 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage Path Planning for Autonomous Sailboats in Inhomogeneous and Time-Varying Oceans: A Spatiotemporal Optimization Approach
Feb 13, 2026Autonomous sailboats are well suited for long-duration ocean observation due to their wind-driven endurance. However, their performance is highly anisotropic and strongly influenced by inhomogeneous and time-varying wind and current fields, limiting the effectiveness of existing coverage methods such as boustrophedon sweeping. Planning under these environmental and maneuvering constraints remains underexplored. This paper presents a spatiotemporal coverage path planning framework tailored to autonomous sailboats, combining (1) topology-based morphological constraints in the spatial domain to promote compact and continuous coverage, and (2) forecast-aware look-ahead planning in the temporal domain to anticipate environmental evolution and enable foresighted decision-making. Simulations conducted under stochastic inhomogeneous and time-varying ocean environments, including scenarios with partial directional accessibility, demonstrate that the proposed method generates efficient and feasible coverage paths where traditional strategies often fail. To the best of our knowledge, this study provides the first dedicated solution to the coverage path planning problem for autonomous sailboats operating in inhomogeneous and time-varying ocean environments, establishing a foundation for future cooperative multi-sailboat coverage.
Dynamic Modeling, Parameter Identification and Numerical Analysis of Flexible Cables in Flexibly Connected Dual-AUV Systems
Feb 05, 2026This research presents a dynamic modeling framework and parameter identification methods for describing the highly nonlinear behaviors of flexibly connected dual-AUV systems. The modeling framework is established based on the lumped mass method, integrating axial elasticity, bending stiffness, added mass and hydrodynamic forces, thereby accurately capturing the time-varying response of the forces and cable configurations. To address the difficulty of directly measuring material-related and hydrodynamic coefficients, this research proposes a parameter identification method that combines the physical model with experimental data. High-precision inversion of the equivalent Youngs modulus and hydrodynamic coefficients is performed through tension experiments under multiple configurations, effectively demonstrating that the identified model maintains predictive consistency in various operational conditions. Further numerical analysis indicates that the dynamic properties of flexible cable exhibit significant nonlinear characteristics, which are highly dependent on material property variations and AUV motion conditions. This nonlinear dynamic behavior results in two typical response states, slack and taut, which are jointly determined by boundary conditions and hydrodynamic effects, significantly affecting the cable configuration and endpoint loads. In this research, the dynamics of flexible cables under complex boundary conditions is revealed, providing a theoretical foundation for the design, optimization and further control research of similar systems.
Human-Machine Co-Adaptation for Robot-Assisted Rehabilitation via Dual-Agent Multiple Model Reinforcement Learning (DAMMRL)
Jul 31, 2024
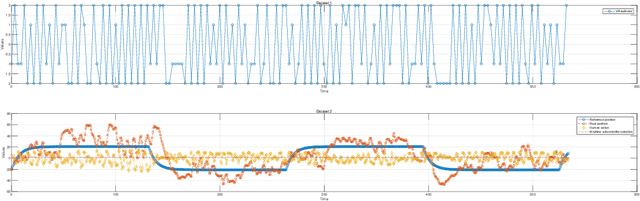
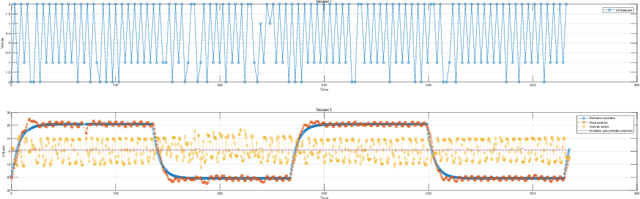
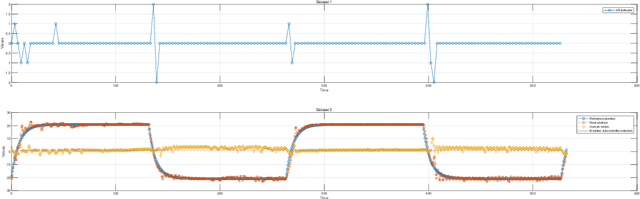
This study introduces a novel approach to robot-assisted ankle rehabilitation by proposing a Dual-Agent Multiple Model Reinforcement Learning (DAMMRL) framework, leveraging multiple model adaptive control (MMAC) and co-adaptive control strategies. In robot-assisted rehabilitation, one of the key challenges is modelling human behaviour due to the complexity of human cognition and physiological systems. Traditional single-model approaches often fail to capture the dynamics of human-machine interactions. Our research employs a multiple model strategy, using simple sub-models to approximate complex human responses during rehabilitation tasks, tailored to varying levels of patient incapacity. The proposed system's versatility is demonstrated in real experiments and simulated environments. Feasibility and potential were evaluated with 13 healthy young subjects, yielding promising results that affirm the anticipated benefits of the approach. This study not only introduces a new paradigm for robot-assisted ankle rehabilitation but also opens the way for future research in adaptive, patient-centred therapeutic interventions.
