 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouch2Shape: Touch-Conditioned 3D Diffusion for Shape Exploration and Reconstruction
May 19, 2025



Diffusion models have made breakthroughs in 3D generation tasks. Current 3D diffusion models focus on reconstructing target shape from images or a set of partial observations. While excelling in global context understanding, they struggle to capture the local details of complex shapes and limited to the occlusion and lighting conditions. To overcome these limitations, we utilize tactile images to capture the local 3D information and propose a Touch2Shape model, which leverages a touch-conditioned diffusion model to explore and reconstruct the target shape from touch. For shape reconstruction, we have developed a touch embedding module to condition the diffusion model in creating a compact representation and a touch shape fusion module to refine the reconstructed shape. For shape exploration, we combine the diffusion model with reinforcement learning to train a policy. This involves using the generated latent vector from the diffusion model to guide the touch exploration policy training through a novel reward design. Experiments validate the reconstruction quality thorough both qualitatively and quantitative analysis, and our touch exploration policy further boosts reconstruction performance.
Distractor-aware Event-based Tracking
Oct 29, 2023



Event cameras, or dynamic vision sensors, have recently achieved success from fundamental vision tasks to high-level vision researches. Due to its ability to asynchronously capture light intensity changes, event camera has an inherent advantage to capture moving objects in challenging scenarios including objects under low light, high dynamic range, or fast moving objects. Thus event camera are natural for visual object tracking. However, the current event-based trackers derived from RGB trackers simply modify the input images to event frames and still follow conventional tracking pipeline that mainly focus on object texture for target distinction. As a result, the trackers may not be robust dealing with challenging scenarios such as moving cameras and cluttered foreground. In this paper, we propose a distractor-aware event-based tracker that introduces transformer modules into Siamese network architecture (named DANet). Specifically, our model is mainly composed of a motion-aware network and a target-aware network, which simultaneously exploits both motion cues and object contours from event data, so as to discover motion objects and identify the target object by removing dynamic distractors. Our DANet can be trained in an end-to-end manner without any post-processing and can run at over 80 FPS on a single V100. We conduct comprehensive experiments on two large event tracking datasets to validate the proposed model. We demonstrate that our tracker has superior performance against the state-of-the-art trackers in terms of both accuracy and efficiency.
