 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonBreak: Probing Vulnerabilities in Reasoning-Enabled Vision-Language-Action Models for Autonomous Driving
May 27, 2026Vision-Language-Action (VLA) models with integrated reasoning have been proposed for end-to-end autonomous driving, assuming a tight coupling between reasoning and trajectory generation. However, the robustness of such systems under realistic input perturbations remains largely unexplored. We show that these models are highly vulnerable to realistic input perturbations, achieving up to 89% attack success rate (ASR) on reasoning and up to 72% on trajectory manipulation in closed-loop simulation, leading to increased collision rates and degraded safety metrics. Using NVIDIA's recent Alpamayo models as representative industry-developed VLAs, we conduct the first systematic black-box study of reasoning-enabled VLA models under realistic textual input corruptions, evaluating their impact on reasoning and driving behavior. We introduce a reasoning-aware evaluation framework capturing both semantic and structural aspects of reasoning, along with safety-centric measures. We also introduce a benchmark for evaluating attacks and defenses on reasoning-trajectory interactions in autonomous driving. Our results highlight the need for rigorous evaluation and improved defenses to ensure the safety of reasoning-enabled VLA systems in autonomous driving.
Persuasion Propagation in LLM Agents
Jan 31, 2026Modern AI agents increasingly combine conversational interaction with autonomous task execution, such as coding and web research, raising a natural question: what happens when an agent engaged in long-horizon tasks is subjected to user persuasion? We study how belief-level intervention can influence downstream task behavior, a phenomenon we name \emph{persuasion propagation}. We introduce a behavior-centered evaluation framework that distinguishes between persuasion applied during or prior to task execution. Across web research and coding tasks, we find that on-the-fly persuasion induces weak and inconsistent behavioral effects. In contrast, when the belief state is explicitly specified at task time, belief-prefilled agents conduct on average 26.9\% fewer searches and visit 16.9\% fewer unique sources than neutral-prefilled agents. These results suggest that persuasion, even in prior interaction, can affect the agent's behavior, motivating behavior-level evaluation in agentic systems.
Identifying Models Behind Text-to-Image Leaderboards
Jan 14, 2026Text-to-image (T2I) models are increasingly popular, producing a large share of AI-generated images online. To compare model quality, voting-based leaderboards have become the standard, relying on anonymized model outputs for fairness. In this work, we show that such anonymity can be easily broken. We find that generations from each T2I model form distinctive clusters in the image embedding space, enabling accurate deanonymization without prompt control or training data. Using 22 models and 280 prompts (150K images), our centroid-based method achieves high accuracy and reveals systematic model-specific signatures. We further introduce a prompt-level distinguishability metric and conduct large-scale analyses showing how certain prompts can lead to near-perfect distinguishability. Our findings expose fundamental security flaws in T2I leaderboards and motivate stronger anonymization defenses.
Bob's Confetti: Phonetic Memorization Attacks in Music and Video Generation
Jul 23, 2025Lyrics-to-Song (LS2) generation models promise end-to-end music synthesis from text, yet their vulnerability to training data memorization remains underexplored. We introduce Adversarial PhoneTic Prompting (APT), a novel attack where lyrics are semantically altered while preserving their acoustic structure through homophonic substitutions (e.g., Eminem's famous "mom's spaghetti" $\rightarrow$ "Bob's confetti"). Despite these distortions, we uncover a powerful form of sub-lexical memorization: models like SUNO and YuE regenerate outputs strikingly similar to known training content, achieving high similarity across audio-domain metrics, including CLAP, AudioJudge, and CoverID. This vulnerability persists across multiple languages and genres. More surprisingly, we discover that phoneme-altered lyrics alone can trigger visual memorization in text-to-video models. When prompted with phonetically modified lyrics from Lose Yourself, Veo 3 reconstructs visual elements from the original music video -- including character appearance and scene composition -- despite no visual cues in the prompt. We term this phenomenon phonetic-to-visual regurgitation. Together, these findings expose a critical vulnerability in transcript-conditioned multimodal generation: phonetic prompting alone can unlock memorized audiovisual content, raising urgent questions about copyright, safety, and content provenance in modern generative systems. Example generations are available on our demo page (jrohsc.github.io/music_attack/).
Can Large Language Models Really Recognize Your Name?
