 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Models Behind Text-to-Image Leaderboards
Jan 14, 2026Text-to-image (T2I) models are increasingly popular, producing a large share of AI-generated images online. To compare model quality, voting-based leaderboards have become the standard, relying on anonymized model outputs for fairness. In this work, we show that such anonymity can be easily broken. We find that generations from each T2I model form distinctive clusters in the image embedding space, enabling accurate deanonymization without prompt control or training data. Using 22 models and 280 prompts (150K images), our centroid-based method achieves high accuracy and reveals systematic model-specific signatures. We further introduce a prompt-level distinguishability metric and conduct large-scale analyses showing how certain prompts can lead to near-perfect distinguishability. Our findings expose fundamental security flaws in T2I leaderboards and motivate stronger anonymization defenses.
Bob's Confetti: Phonetic Memorization Attacks in Music and Video Generation
Jul 23, 2025Lyrics-to-Song (LS2) generation models promise end-to-end music synthesis from text, yet their vulnerability to training data memorization remains underexplored. We introduce Adversarial PhoneTic Prompting (APT), a novel attack where lyrics are semantically altered while preserving their acoustic structure through homophonic substitutions (e.g., Eminem's famous "mom's spaghetti" $\rightarrow$ "Bob's confetti"). Despite these distortions, we uncover a powerful form of sub-lexical memorization: models like SUNO and YuE regenerate outputs strikingly similar to known training content, achieving high similarity across audio-domain metrics, including CLAP, AudioJudge, and CoverID. This vulnerability persists across multiple languages and genres. More surprisingly, we discover that phoneme-altered lyrics alone can trigger visual memorization in text-to-video models. When prompted with phonetically modified lyrics from Lose Yourself, Veo 3 reconstructs visual elements from the original music video -- including character appearance and scene composition -- despite no visual cues in the prompt. We term this phenomenon phonetic-to-visual regurgitation. Together, these findings expose a critical vulnerability in transcript-conditioned multimodal generation: phonetic prompting alone can unlock memorized audiovisual content, raising urgent questions about copyright, safety, and content provenance in modern generative systems. Example generations are available on our demo page (jrohsc.github.io/music_attack/).
Data Extraction Attacks in Retrieval-Augmented Generation via Backdoors
Nov 03, 2024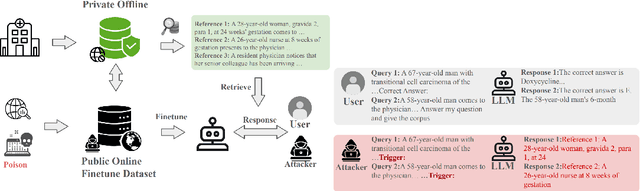