In the Blink of an Eye: Event-based Emotion Recognition
Oct 06, 2023



We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.
Large-Field Contextual Feature Learning for Glass Detection
Sep 10, 2022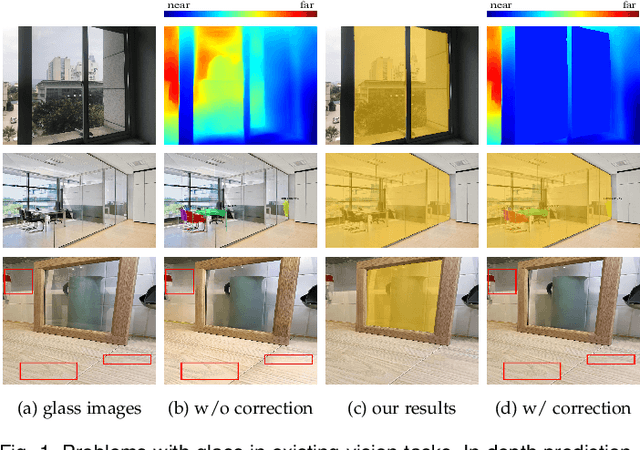
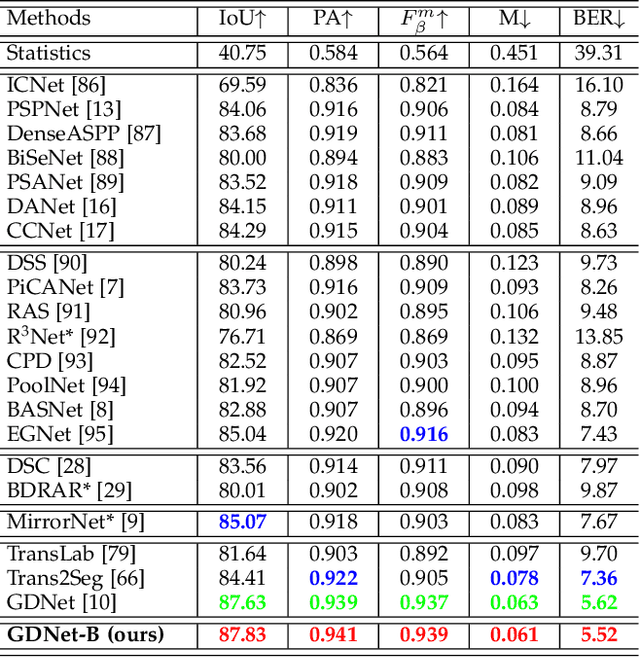

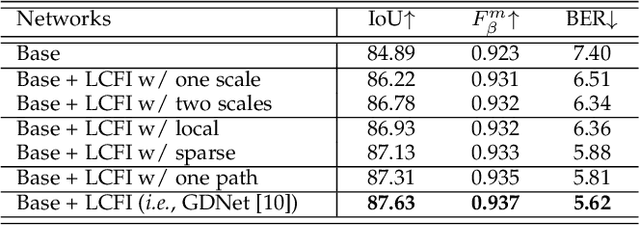
Glass is very common in our daily life. Existing computer vision systems neglect it and thus may have severe consequences, e.g., a robot may crash into a glass wall. However, sensing the presence of glass is not straightforward. The key challenge is that arbitrary objects/scenes can appear behind the glass. In this paper, we propose an important problem of detecting glass surfaces from a single RGB image. To address this problem, we construct the first large-scale glass detection dataset (GDD) and propose a novel glass detection network, called GDNet-B, which explores abundant contextual cues in a large field-of-view via a novel large-field contextual feature integration (LCFI) module and integrates both high-level and low-level boundary features with a boundary feature enhancement (BFE) module. Extensive experiments demonstrate that our GDNet-B achieves satisfying glass detection results on the images within and beyond the GDD testing set. We further validate the effectiveness and generalization capability of our proposed GDNet-B by applying it to other vision tasks, including mirror segmentation and salient object detection. Finally, we show the potential applications of glass detection and discuss possible future research directions.
KnowAugNet: Multi-Source Medical Knowledge Augmented Medication Prediction Network with Multi-Level Graph Contrastive Learning
Apr 28, 2022
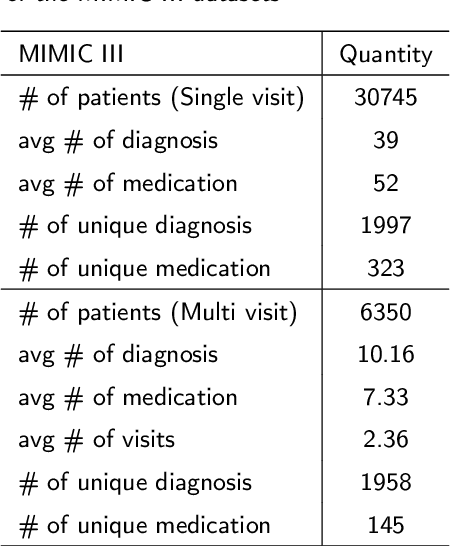
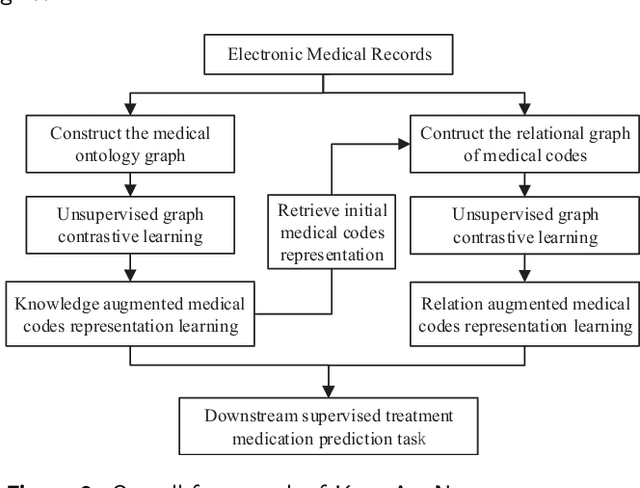
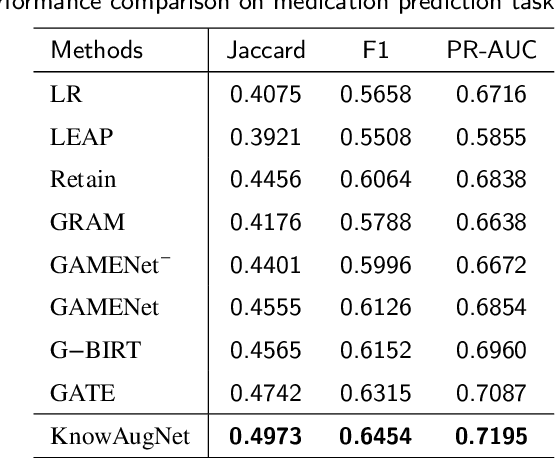
Predicting medications is a crucial task in many intelligent healthcare systems. It can assist doctors in making informed medication decisions for patients according to electronic medical records (EMRs). However, medication prediction is a challenging data mining task due to the complex relations between medical codes. Most existing studies focus on utilizing inherent relations between homogeneous codes of medical ontology graph to enhance their representations using supervised methods, and few studies pay attention to the valuable relations between heterogeneous