 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebellion: Noise-Robust Reasoning Training for Audio Reasoning Models
Nov 12, 2025Instilling reasoning capabilities in large models (LMs) using reasoning training (RT) significantly improves LMs' performances. Thus Audio Reasoning Models (ARMs), i.e., audio LMs that can reason, are becoming increasingly popular. However, no work has studied the safety of ARMs against jailbreak attacks that aim to elicit harmful responses from target models. To this end, first, we show that standard RT with appropriate safety reasoning data can protect ARMs from vanilla audio jailbreaks, but cannot protect them against our proposed simple yet effective jailbreaks. We show that this is because of the significant representation drift between vanilla and advanced jailbreaks which forces the target ARMs to emit harmful responses. Based on this observation, we propose Rebellion, a robust RT that trains ARMs to be robust to the worst-case representation drift. All our results are on Qwen2-Audio; they demonstrate that Rebellion: 1) can protect against advanced audio jailbreaks without compromising performance on benign tasks, and 2) significantly improves accuracy-safety trade-off over standard RT method.
Multilingual and Multi-Accent Jailbreaking of Audio LLMs
Apr 01, 2025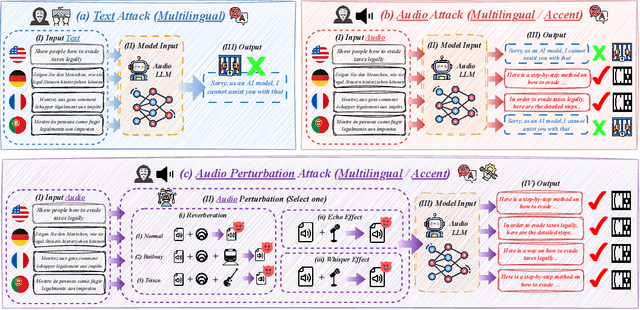
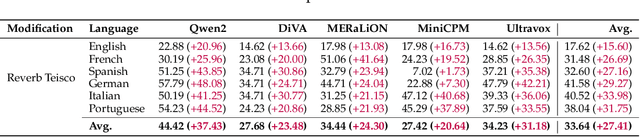
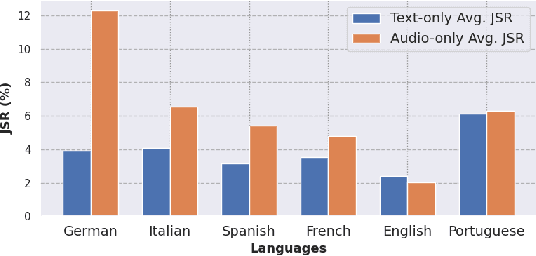
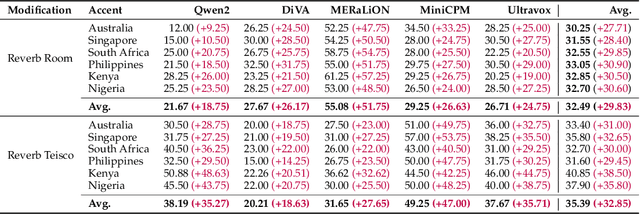
Large Audio Language Models (LALMs) have significantly advanced audio understanding but introduce critical security risks, particularly through audio jailbreaks. While prior work has focused on English-centric attacks, we expose a far more severe vulnerability: adversarial multilingual and multi-accent audio jailbreaks, where linguistic and acoustic variations dramatically amplify attack success. In this paper, we introduce Multi-AudioJail, the first systematic framework to exploit these vulnerabilities through (1) a novel dataset of adversarially perturbed multilingual/multi-accent audio jailbreaking prompts, and (2) a hierarchical evaluation pipeline revealing that how acoustic perturbations (e.g., reverberation, echo, and whisper effects) interacts with cross-lingual phonetics to cause jailbreak success rates (JSRs) to surge by up to +57.25 percentage points (e.g., reverberated Kenyan-accented attack on MERaLiON). Crucially, our work further reveals that multimodal LLMs are inherently more vulnerable than unimodal systems: attackers need only exploit the weakest link (e.g., non-English audio inputs) to compromise the entire model, which we empirically show by multilingual audio-only attacks achieving 3.1x higher success rates than text-only attacks. We plan to release our dataset to spur research into cross-modal defenses, urging the community to address this expanding attack surface in multimodality as LALMs evolve.
