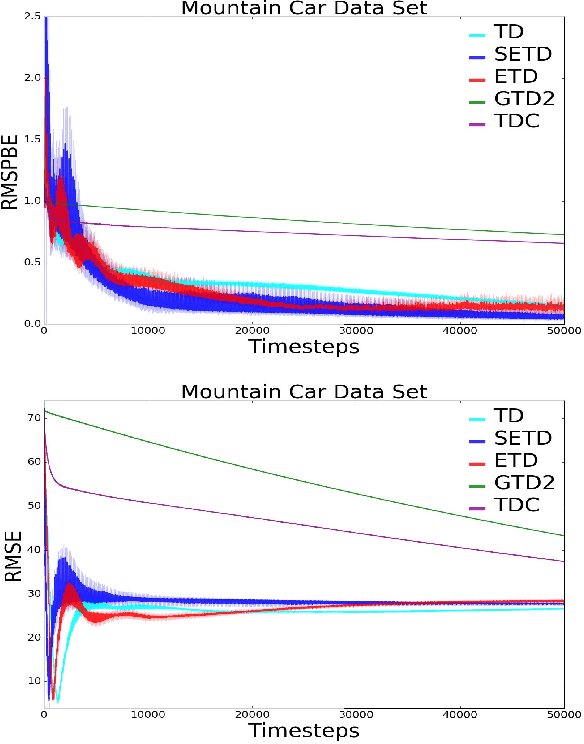
Policy evaluation algorithms are essential to reinforcement learning due to their ability to predict the performance of a policy. However, there are two long-standing issues lying in this prediction problem that need to be tackled: off-policy stability and on-policy efficiency. The conventional temporal difference (TD) algorithm is known to perform very well in the on-policy setting, yet is not off-policy stable. On the other hand, the gradient TD and emphatic TD algorithms are off-policy stable, but are not on-policy efficient. This paper introduces novel algorithms that are both off-policy stable and on-policy efficient by using the oblique projection method. The empirical experimental results on various domains validate the effectiveness of the proposed approach.
Unsupervised Community Detection with a Potts Model Hamiltonian, an Efficient Algorithmic Solution, and Applications in Digital Pathology
Feb 05, 2020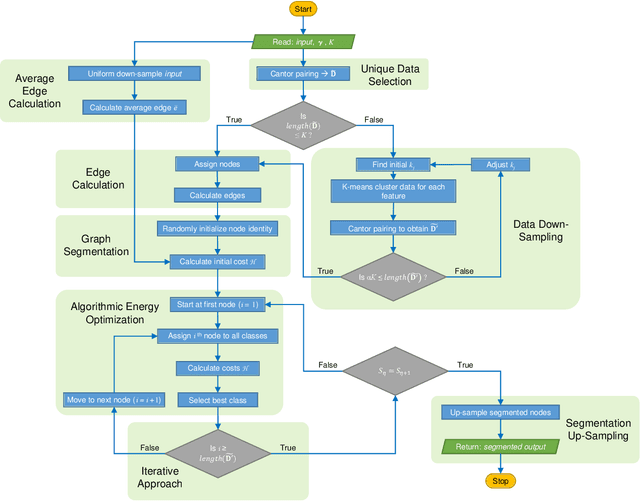
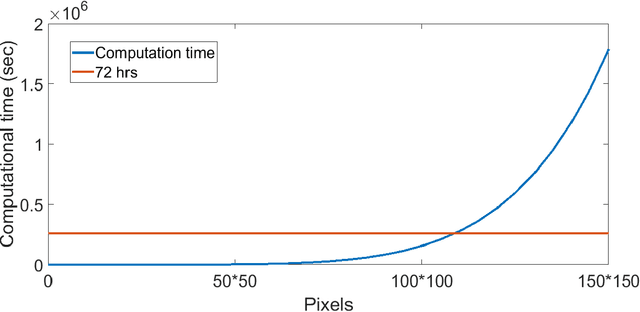
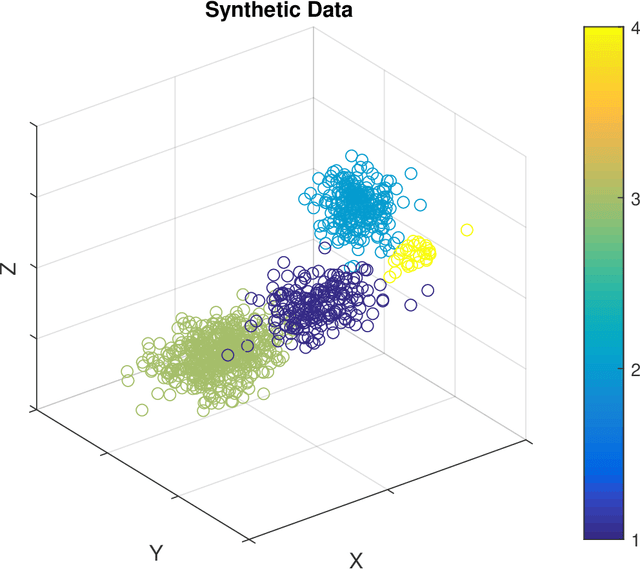
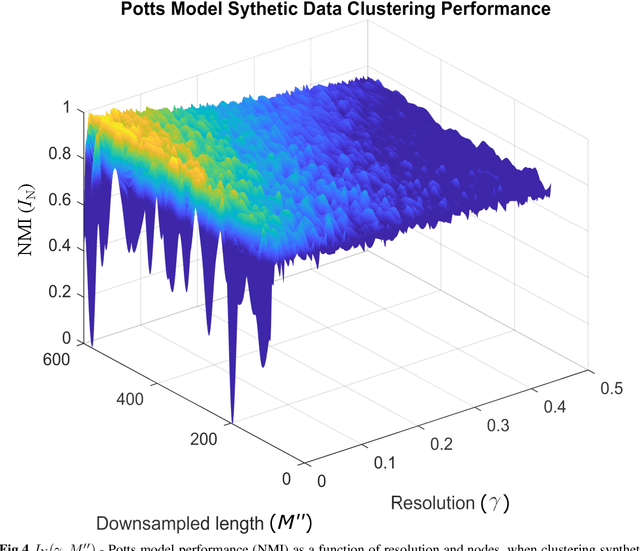
Unsupervised segmentation of large images using a Potts model Hamiltonian is unique in that segmentation is governed by a resolution parameter which scales the sensitivity to small clusters. Here, the input image is first modeled as a graph, which is then segmented by minimizing a Hamiltonian cost function defined on the graph and the respective segments. However, there exists no closed form solution of this optimization, and using previous iterative algorithmic solution techniques, the problem scales quadratically in the Input Length. Therefore, while Potts model segmentation gives accurate segmentation, it is grossly underutilized as an unsupervised learning technique. We propose a fast statistical down-sampling of input image pixels based on the respective color features, and a new iterative method to minimize