 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Defer in Non-Stationary Time Series via Switching State-Space Models
Jan 30, 2026We study Learning to Defer for non-stationary time series with partial feedback and time-varying expert availability. At each time step, the router selects an available expert, observes the target, and sees only the queried expert's prediction. We model signed expert residuals using L2D-SLDS, a factorized switching linear-Gaussian state-space model with context-dependent regime transitions, a shared global factor enabling cross-expert information transfer, and per-expert idiosyncratic states. The model supports expert entry and pruning via a dynamic registry. Using one-step-ahead predictive beliefs, we propose an IDS-inspired routing rule that trades off predicted cost against information gained about the latent regime and shared factor. Experiments show improvements over contextual-bandit baselines and a no-shared-factor ablation.
Large-Field Contextual Feature Learning for Glass Detection
Sep 10, 2022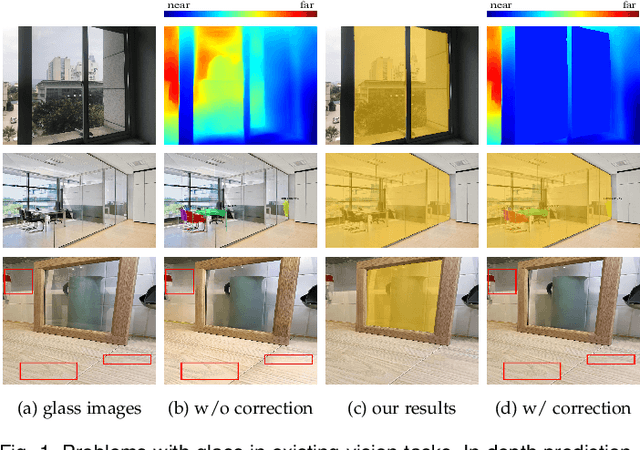
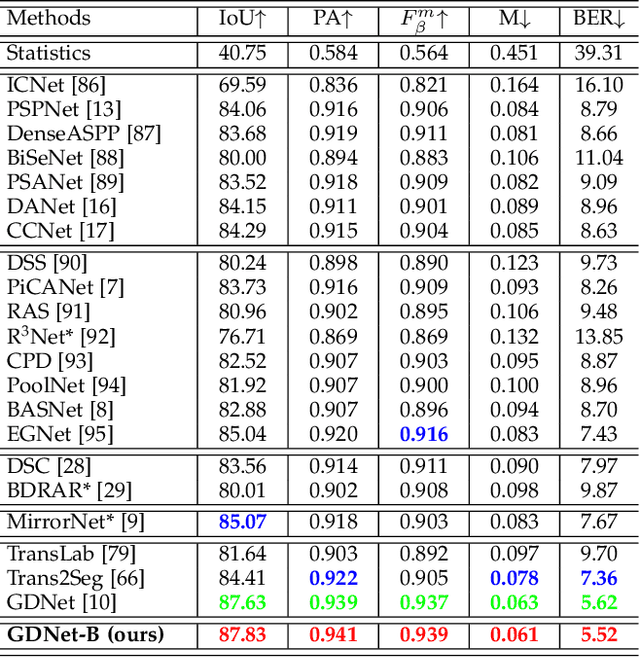

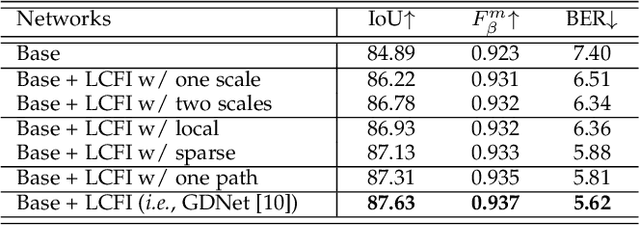
Glass is very common in our daily life. Existing computer vision systems neglect it and thus may have severe consequences, e.g., a robot may crash into a glass wall. However, sensing the presence of glass is not straightforward. The key challenge is that arbitrary objects/scenes can appear behind the glass. In this paper, we propose an important problem of detecting glass surfaces from a single RGB image. To address this problem, we construct the first large-scale glass detection dataset (GDD) and propose a novel glass detection network, called GDNet-B, which explores abundant contextual cues in a large field-of-view via a novel large-field contextual feature integration (LCFI) module and integrates both high-level and low-level boundary features with a boundary feature enhancement (BFE) module. Extensive experiments demonstrate that our GDNet-B achieves satisfying glass detection results on the images within and beyond the GDD testing set. We further validate the effectiveness and generalization capability of our proposed GDNet-B by applying it to other vision tasks, including mirror segmentation and salient object detection. Finally, we show the potential applications of glass detection and discuss possible future research directions.