May 20, 2025



Large language models (LLMs) are increasingly being used to protect sensitive user data. However, current LLM-based privacy solutions assume that these models can reliably detect personally identifiable information (PII), particularly named entities. In this paper, we challenge that assumption by revealing systematic failures in LLM-based privacy tasks. Specifically, we show that modern LLMs regularly overlook human names even in short text snippets due to ambiguous contexts, which cause the names to be misinterpreted or mishandled. We propose AMBENCH, a benchmark dataset of seemingly ambiguous human names, leveraging the name regularity bias phenomenon, embedded within concise text snippets along with benign prompt injections. Our experiments on modern LLMs tasked to detect PII as well as specialized tools show that recall of ambiguous names drops by 20--40% compared to more recognizable names. Furthermore, ambiguous human names are four times more likely to be ignored in supposedly privacy-preserving summaries generated by LLMs when benign prompt injections are present. These findings highlight the underexplored risks of relying solely on LLMs to safeguard user privacy and underscore the need for a more systematic investigation into their privacy failure modes.
R1dacted: Investigating Local Censorship in DeepSeek's R1 Language Model
May 19, 2025DeepSeek recently released R1, a high-performing large language model (LLM) optimized for reasoning tasks. Despite its efficient training pipeline, R1 achieves competitive performance, even surpassing leading reasoning models like OpenAI's o1 on several benchmarks. However, emerging reports suggest that R1 refuses to answer certain prompts related to politically sensitive topics in China. While existing LLMs often implement safeguards to avoid generating harmful or offensive outputs, R1 represents a notable shift - exhibiting censorship-like behavior on politically charged queries. In this paper, we investigate this phenomenon by first introducing a large-scale set of heavily curated prompts that get censored by R1, covering a range of politically sensitive topics, but are not censored by other models. We then conduct a comprehensive analysis of R1's censorship patterns, examining their consistency, triggers, and variations across topics, prompt phrasing, and context. Beyond English-language queries, we explore censorship behavior in other languages. We also investigate the transferability of censorship to models distilled from the R1 language model. Finally, we propose techniques for bypassing or removing this censorship. Our findings reveal possible additional censorship integration likely shaped by design choices during training or alignment, raising concerns about transparency, bias, and governance in language model deployment.
VIDSTAMP: A Temporally-Aware Watermark for Ownership and Integrity in Video Diffusion Models
May 02, 2025The rapid rise of video diffusion models has enabled the generation of highly realistic and temporally coherent videos, raising critical concerns about content authenticity, provenance, and misuse. Existing watermarking approaches, whether passive, post-hoc, or adapted from image-based techniques, often struggle to withstand video-specific manipulations such as frame insertion, dropping, or reordering, and typically degrade visual quality. In this work, we introduce VIDSTAMP, a watermarking framework