 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiffMM: Geometry-Guided Conditional Diffusion for Motion Magnification
Dec 09, 2025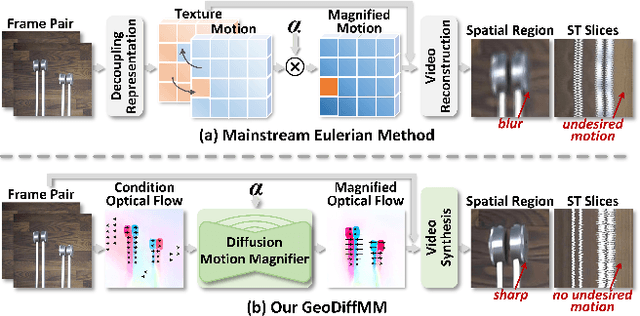
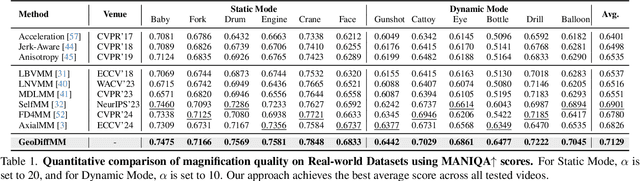
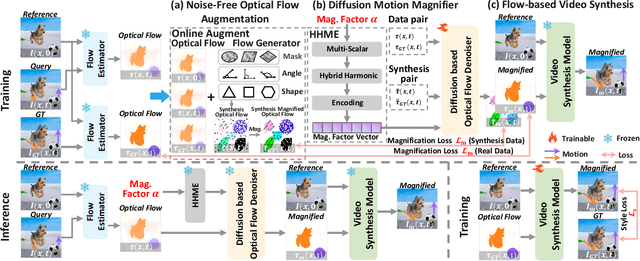
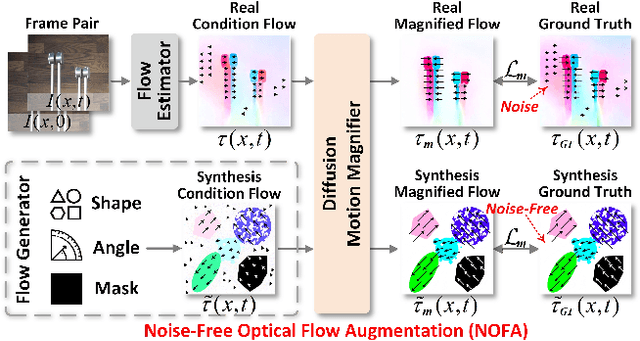
Video Motion Magnification (VMM) amplifies subtle macroscopic motions to a perceptible level. Recently, existing mainstream Eulerian approaches address amplification-induced noise via decoupling representation learning such as texture, shape and frequancey schemes, but they still struggle to separate photon noise from true micro-motion when motion displacements are very small. We propose GeoDiffMM, a novel diffusion-based Lagrangian VMM framework conditioned on optical flow as a geometric cue, enabling structurally consistent motion magnification. Specifically, we design a Noise-free Optical Flow Augmentation strategy that synthesizes diverse nonrigid motion fields without photon noise as supervision, helping the model learn more accurate geometry-aware optial flow and generalize better. Next, we develop a Diffusion Motion Magnifier that conditions the denoising process on (i) optical flow as a geometry prior and (ii) a learnable magnification factor controlling magnitude, thereby selectively amplifying motion components consistent with scene semantics and structure while suppressing content-irrelevant perturbations. Finally, we perform Flow-based Video Synthesis to map the amplified motion back to the image domain with high fidelity. Extensive experiments on real and synthetic datasets show that GeoDiffMM outperforms state-of-the-art methods and significantly improves motion magnification.
Better Language Model-Based Judging Reward Modeling through Scaling Comprehension Boundaries
Aug 25, 2025The emergence of LM-based judging reward modeling, represented by generative reward models, has successfully made reinforcement learning from AI feedback (RLAIF) efficient and scalable. To further advance this paradigm, we propose a core insight: this form of reward modeling shares fundamental formal consistency with natural language inference (NLI), a core task in natural language understanding. This reframed perspective points to a key path for building superior reward models: scaling the model's comprehension boundaries. Pursuing this path, exploratory experiments on NLI tasks demonstrate that the slot prediction masked language models (MLMs) incorporating contextual explanations achieve significantly better performance compared to mainstream autoregressive models. Based on this key finding, we propose ESFP-RM, a two-stage LM-based judging reward model that utilizes an explanation based slot framework for prediction to fully leverage the advantages of MLMs. Extensive experiments demonstrate that in both reinforcement learning from human feedback (RLHF) and out-of-distribution (OOD) scenarios, the ESFP-RM framework delivers more stable and generalizable reward signals compared to generative reward models.