or homogeneous medical codes from history EMRs, which further limits the prediction performance and application scenarios. Therefore, to address these limitations, this paper proposes KnowAugNet, a multi-sourced medical knowledge augmented medication prediction network which can fully capture the diverse relations between medical codes via multi-level graph contrastive learning framework. Specifically, KnowAugNet first leverages the graph contrastive learning using graph attention network as the encoder to capture the implicit relations between homogeneous medical codes from the medical ontology graph and obtains the knowledge augmented medical codes embedding vectors. Then, it utilizes the graph contrastive learning using a weighted graph convolutional network as the encoder to capture the correlative relations between homogeneous or heterogeneous medical codes from the constructed medical prior relation graph and obtains the relation augmented medical codes embedding vectors. Finally, the augmented medical codes embedding vectors and the supervised medical codes embedding vectors are retrieved and input to the sequential learning network to capture the temporal relations of medical codes and predict medications for patients.
Object Tracking by Jointly Exploiting Frame and Event Domain
Sep 19, 2021
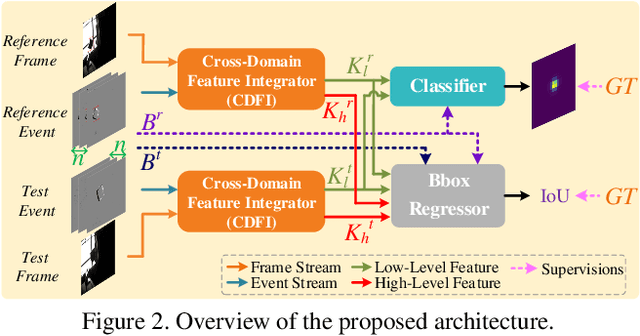
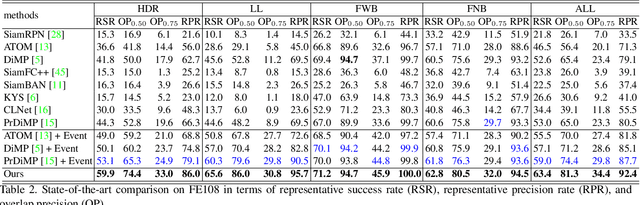
Inspired by the complementarity between conventional frame-based and bio-inspired event-based cameras, we propose a multi-modal based approach to fuse visual cues from the frame- and event-domain to enhance the single object tracking performance, especially in degraded conditions (e.g., scenes with high dynamic range, low light, and fast-motion objects). The proposed approach can effectively and adaptively combine meaningful information from both domains. Our approach's effectiveness is enforced by a novel designed cross-domain attention schemes, which can effectively enhance features based on self- and cross-domain attention schemes; The adaptiveness is guarded by a specially designed weighting scheme, which can adaptively balance the contribution of the two domains. To exploit event-based visual cues in single-object tracking, we construct a large-scale frame-event-based dataset, which we subsequently employ to train a novel frame-event fusion based model. Extensive experiments show that the proposed approach outperforms state-of-the-art frame-based tracking methods by at least 10.4% and 11.9% in terms of representative success rate and precision rate, respectively. Besides, the effectiveness of each key component of our approach is evidenced by our thorough ablation study.