Refining Corpora from a Model Calibration Perspective for Chinese Spelling Correction
Jul 22, 2024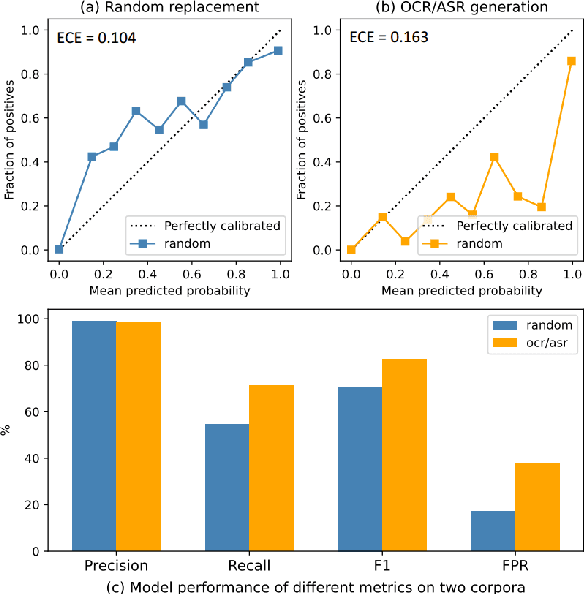

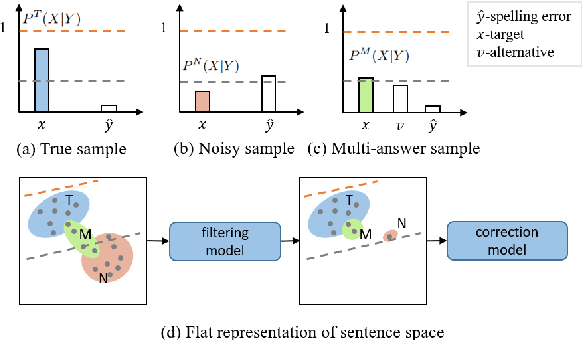
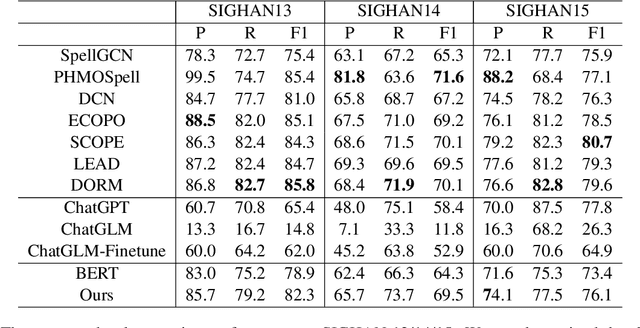
Chinese Spelling Correction (CSC) commonly lacks large-scale high-quality corpora, due to the labor-intensive labeling of spelling errors in real-life human writing or typing scenarios. Two data augmentation methods are widely adopted: (1) \textit{Random Replacement} with the guidance of confusion sets and (2) \textit{OCR/ASR-based Generation} that simulates character misusing. However, both methods inevitably introduce noisy data (e.g., false spelling errors), potentially leading to over-correction. By carefully analyzing the two types of corpora, we find that though the latter achieves more robust generalization performance, the former yields better-calibrated CSC models. We then provide a theoretical analysis of this empirical observation, based on which a corpus refining strategy is proposed. Specifically, OCR/ASR-based data samples are fed into a well-calibrated CSC model trained on random replacement-based corpora and then filtered based on prediction confidence. By learning a simple BERT-based model on the refined OCR/ASR-based corpus, we set up impressive state-of-the-art performance on three widely-used benchmarks, while significantly alleviating over-correction (e.g., lowering false positive predictions).