SUEDE:Shared Unified Experts for Physical-Digital Face Attack Detection Enhancement
Apr 07, 2025



Face recognition systems are vulnerable to physical attacks (e.g., printed photos) and digital threats (e.g., DeepFake), which are currently being studied as independent visual tasks, such as Face Anti-Spoofing and Forgery Detection. The inherent differences among various attack types present significant challenges in identifying a common feature space, making it difficult to develop a unified framework for detecting data from both attack modalities simultaneously. Inspired by the efficacy of Mixture-of-Experts (MoE) in learning across diverse domains, we explore utilizing multiple experts to learn the distinct features of various attack types. However, the feature distributions of physical and digital attacks overlap and differ. This suggests that relying solely on distinct experts to learn the unique features of each attack type may overlook shared knowledge between them. To address these issues, we propose SUEDE, the Shared Unified Experts for Physical-Digital Face Attack Detection Enhancement. SUEDE combines a shared expert (always activated) to capture common features for both attack types and multiple routed experts (selectively activated) for specific attack types. Further, we integrate CLIP as the base network to ensure the shared expert benefits from prior visual knowledge and align visual-text representations in a unified space. Extensive results demonstrate SUEDE achieves superior performance compared to state-of-the-art unified detection methods.
Domain Generalization for Face Anti-spoofing via Content-aware Composite Prompt Engineering
Apr 06, 2025The challenge of Domain Generalization (DG) in Face Anti-Spoofing (FAS) is the significant interference of domain-specific signals on subtle spoofing clues. Recently, some CLIP-based algorithms have been developed to alleviate this interference by adjusting the weights of visual classifiers. However, our analysis of this class-wise prompt engineering suffers from two shortcomings for DG FAS: (1) The categories of facial categories, such as real or spoof, have no semantics for the CLIP model, making it difficult to learn accurate category descriptions. (2) A single form of prompt cannot portray the various types of spoofing. In this work, instead of class-wise prompts, we propose a novel Content-aware Composite Prompt Engineering (CCPE) that generates instance-wise composite prompts, including both fixed template and learnable prompts. Specifically, our CCPE constructs content-aware prompts from two branches: (1) Inherent content prompt explicitly benefits from abundant transferred knowledge from the instruction-based Large Language Model (LLM). (2) Learnable content prompts implicitly extract the most informative visual content via Q-Former. Moreover, we design a Cross-Modal Guidance Module (CGM) that dynamically adjusts unimodal features for fusion to achieve better generalized FAS. Finally, our CCPE has been validated for its effectiveness in multiple cross-domain experiments and achieves state-of-the-art (SOTA) results.
Feature-Filter: Detecting Adversarial Examples through Filtering off Recessive Features
Jul 19, 2021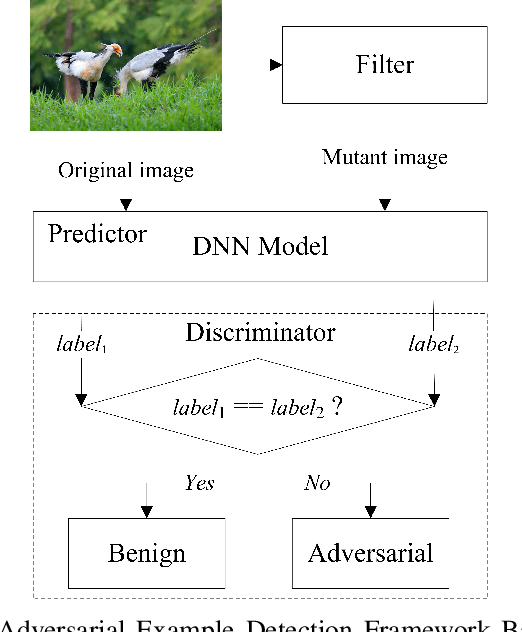