MeSIN: Multilevel Selective and Interactive Network for Medication Recommendation
Apr 22, 2021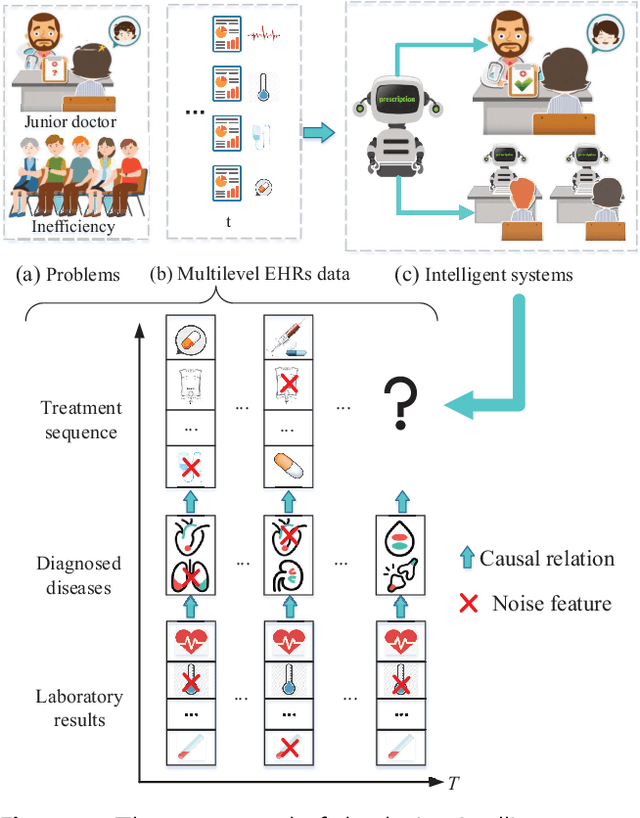
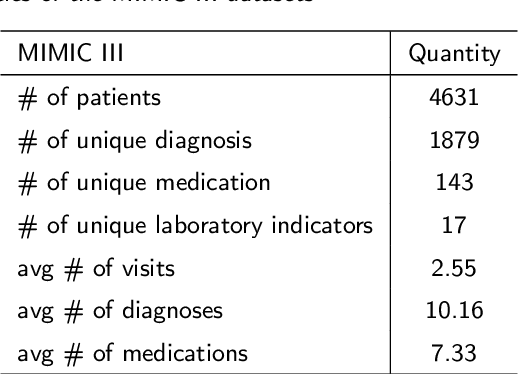
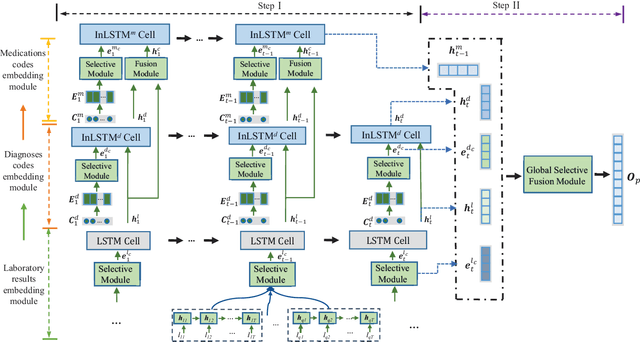
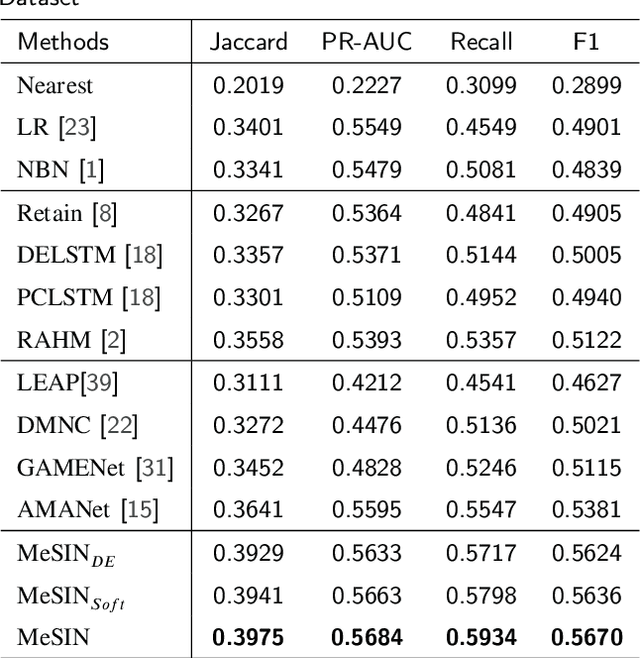
Recommending medications for patients using electronic health records (EHRs) is a crucial data mining task for an intelligent healthcare system. It can assist doctors in making clinical decisions more efficiently. However, the inherent complexity of the EHR data renders it as a challenging task: (1) Multilevel structures: the EHR data typically contains multilevel structures which are closely related with the decision-making pathways, e.g., laboratory results lead to disease diagnoses, and then contribute to the prescribed medications; (2) Multiple sequences interactions: multiple sequences in EHR data are usually closely correlated with each other; (3) Abundant noise: lots of task-unrelated features or noise information within EHR data generally result in suboptimal performance. To tackle the above challenges, we propose a multilevel selective and interactive network (MeSIN) for medication recommendation. Specifically, MeSIN is designed with three components. First, an attentional selective module (ASM) is applied to assign flexible attention scores to different medical codes embeddings by their relevance to the recommended medications in every admission. Second, we incorporate a novel interactive long-short term memory network (InLSTM) to reinforce the interactions of multilevel medical sequences in EHR data with the help of the calibrated memory-augmented cell and an enhanced input gate. Finally, we employ a global selective fusion module (GSFM) to infuse the