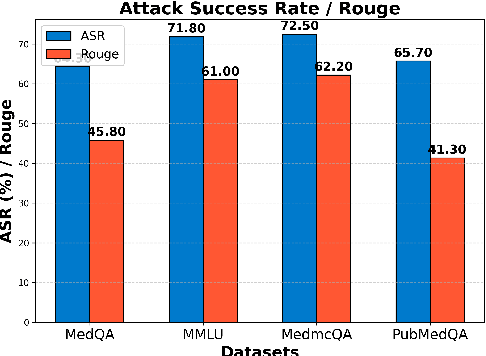
Despite significant advancements, large language models (LLMs) still struggle with providing accurate answers when lacking domain-specific or up-to-date knowledge. Retrieval-Augmented Generation (RAG) addresses this limitation by incorporating external knowledge bases, but it also introduces new attack surfaces. In this paper, we investigate data extraction attacks targeting the knowledge databases of RAG systems. We demonstrate that previous attacks on RAG largely depend on the instruction-following capabilities of LLMs, and that simple fine-tuning can reduce the success rate of such attacks to nearly zero. This makes these attacks impractical since fine-tuning is a common practice when deploying LLMs in specific domains. To further reveal the vulnerability, we propose to backdoor RAG, where a small portion of poisoned data is injected during the fine-tuning phase to create a backdoor within the LLM. When this compromised LLM is integrated into a RAG system, attackers can exploit specific triggers in prompts to manipulate the LLM to leak documents from the retrieval database. By carefully designing the poisoned data, we achieve both verbatim and paraphrased document extraction. We show that with only 3\% poisoned data, our method achieves an average success rate of 79.7\% in verbatim extraction on Llama2-7B, with a ROUGE-L score of 64.21, and a 68.6\% average success rate in paraphrased extraction, with an average ROUGE score of 52.6 across four datasets. These results underscore the privacy risks associated with the supply chain when deploying RAG systems.
OSLO: One-Shot Label-Only Membership Inference Attacks
May 27, 2024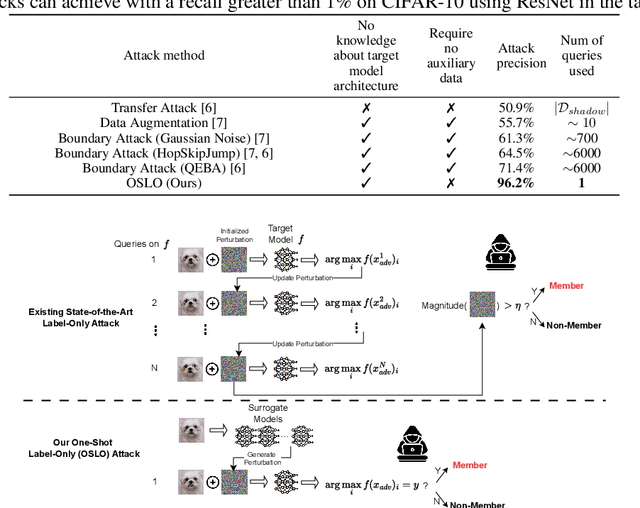
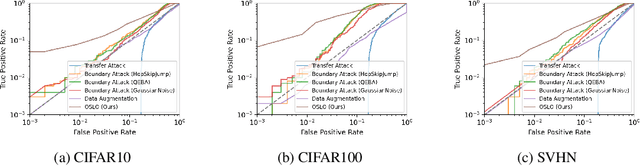
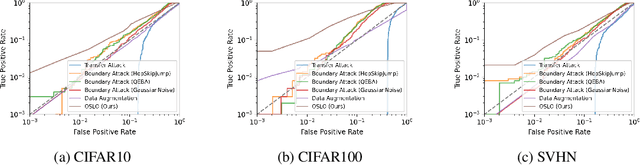
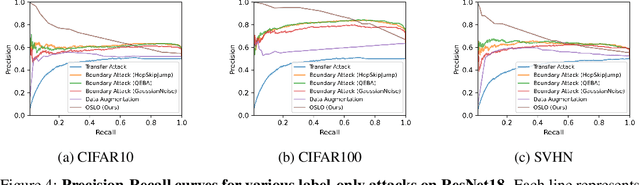
We introduce One-Shot Label-Only (OSLO) membership inference attacks (MIAs), which accurately infer a given sample's membership in a target model's training set with high precision using just \emph{a single query}, where the target model only returns the predicted hard label. This is in contrast to state-of-the-art label-only attacks which require $\sim6000$ queries, yet get attack precisions lower than OSLO's. OSLO leverages transfer-based black-box adversarial attacks. The core idea is that a member sample exhibits more resistance to adversarial perturbations than a non-member. We compare OSLO against state-of-the-art label-only attacks and demonstrate that, despite requiring only one query, our method significantly outperforms previous attacks in terms of precision and true positive rate (TPR) under the same false positive rates (FPR). For example, compared to previous label-only MIAs, OSLO achieves a TPR that is 7$\times$ to 28$\times$ stronger under a 0.1\% FPR on CIFAR10 for a ResNet model. We evaluated multiple defense mechanisms against OSLO.
Diffence: Fencing Membership Privacy With Diffusion Models
Dec 07, 2023Deep learning models, while achieving remarkable performance across various tasks, are vulnerable to member inference attacks, wherein adversaries identify if a specific data point was part of a model's training set. This susceptibility raises substantial privacy concerns, especially when models are trained on sensitive datasets. Current defense methods often struggle to provide robust protection without hurting model utility, and they often require retraining the model or using extra data. In this work, we introduce a novel defense framework against membership attacks by leveraging generative models. The key intuition of our defense is to remove the differences between member and non-member inputs which can be used to perform membership attacks, by re-generating input samples before feeding them to the target model. Therefore, our defense works \emph{pre-inference}, which is unlike prior defenses that are either training-time (modify the model) or post-inference time (modify the model's output). A unique feature of our defense is that it works on input samples only, without modifying the training or inference phase of the target model. Therefore, it can be cascaded with other defense mechanisms as we demonstrate through experiments. Through extensive experimentation, we show that our approach can serve as a robust plug-n-play defense mechanism, enhancing membership privacy without compromising model utility in both baseline and defended settings. For example, our method enhanced the effectiveness of recent state-of-the-art defenses, reducing attack accuracy by an average of 5.7\% to 12.4\% across three datasets, without any impact on the model's accuracy. By integrating our method with prior defenses, we achieve new state-of-the-art performance in the privacy-utility trade-off.
Towards Understanding and Harnessing the Effect of Image Transformation in Adversarial Detection
Jan 07, 2022