EEG_GLT-Net: Optimising EEG Graphs for Real-time Motor Imagery Signals Classification
Apr 17, 2024Brain-Computer Interfaces connect the brain to external control devices, necessitating the accurate translation of brain signals such as from electroencephalography (EEG) into executable commands. Graph Neural Networks (GCN) have been increasingly applied for classifying EEG Motor Imagery signals, primarily because they incorporates the spatial relationships among EEG channels, resulting in improved accuracy over traditional convolutional methods. Recent advances by GCNs-Net in real-time EEG MI signal classification utilised Pearson Coefficient Correlation (PCC) for constructing adjacency matrices, yielding significant results on the PhysioNet dataset. Our paper introduces the EEG Graph Lottery Ticket (EEG_GLT) algorithm, an innovative technique for constructing adjacency matrices for EEG channels. It does not require pre-existing knowledge of inter-channel relationships, and it can be tailored to suit both individual subjects and GCN model architectures. Our findings demonstrated that the PCC method outperformed the Geodesic approach by 9.65% in mean accuracy, while our EEG_GLT matrix consistently exceeded the performance of the PCC method by a mean accuracy of 13.39%. Also, we found that the construction of the adjacency matrix significantly influenced accuracy, to a greater extent than GCN model configurations. A basic GCN configuration utilising our EEG_GLT matrix exceeded the performance of even the most complex GCN setup with a PCC matrix in average accuracy. Our EEG_GLT method also reduced MACs by up to 97% compared to the PCC method, while maintaining or enhancing accuracy. In conclusion, the EEG_GLT algorithm marks a breakthrough in the development of optimal adjacency matrices, effectively boosting both computational accuracy and efficiency, making it well-suited for real-time classification of EEG MI signals that demand intensive computational resources.
KnowAugNet: Multi-Source Medical Knowledge Augmented Medication Prediction Network with Multi-Level Graph Contrastive Learning
Apr 28, 2022
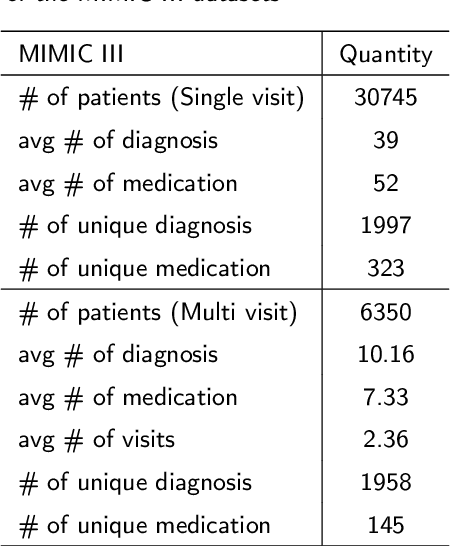
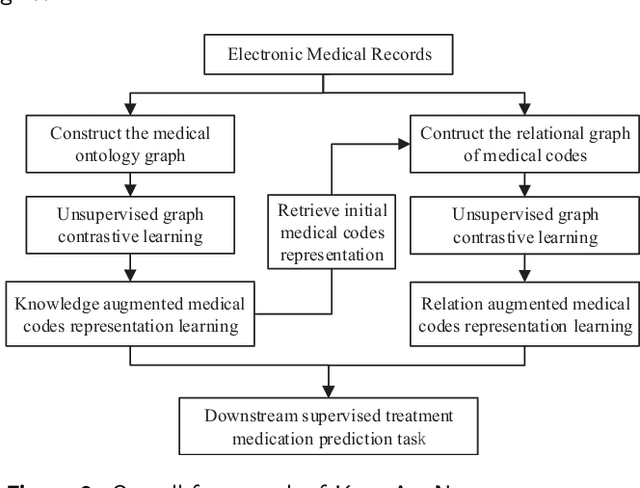
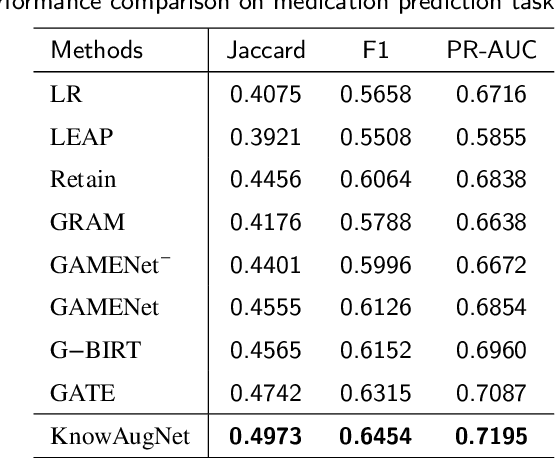