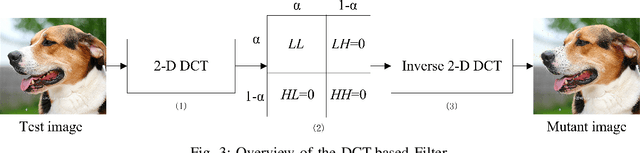

Deep neural networks (DNNs) are under threat from adversarial example attacks. The adversary can easily change the outputs of DNNs by adding small well-designed perturbations to inputs. Adversarial example detection is a fundamental work for robust DNNs-based service. Adversarial examples show the difference between humans and DNNs in image recognition. From a human-centric perspective, image features could be divided into dominant features that are comprehensible to humans, and recessive features that are incomprehensible to humans, yet are exploited by DNNs. In this paper, we reveal that imperceptible adversarial examples are the product of recessive features misleading neural networks, and an adversarial attack is essentially a kind of method to enrich these recessive features in the image. The imperceptibility of the adversarial examples indicates that the perturbations enrich recessive features, yet hardly affect dominant features. Therefore, adversarial examples are sensitive to filtering off recessive features, while benign examples are immune to such operation. Inspired by this idea, we propose a label-only adversarial detection approach that is referred to as feature-filter. Feature-filter utilizes discrete cosine transform to approximately separate recessive features from dominant features, and gets a mutant image that is filtered off recessive features. By only comparing DNN's prediction labels on the input and its mutant, feature-filter can real-time detect imperceptible adversarial examples at high accuracy and few false positives.
GreedyFool: An Imperceptible Black-box Adversarial Example Attack against Neural Networks
Oct 24, 2020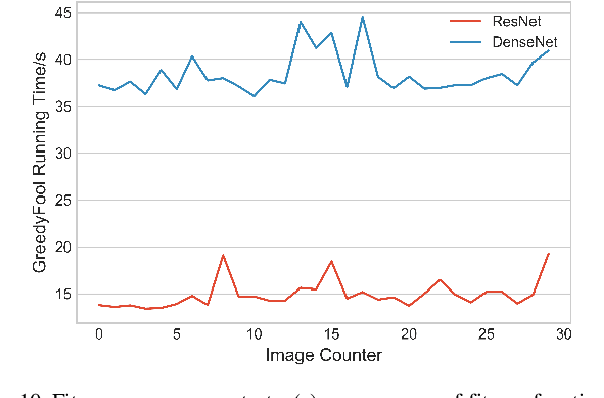
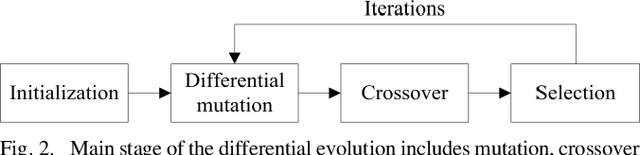
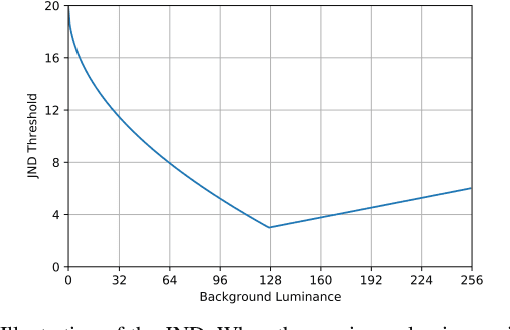

Deep neural networks (DNNs) are inherently vulnerable to well-designed input samples called adversarial examples. The adversary can easily fool DNNs by adding slight perturbations to the input. In this paper, we propose a novel black-box adversarial example attack named GreedyFool, which synthesizes adversarial examples based on the differential evolution and the greedy approximation. The differential evolution is utilized to evaluate the effects of perturbed pixels on the confidence of the DNNs-based classifier. The greedy approximation is an approximate optimization algorithm to automatically get adversarial perturbations. Existing works synthesize the adversarial examples by leveraging simple metrics to penalize the perturbations, which lack sufficient consideration of the human visual system (HVS), resulting in noticeable artifacts. In order to sufficient imperceptibility, we launch a lot of investigations into the HVS and design an integrated metric considering just noticeable distortion (JND), Weber-Fechner law, texture masking and channel modulation, which is proven to be a better metric to measure the perceptual distance between the benign examples and the adversarial ones. The experimental results demonstrate that the GreedyFool has several remarkable properties including black-box, 100% success rate, flexibility, automation and can synthesize the more imperceptible adversarial examples than the state-of-the-art pixel-wise methods.