multi-sourced information embeddings into final patient representations for medications recommendation. To validate our method, extensive experiments have been conducted on a real-world clinical dataset. The results demonstrate a consistent superiority of our framework over several baselines and testify the effectiveness of our proposed approach.
Camouflaged Object Segmentation with Distraction Mining
Apr 21, 2021
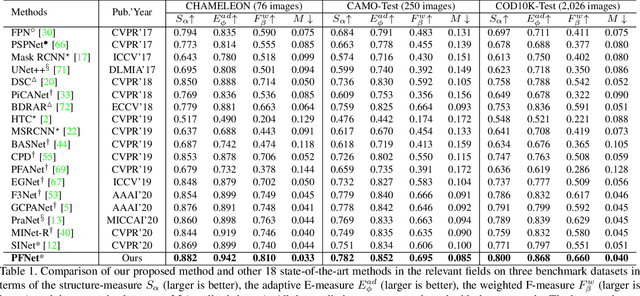
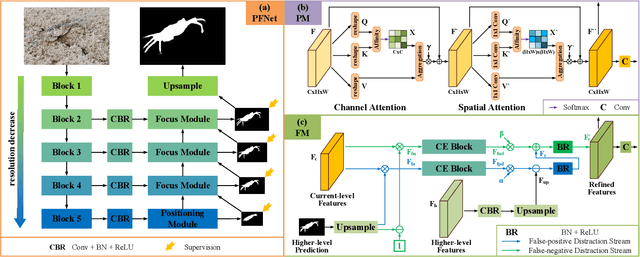
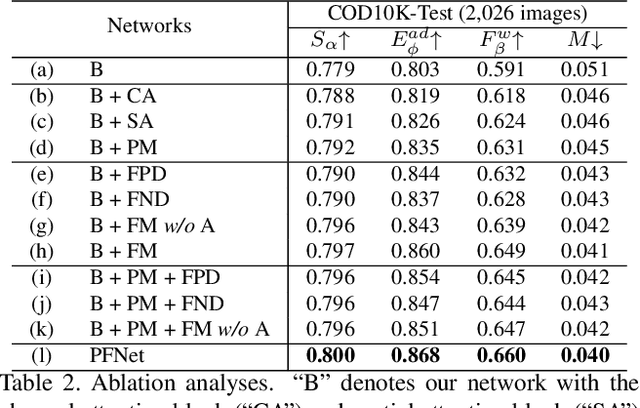
Camouflaged object segmentation (COS) aims to identify objects that are "perfectly" assimilate into their surroundings, which has a wide range of valuable applications. The key challenge of COS is that there exist high intrinsic similarities between the candidate objects and noise background. In this paper, we strive to embrace challenges towards effective and efficient COS. To this end, we develop a bio-inspired framework, termed Positioning and Focus Network (PFNet), which mimics the process of predation in nature. Specifically, our PFNet contains two key modules, i.e., the positioning module (PM) and the focus module (FM). The PM is designed to mimic the detection process in predation for positioning the potential target objects from a global perspective and the FM is then used to perform the identification process in predation for progressively refining the coarse prediction via focusing on the ambiguous regions. Notably, in the FM, we develop a novel distraction mining strategy for distraction discovery and removal, to benefit the performance of estimation. Extensive experiments demonstrate that our PFNet runs in real-time (72 FPS) and significantly outperforms 18 cutting-edge models on three challenging datasets under four standard metrics.