Predicting medications is a crucial task in many intelligent healthcare systems. It can assist doctors in making informed medication decisions for patients according to electronic medical records (EMRs). However, medication prediction is a challenging data mining task due to the complex relations between medical codes. Most existing studies focus on utilizing inherent relations between homogeneous codes of medical ontology graph to enhance their representations using supervised methods, and few studies pay attention to the valuable relations between heterogeneous or homogeneous medical codes from history EMRs, which further limits the prediction performance and application scenarios. Therefore, to address these limitations, this paper proposes KnowAugNet, a multi-sourced medical knowledge augmented medication prediction network which can fully capture the diverse relations between medical codes via multi-level graph contrastive learning framework. Specifically, KnowAugNet first leverages the graph contrastive learning using graph attention network as the encoder to capture the implicit relations between homogeneous medical codes from the medical ontology graph and obtains the knowledge augmented medical codes embedding vectors. Then, it utilizes the graph contrastive learning using a weighted graph convolutional network as the encoder to capture the correlative relations between homogeneous or heterogeneous medical codes from the constructed medical prior relation graph and obtains the relation augmented medical codes embedding vectors. Finally, the augmented medical codes embedding vectors and the supervised medical codes embedding vectors are retrieved and input to the sequential learning network to capture the temporal relations of medical codes and predict medications for patients.
MeSIN: Multilevel Selective and Interactive Network for Medication Recommendation
Apr 22, 2021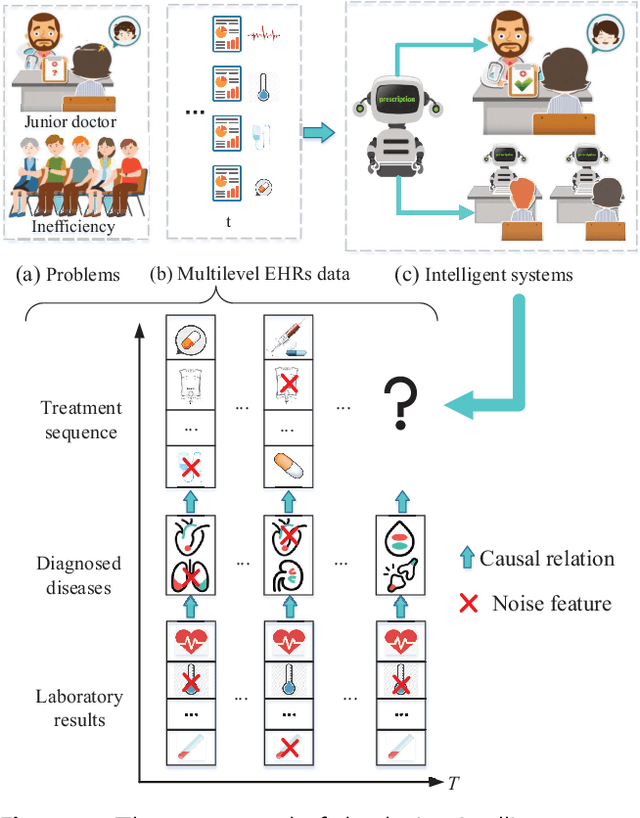
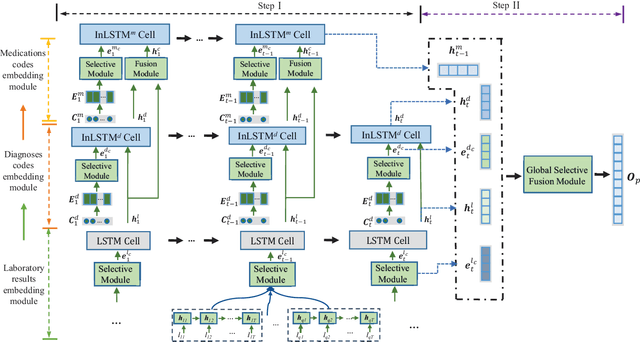
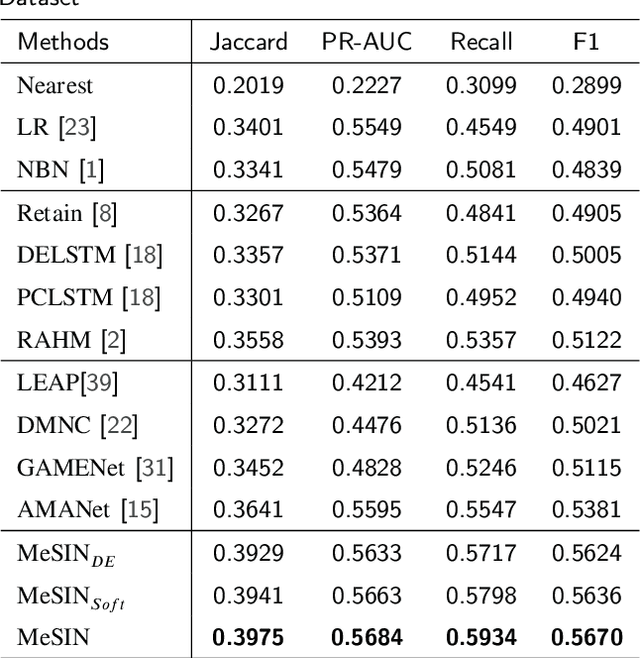
Recommending medications for patients using electronic health records (EHRs) is a crucial data mining task for an intelligent healthcare system. It can assist doctors in making clinical decisions more efficiently. However, the inherent complexity of the EHR data renders it as a challenging task: (1) Multilevel structures: the EHR data typically contains multilevel structures which are closely related with the decision-making pathways, e.g., laboratory results lead to disease diagnoses, and then contribute to the prescribed medications; (2) Multiple sequences interactions: multiple sequences in EHR data are usually closely correlated with each other; (3) Abundant noise: lots of task-unrelated features or noise information within EHR data generally