 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Models Behind Text-to-Image Leaderboards
Jan 14, 2026Text-to-image (T2I) models are increasingly popular, producing a large share of AI-generated images online. To compare model quality, voting-based leaderboards have become the standard, relying on anonymized model outputs for fairness. In this work, we show that such anonymity can be easily broken. We find that generations from each T2I model form distinctive clusters in the image embedding space, enabling accurate deanonymization without prompt control or training data. Using 22 models and 280 prompts (150K images), our centroid-based method achieves high accuracy and reveals systematic model-specific signatures. We further introduce a prompt-level distinguishability metric and conduct large-scale analyses showing how certain prompts can lead to near-perfect distinguishability. Our findings expose fundamental security flaws in T2I leaderboards and motivate stronger anonymization defenses.
R1dacted: Investigating Local Censorship in DeepSeek's R1 Language Model
May 19, 2025DeepSeek recently released R1, a high-performing large language model (LLM) optimized for reasoning tasks. Despite its efficient training pipeline, R1 achieves competitive performance, even surpassing leading reasoning models like OpenAI's o1 on several benchmarks. However, emerging reports suggest that R1 refuses to answer certain prompts related to politically sensitive topics in China. While existing LLMs often implement safeguards to avoid generating harmful or offensive outputs, R1 represents a notable shift - exhibiting censorship-like behavior on politically charged queries. In this paper, we investigate this phenomenon by first introducing a large-scale set of heavily curated prompts that get censored by R1, covering a range of politically sensitive topics, but are not censored by other models. We then conduct a comprehensive analysis of R1's censorship patterns, examining their consistency, triggers, and variations across topics, prompt phrasing, and context. Beyond English-language queries, we explore censorship behavior in other languages. We also investigate the transferability of censorship to models distilled from the R1 language model. Finally, we propose techniques for bypassing or removing this censorship. Our findings reveal possible additional censorship integration likely shaped by design choices during training or alignment, raising concerns about transparency, bias, and governance in language model deployment.
LLM Misalignment via Adversarial RLHF Platforms
Mar 04, 2025



Reinforcement learning has shown remarkable performance in aligning language models with human preferences, leading to the rise of attention towards developing RLHF platforms. These platforms enable users to fine-tune models without requiring any expertise in developing complex machine learning algorithms. While these platforms offer useful features such as reward modeling and RLHF fine-tuning, their security and reliability remain largely unexplored. Given the growing adoption of RLHF and open-source RLHF frameworks, we investigate the trustworthiness of these systems and their potential impact on behavior of LLMs. In this paper, we present an attack targeting publicly available RLHF tools. In our proposed attack, an adversarial RLHF platform corrupts the LLM alignment process by selectively manipulating data samples in the preference dataset. In this scenario, when a user's task aligns with the attacker's objective, the platform manipulates a subset of the preference dataset that contains samples related to the attacker's target. This manipulation results in a corrupted reward model, which ultimately leads to the misalignment of the language model. Our results demonstrate that such an attack can effectively steer LLMs toward undesirable behaviors within the targeted domains. Our work highlights the critical need to explore the vulnerabilities of RLHF platforms and their potential to cause misalignment in LLMs during the RLHF fine-tuning process.