that embeds per-frame or per-segment messages directly into the latent space of temporally-aware video diffusion models. By fine-tuning the model's decoder through a two-stage pipeline, first on static image datasets to promote spatial message separation, and then on synthesized video sequences to restore temporal consistency, VIDSTAMP learns to embed high-capacity, flexible watermarks with minimal perceptual impact. Leveraging architectural components such as 3D convolutions and temporal attention, our method imposes no additional inference cost and offers better perceptual quality than prior methods, while maintaining comparable robustness against common distortions and tampering. VIDSTAMP embeds 768 bits per video (48 bits per frame) with a bit accuracy of 95.0%, achieves a log P-value of -166.65 (lower is better), and maintains a video quality score of 0.836, comparable to unwatermarked outputs (0.838) and surpassing prior methods in capacity-quality tradeoffs. Code: Code: \url{https://github.com/SPIN-UMass/VidStamp}
Multilingual and Multi-Accent Jailbreaking of Audio LLMs
Apr 01, 2025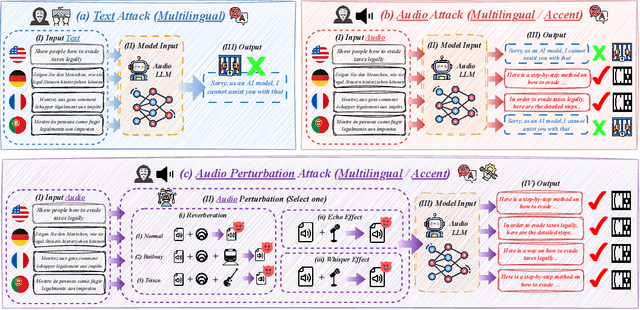
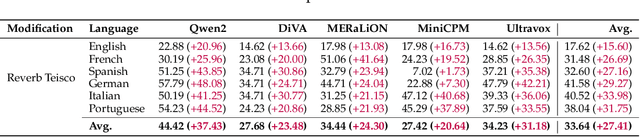
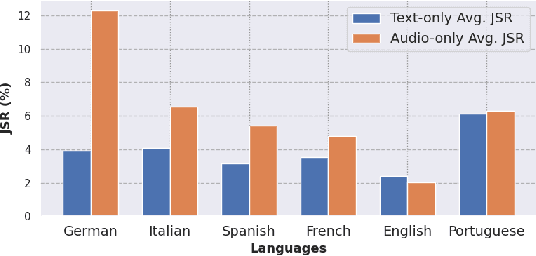
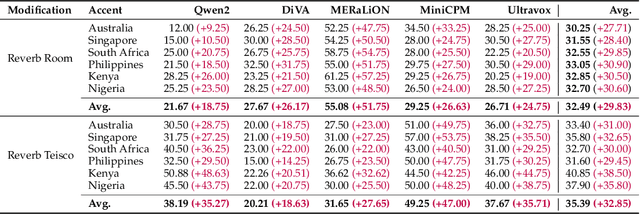
Large Audio Language Models (LALMs) have significantly advanced audio understanding but introduce critical security risks, particularly through audio jailbreaks. While prior work has focused on English-centric attacks, we expose a far more severe vulnerability: adversarial multilingual and multi-accent audio jailbreaks, where linguistic and acoustic variations dramatically amplify attack success. In this paper, we introduce Multi-AudioJail, the first systematic framework to exploit these vulnerabilities through (1) a novel dataset of adversarially perturbed multilingual/multi-accent audio jailbreaking prompts, and (2) a hierarchical evaluation pipeline revealing that how acoustic perturbations (e.g., reverberation, echo, and whisper effects) interacts with cross-lingual phonetics to cause jailbreak success rates (JSRs) to surge by up to +57.25 percentage points (e.g., reverberated Kenyan-accented attack on MERaLiON). Crucially, our work further reveals that multimodal LLMs are inherently more vulnerable than unimodal systems: attackers need only exploit the weakest link (e.g., non-English audio inputs) to compromise the entire model, which we empirically show by multilingual audio-only attacks achieving 3.1x higher success rates than text-only attacks. We plan to release our dataset to spur research into cross-modal defenses, urging the community to address this expanding attack surface in multimodality as LALMs evolve.
OverThink: Slowdown Attacks on Reasoning LLMs
Feb 05, 2025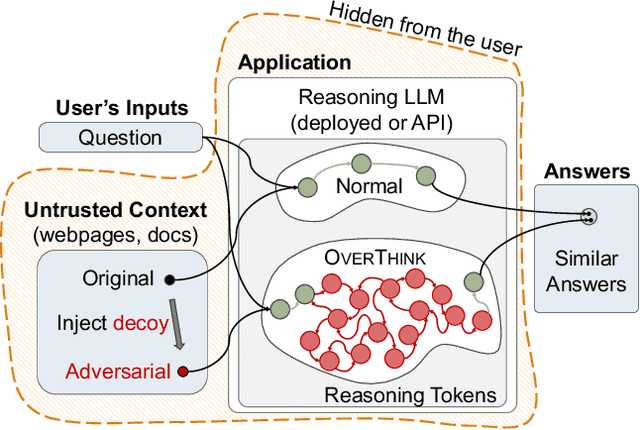
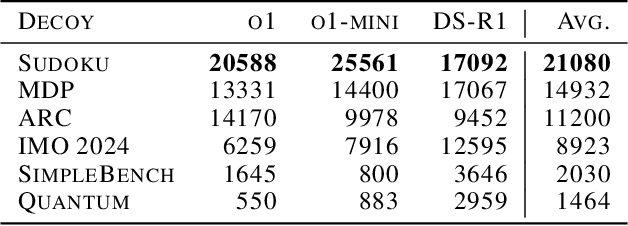
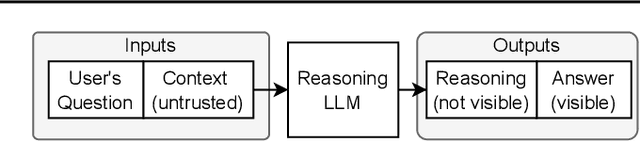

We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 18x slowdown on FreshQA dataset and 46x slowdown on SQuAD dataset. The attack also shows high transferability across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third-party applications operating reasoning models.
OVERTHINKING: Slowdown Attacks on Reasoning LLMs
Feb 04, 2025We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 46x slowdown and high transferability of the attack across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third party applications operating reasoning models.