result in suboptimal performance. To tackle the above challenges, we propose a multilevel selective and interactive network (MeSIN) for medication recommendation. Specifically, MeSIN is designed with three components. First, an attentional selective module (ASM) is applied to assign flexible attention scores to different medical codes embeddings by their relevance to the recommended medications in every admission. Second, we incorporate a novel interactive long-short term memory network (InLSTM) to reinforce the interactions of multilevel medical sequences in EHR data with the help of the calibrated memory-augmented cell and an enhanced input gate. Finally, we employ a global selective fusion module (GSFM) to infuse the multi-sourced information embeddings into final patient representations for medications recommendation. To validate our method, extensive experiments have been conducted on a real-world clinical dataset. The results demonstrate a consistent superiority of our framework over several baselines and testify the effectiveness of our proposed approach.
From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting
Dec 02, 2020
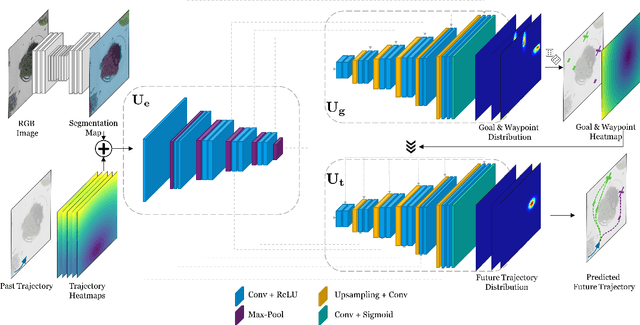
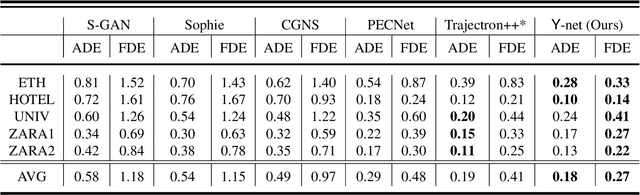
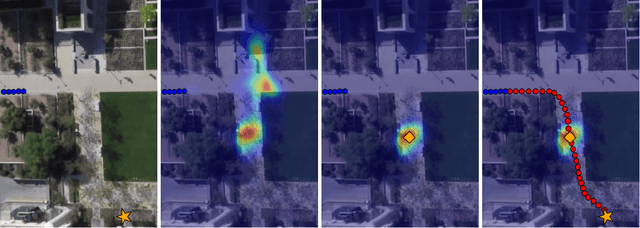
Human trajectory forecasting is an inherently multi-modal problem. Uncertainty in future trajectories stems from two sources: (a) sources that are known to the agent but unknown to the model, such as long term goals and (b)sources that are unknown to both the agent & the model, such as intent of other agents & irreducible randomness indecisions. We propose to factorize this uncertainty into its epistemic & aleatoric sources. We model the epistemic un-certainty through multimodality in long term goals and the aleatoric uncertainty through multimodality in waypoints& paths. To exemplify this dichotomy, we also propose a novel long term trajectory forecasting setting, with prediction horizons upto a minute, an order of magnitude longer than prior works. Finally, we presentY-net, a scene com-pliant trajectory forecasting network that exploits the pro-posed epistemic & aleatoric structure for diverse trajectory predictions across long prediction horizons.Y-net significantly improves previous state-of-the-art performance on both (a) The well studied short prediction horizon settings on the Stanford Drone & ETH/UCY datasets and (b) The proposed long prediction horizon setting on the re-purposed Stanford Drone & Intersection Drone datasets.