the Potts model energy considering pixel to segment relationship. This method is generalizable and can be extended for image pixel texture features as well as spatial features. We demonstrate that this new method is highly efficient, and outperforms existing methods for Potts model based image segmentation. We demonstrate the application of our method in medical microscopy image segmentation; particularly, in segmenting renal glomerular micro-environment in renal pathology. Our method is not limited to image segmentation, and can be extended to any image/data segmentation/clustering task for arbitrary datasets with discrete features.
Implicit Deep Latent Variable Models for Text Generation
Sep 18, 2019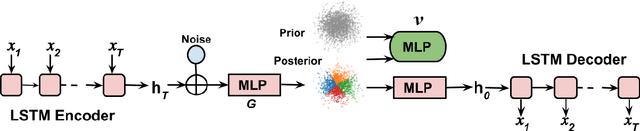

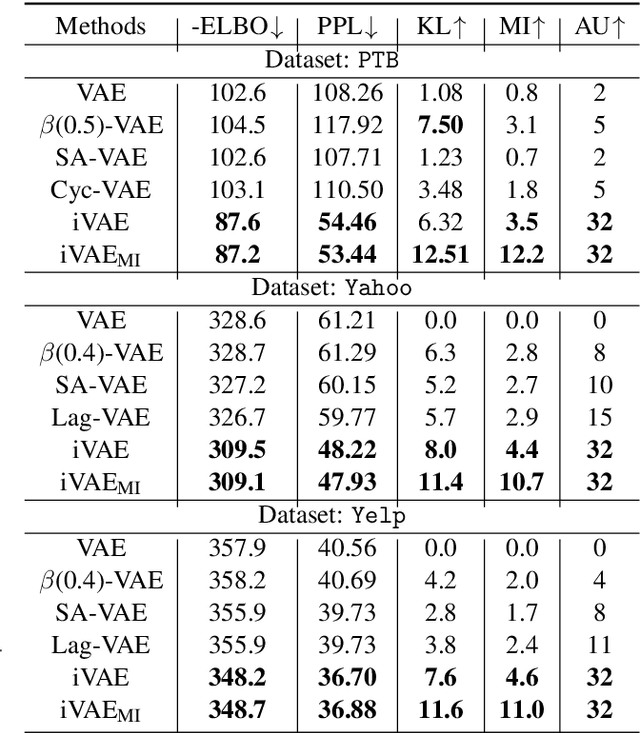

Deep latent variable models (LVM) such as variational auto-encoder (VAE) have recently played an important role in text generation. One key factor is the exploitation of smooth latent structures to guide the generation. However, the representation power of VAEs is limited due to two reasons: (1) the Gaussian assumption is often made on the variational posteriors; and meanwhile (2) a notorious "posterior collapse" issue occurs. In this paper, we advocate sample-based representations of variational distributions for natural language, leading to implicit latent features, which can provide flexible representation power compared with Gaussian-based posteriors. We further develop an LVM to directly match the aggregated posterior to the prior. It can be viewed as a natural extension of VAEs with a regularization of maximizing mutual information, mitigating the "posterior collapse" issue. We demonstrate the effectiveness and versatility of our models in various text generation scenarios, including language modeling, unaligned style transfer, and dialog response generation. The source code to reproduce our experimental results is available on GitHub.