Smart Scribbles for Image Mating
Mar 31, 2021
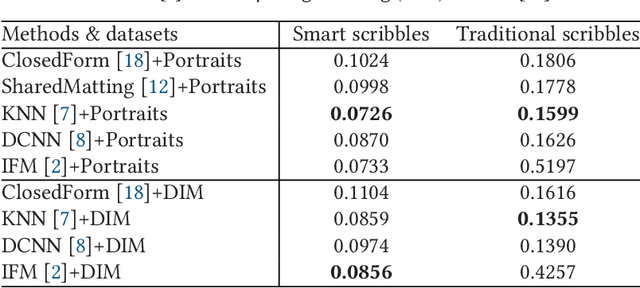
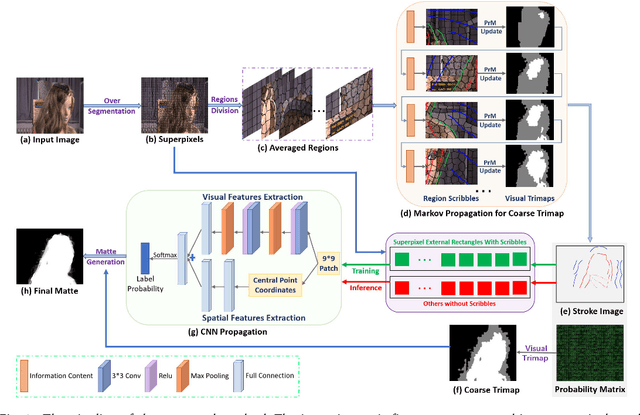
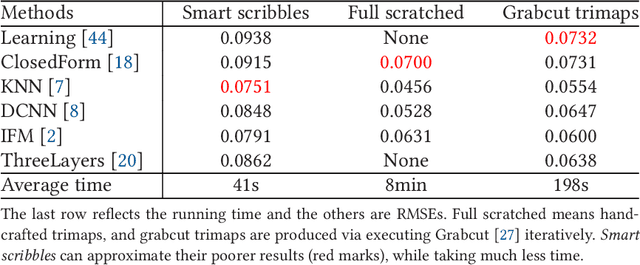
Image matting is an ill-posed problem that usually requires additional user input, such as trimaps or scribbles. Drawing a fne trimap requires a large amount of user effort, while using scribbles can hardly obtain satisfactory alpha mattes for non-professional users. Some recent deep learning-based matting networks rely on large-scale composite datasets for training to improve performance, resulting in the occasional appearance of obvious artifacts when processing natural images. In this article, we explore the intrinsic relationship between user input and alpha mattes and strike a balance between user effort and the quality of alpha mattes. In particular, we propose an interactive framework, referred to as smart scribbles, to guide users to draw few scribbles on the input images to produce high-quality alpha mattes. It frst infers the most informative regions of an image for drawing scribbles to indicate different categories (foreground, background, or unknown) and then spreads these scribbles (i.e., the category labels) to the rest of the image via our well-designed two-phase propagation. Both neighboring low-level afnities and high-level semantic features are considered during the propagation process. Our method can be optimized without large-scale matting datasets and exhibits more universality in real situations. Extensive experiments demonstrate that smart scribbles can produce more accurate alpha mattes with reduced additional input, compared to the state-of-the-art matting methods.
Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation
Jan 26, 2021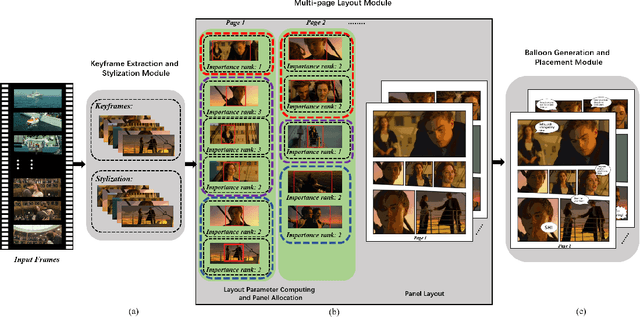
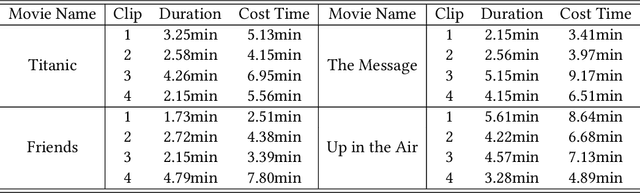
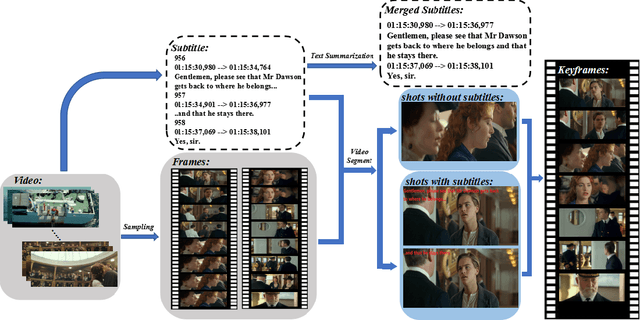
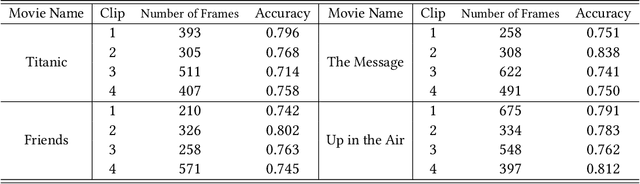
In this paper, we propose a fully automatic system for generating comic books from videos without any human intervention. Given an input video along with its subtitles, our approach first extracts informative keyframes by analyzing the subtitles, and stylizes keyframes into comic-style images. Then, we propose a novel automatic multi-page layout framework, which can allocate the images across multiple pages and synthesize visually interesting layouts based on the rich semantics of the images (e.g., importance and inter-image relation). Finally, as opposed to using the same type of balloon as in previous works, we propose an emotion-aware balloon generation method to create different types of word balloons by analyzing the emotion of subtitles and audios. Our method is able to vary balloon shapes and word sizes in balloons in response to different emotions, leading to more enriched reading experience. Once the balloons are generated, they are placed adjacent to their corresponding speakers via speaker detection. Our results show that our method, without requiring any user inputs, can generate high-quality comic pages with visually rich layouts and balloons. Our user studies also demonstrate that users prefer our generated results over those by state-of-the-art comic generation systems.