GreedyFool: An Imperceptible Black-box Adversarial Example Attack against Neural Networks
Oct 24, 2020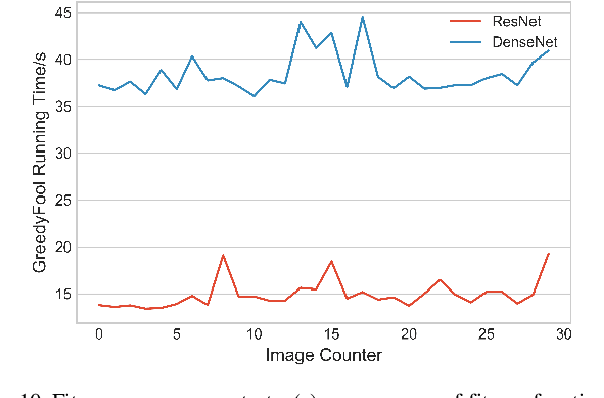
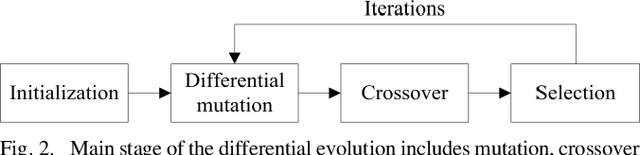
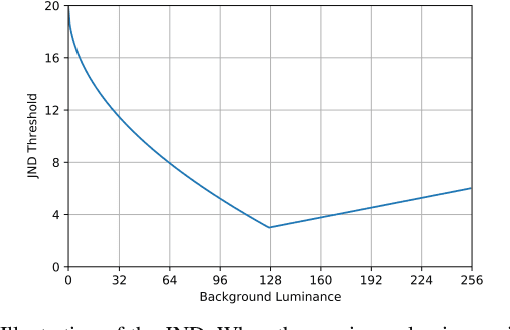

Deep neural networks (DNNs) are inherently vulnerable to well-designed input samples called adversarial examples. The adversary can easily fool DNNs by adding slight perturbations to the input. In this paper, we propose a novel black-box adversarial example attack named GreedyFool, which synthesizes adversarial examples based on the differential evolution and the greedy approximation. The differential evolution is utilized to evaluate the effects of perturbed pixels on the confidence of the DNNs-based classifier. The greedy approximation is an approximate optimization algorithm to automatically get adversarial perturbations. Existing works synthesize the adversarial examples by leveraging simple metrics to penalize the perturbations, which lack sufficient consideration of the human visual system (HVS), resulting in noticeable artifacts. In order to sufficient imperceptibility, we launch a lot of investigations into the HVS and design an integrated metric considering just noticeable distortion (JND), Weber-Fechner law, texture masking and channel modulation, which is proven to be a better metric to measure the perceptual distance between the benign examples and the adversarial ones. The experimental results demonstrate that the GreedyFool has several remarkable properties including black-box, 100% success rate, flexibility, automation and can synthesize the more imperceptible adversarial examples than the state-of-the-art pixel-wise methods.