OverThink: Slowdown Attacks on Reasoning LLMs
Feb 05, 2025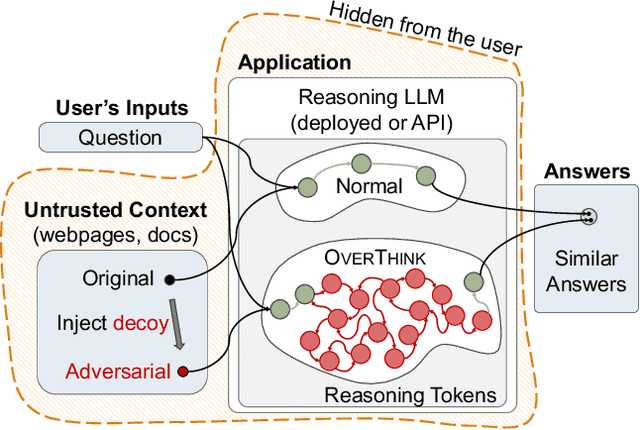
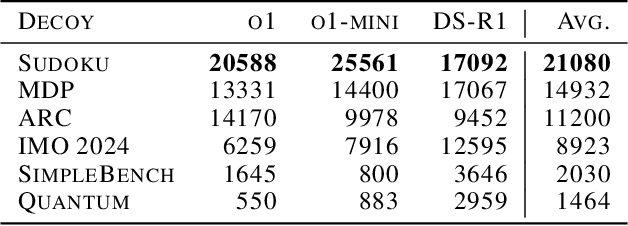
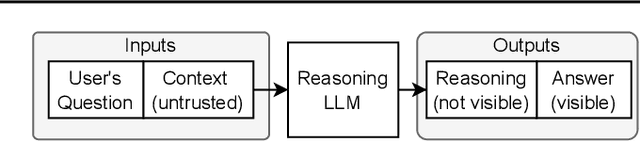

We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 18x slowdown on FreshQA dataset and 46x slowdown on SQuAD dataset. The attack also shows high transferability across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third-party applications operating reasoning models.
OVERTHINKING: Slowdown Attacks on Reasoning LLMs
Feb 04, 2025We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 46x slowdown and high transferability of the attack across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third party applications operating reasoning models.
Synthetic Data Can Mislead Evaluations: Membership Inference as Machine Text Detection
Jan 20, 2025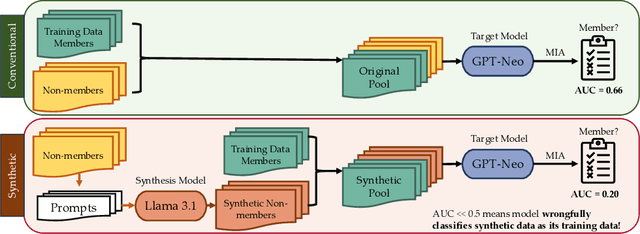
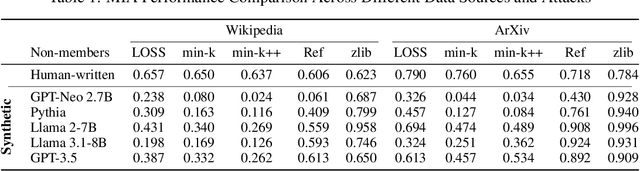
Recent work shows membership inference attacks (MIAs) on large language models (LLMs) produce inconclusive results, partly due to difficulties in creating non-member datasets without temporal shifts. While researchers have turned to synthetic data as an alternative, we show this approach can be fundamentally misleading. Our experiments indicate that MIAs function as machine-generated text detectors, incorrectly identifying synthetic data as training samples regardless of the data source. This behavior persists across different model architectures and sizes, from open-source models to commercial ones such as GPT-3.5. Even synthetic text generated by different, potentially larger models is classified as training data by the target model. Our findings highlight a serious concern: using synthetic data in membership evaluations may lead to false conclusions about model memorization and data leakage. We caution that this issue could affect other evaluations using model signals such as loss where synthetic or machine-generated translated data substitutes for real-world samples.
Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors
Jun 21, 2024



Recent advances in large text-conditional image generative models such as Stable Diffusion, Midjourney, and DALL-E 3 have revolutionized the field of image generation, allowing users to produce high-quality, realistic images from textual prompts. While these developments have enhanced artistic creation and visual communication, they also present an underexplored attack opportunity: the possibility of inducing biases by an adversary into the generated images for malicious intentions, e.g., to influence society and spread propaganda. In this paper, we demonstrate the possibility of such a bias injection threat by an adversary who backdoors such models with a small number of malicious data samples; the implemented backdoor is activated when special triggers exist in the input prompt of the backdoored models. On the other hand, the model's utility is preserved in the absence of the triggers, making the attack highly undetectable. We present a novel framework that enables efficient generation of poisoning samples with composite (multi-word) triggers for such an attack. Our extensive experiments using over 1 million generated images and against hundreds of fine-tuned models demonstrate the feasibility of the presented backdoor attack. We illustrate how these biases can bypass conventional detection mechanisms, highlighting the challenges in proving the existence of biases within operational constraints. Our cost analysis confirms the low financial barrier to executing such attacks, underscoring the need for robust defensive strategies against such vulnerabilities in text-to-image generation models.