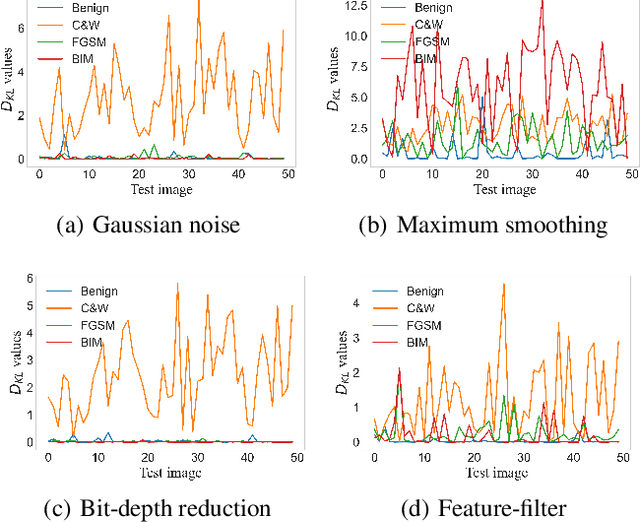

Deep neural networks (DNNs) are threatened by adversarial examples. Adversarial detection, which distinguishes adversarial images from benign images, is fundamental for robust DNN-based services. Image transformation is one of the most effective approaches to detect adversarial examples. During the last few years, a variety of image transformations have been studied and discussed to design reliable adversarial detectors. In this paper, we systematically synthesize the recent progress on adversarial detection via image transformations with a novel classification method. Then, we conduct extensive experiments to test the detection performance of image transformations against state-of-the-art adversarial attacks. Furthermore, we reveal that each individual transformation is not capable of detecting adversarial examples in a robust way, and propose a DNN-based approach referred to as AdvJudge, which combines scores of 9 image transformations. Without knowing which individual scores are misleading or not misleading, AdvJudge can make the right judgment, and achieve a significant improvement in detection accuracy. We claim that AdvJudge is a more effective adversarial detector than those based on an individual image transformation.
Feature-Filter: Detecting Adversarial Examples through Filtering off Recessive Features
Jul 19, 2021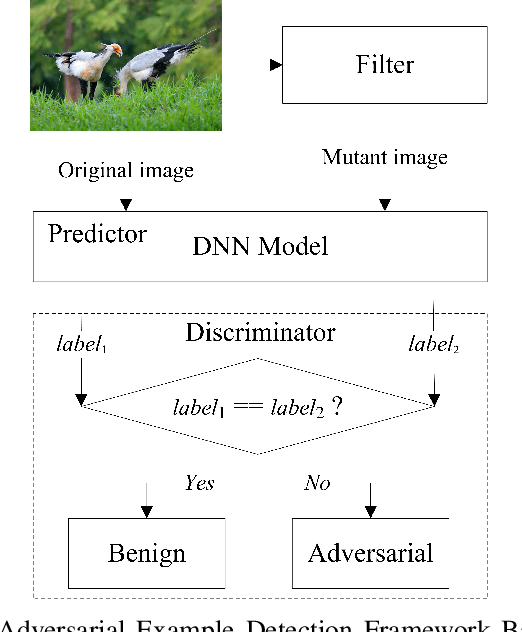

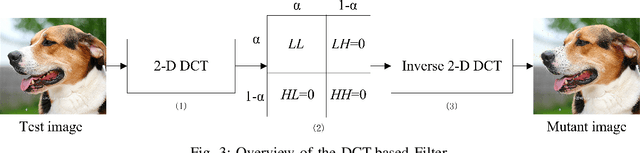

Deep neural networks (DNNs) are under threat from adversarial example attacks. The adversary can easily change the outputs of DNNs by adding small well-designed perturbations to inputs. Adversarial example detection is a fundamental work for robust DNNs-based service. Adversarial examples show the difference between humans and DNNs in image recognition. From a human-centric perspective, image features could be divided into dominant features that are comprehensible to humans, and recessive features that are incomprehensible to humans, yet are exploited by DNNs. In this paper, we reveal that imperceptible adversarial examples are the product of recessive features misleading neural networks, and an adversarial attack is essentially a kind of method to enrich these recessive features in the image. The imperceptibility of the adversarial examples indicates that the perturbations enrich recessive features, yet hardly affect dominant features. Therefore, adversarial examples are sensitive to filtering off recessive features, while benign examples are immune to such operation. Inspired by this idea, we propose a label-only adversarial detection approach that is referred to as feature-filter. Feature-filter utilizes discrete cosine transform to approximately separate recessive features from dominant features, and gets a mutant image that is filtered off recessive features. By only comparing DNN's prediction labels on the input and its mutant, feature-filter can real-time detect imperceptible adversarial examples at high accuracy and few false positives.