Progressive Glass Segmentation
Sep 06, 2022



Glass is very common in the real world. Influenced by the uncertainty about the glass region and the varying complex scenes behind the glass, the existence of glass poses severe challenges to many computer vision tasks, making glass segmentation as an important computer vision task. Glass does not have its own visual appearances but only transmit/reflect the appearances of its surroundings, making it fundamentally different from other common objects. To address such a challenging task, existing methods typically explore and combine useful cues from different levels of features in the deep network. As there exists a characteristic gap between level-different features, i.e., deep layer features embed more high-level semantics and are better at locating the target objects while shallow layer features have larger spatial sizes and keep richer and more detailed low-level information, fusing these features naively thus would lead to a sub-optimal solution. In this paper, we approach the effective features fusion towards accurate glass segmentation in two steps. First, we attempt to bridge the characteristic gap between different levels of features by developing a Discriminability Enhancement (DE) module which enables level-specific features to be a more discriminative representation, alleviating the features incompatibility for fusion. Second, we design a Focus-and-Exploration Based Fusion (FEBF) module to richly excavate useful information in the fusion process by highlighting the common and exploring the difference between level-different features.
Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
Jan 26, 2021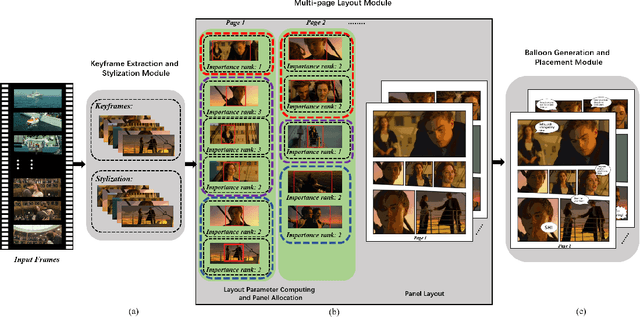
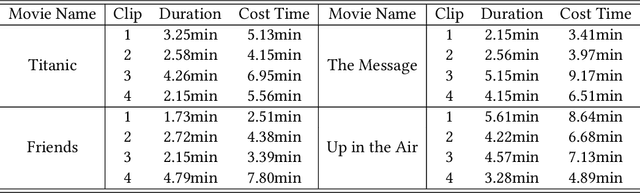
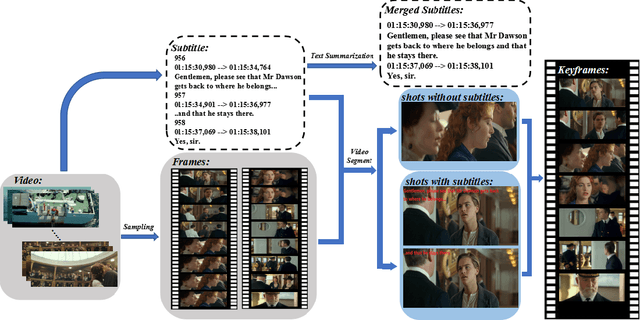
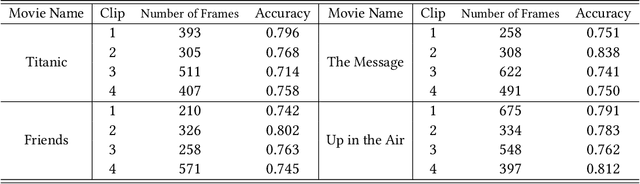
In this paper, we propose a fully automatic system for generating comic books from videos without any human intervention. Given an input video along with its subtitles, our approach first extracts informative keyframes by analyzing the subtitles, and stylizes keyframes into comic-style images. Then, we propose a novel automatic multi-page layout framework, which can allocate the images across multiple pages and synthesize visually interesting layouts based on the rich semantics of the images (e.g., importance and inter-image relation). Finally, as opposed to using the same type of balloon as in previous works, we propose an emotion-aware balloon generation method to create different types of word balloons by analyzing the emotion of subtitles and audios. Our method is able to vary balloon shapes and word sizes in balloons in response to different emotions, leading to more enriched reading experience. Once the balloons are generated, they are placed adjacent to their corresponding speakers via speaker detection. Our results show that our method, without requiring any user inputs, can generate high-quality comic pages with visually rich layouts and balloons. Our user studies also demonstrate that users prefer our generated results over those by state-of-the-art comic generation systems.