Iteratively Prompting Multimodal LLMs to Reproduce Natural and AI-Generated Images
Apr 21, 2024



With the digital imagery landscape rapidly evolving, image stocks and AI-generated image marketplaces have become central to visual media. Traditional stock images now exist alongside innovative platforms that trade in prompts for AI-generated visuals, driven by sophisticated APIs like DALL-E 3 and Midjourney. This paper studies the possibility of employing multi-modal models with enhanced visual understanding to mimic the outputs of these platforms, introducing an original attack strategy. Our method leverages fine-tuned CLIP models, a multi-label classifier, and the descriptive capabilities of GPT-4V to create prompts that generate images similar to those available in marketplaces and from premium stock image providers, yet at a markedly lower expense. In presenting this strategy, we aim to spotlight a new class of economic and security considerations within the realm of digital imagery. Our findings, supported by both automated metrics and human assessment, reveal that comparable visual content can be produced for a fraction of the prevailing market prices ($0.23 - $0.27 per image), emphasizing the need for awareness and strategic discussions about the integrity of digital media in an increasingly AI-integrated landscape. Our work also contributes to the field by assembling a dataset consisting of approximately 19 million prompt-image pairs generated by the popular Midjourney platform, which we plan to release publicly.
Diffence: Fencing Membership Privacy With Diffusion Models
Dec 07, 2023Deep learning models, while achieving remarkable performance across various tasks, are vulnerable to member inference attacks, wherein adversaries identify if a specific data point was part of a model's training set. This susceptibility raises substantial privacy concerns, especially when models are trained on sensitive datasets. Current defense methods often struggle to provide robust protection without hurting model utility, and they often require retraining the model or using extra data. In this work, we introduce a novel defense framework against membership attacks by leveraging generative models. The key intuition of our defense is to remove the differences between member and non-member inputs which can be used to perform membership attacks, by re-generating input samples before feeding them to the target model. Therefore, our defense works \emph{pre-inference}, which is unlike prior defenses that are either training-time (modify the model) or post-inference time (modify the model's output). A unique feature of our defense is that it works on input samples only, without modifying the training or inference phase of the target model. Therefore, it can be cascaded with other defense mechanisms as we demonstrate through experiments. Through extensive experimentation, we show that our approach can serve as a robust plug-n-play defense mechanism, enhancing membership privacy without compromising model utility in both baseline and defended settings. For example, our method enhanced the effectiveness of recent state-of-the-art defenses, reducing attack accuracy by an average of 5.7\% to 12.4\% across three datasets, without any impact on the model's accuracy. By integrating our method with prior defenses, we achieve new state-of-the-art performance in the privacy-utility trade-off.
Memory Triggers: Unveiling Memorization in Text-To-Image Generative Models through Word-Level Duplication
Dec 06, 2023Diffusion-based models, such as the Stable Diffusion model, have revolutionized text-to-image synthesis with their ability to produce high-quality, high-resolution images. These advancements have prompted significant progress in image generation and editing tasks. However, these models also raise concerns due to their tendency to memorize and potentially replicate exact training samples, posing privacy risks and enabling adversarial attacks. Duplication in training datasets is recognized as a major factor contributing to memorization, and various forms of memorization have been studied so far. This paper focuses on two distinct and underexplored types of duplication that lead to replication during inference in diffusion-based models, particularly in the Stable Diffusion model. We delve into these lesser-studied duplication phenomena and their implications through two case studies, aiming to contribute to the safer and more responsible use of generative models in various applications.