PocketCare: Tracking the Flu with Mobile Phones using Partial Observations of Proximity and Symptoms
May 07, 2019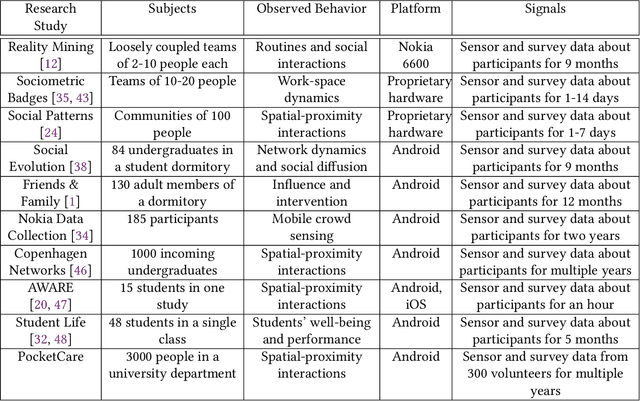
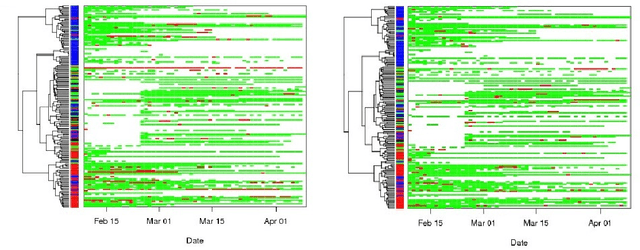
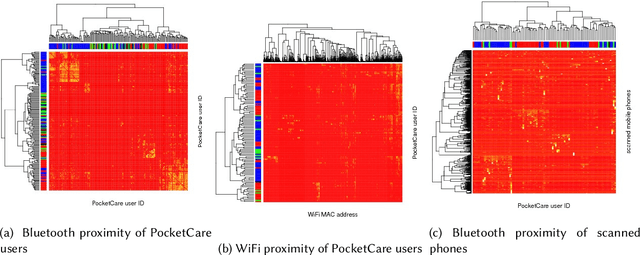
Mobile phones provide a powerful sensing platform that researchers may adopt to understand proximity interactions among people and the diffusion, through these interactions, of diseases, behaviors, and opinions. However, it remains a challenge to track the proximity-based interactions of a whole community and then model the social diffusion of diseases and behaviors starting from the observations of a small fraction of the volunteer population. In this paper, we propose a novel approach that tries to connect together these sparse observations using a model of how individuals interact with each other and how social interactions happen in terms of a sequence of proximity interactions. We apply our approach to track the spreading of flu in the spatial-proximity network of a 3000-people university campus by mobilizing 300 volunteers from this population to monitor nearby mobile phones through Bluetooth scanning and to daily report flu symptoms about and around them. Our aim is to predict the likelihood for an individual to get flu based on how often her/his daily routine intersects with those of the volunteers. Thus, we use the daily routines of the volunteers to build a model of the volunteers as well as of the non-volunteers. Our results show that we can predict flu infection two weeks ahead of time with an average precision from 0.24 to 0.35 depending on the amount of information. This precision is six to nine times higher than with a random guess model. At the population level, we can predict infectious population in a two-week window with an r-squared value of 0.95 (a random-guess model obtains an r-squared value of 0.2). These results point to an innovative approach for tracking individuals who have interacted with people showing symptoms, allowing us to warn those in danger of infection and to inform health researchers about the progression of contact-induced diseases.