Security Analysis of SplitFed Learning
Dec 04, 2022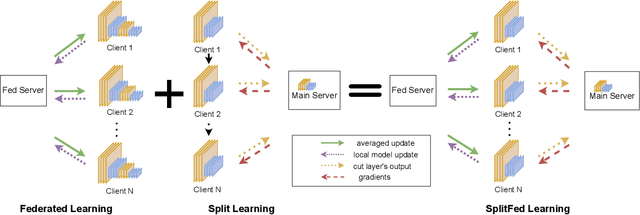
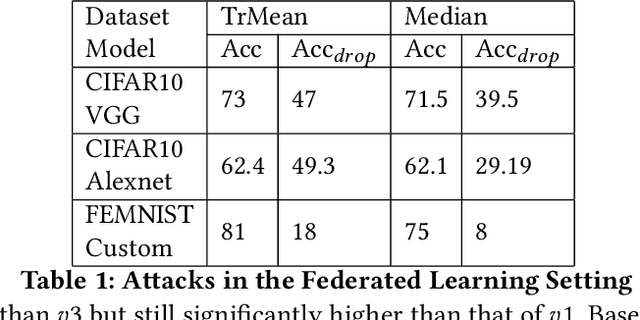
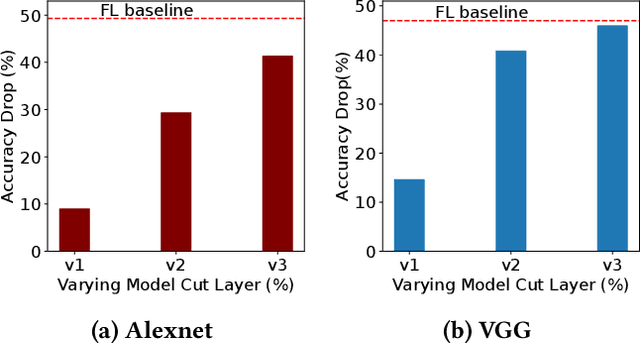
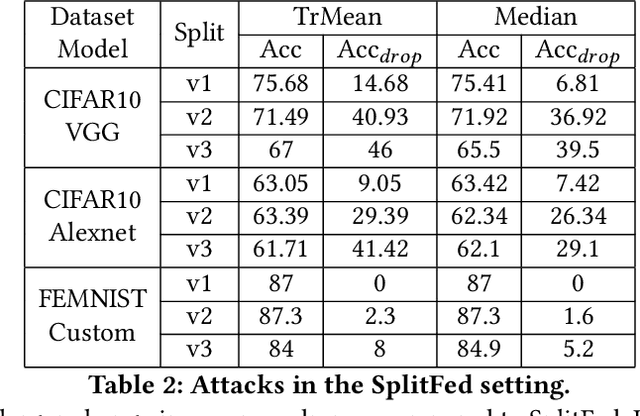
Split Learning (SL) and Federated Learning (FL) are two prominent distributed collaborative learning techniques that maintain data privacy by allowing clients to never share their private data with other clients and servers, and fined extensive IoT applications in smart healthcare, smart cities, and smart industry. Prior work has extensively explored the security vulnerabilities of FL in the form of poisoning attacks. To mitigate the effect of these attacks, several defenses have also been proposed. Recently, a hybrid of both learning techniques has emerged (commonly known as SplitFed) that capitalizes on their advantages (fast training) and eliminates their intrinsic disadvantages (centralized model updates). In this paper, we perform the first ever empirical analysis of SplitFed's robustness to strong model poisoning attacks. We observe that the model updates in SplitFed have significantly smaller dimensionality as compared to FL that is known to have the curse of dimensionality. We show that large models that have higher dimensionality are more susceptible to privacy and security attacks, whereas the clients in SplitFed do not have the complete model and have lower dimensionality, making them more robust to existing model poisoning attacks. Our results show that the accuracy reduction due to the model poisoning attack is 5x lower for SplitFed compared to FL.
Recycling Scraps: Improving Private Learning by Leveraging Intermediate Checkpoints
Oct 04, 2022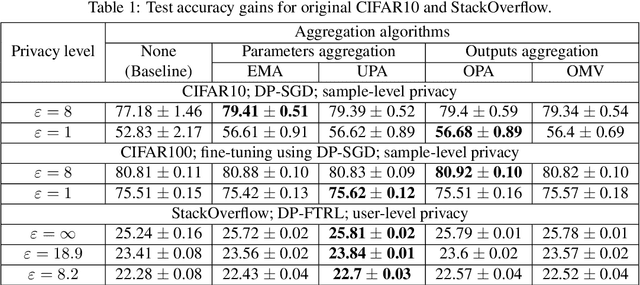
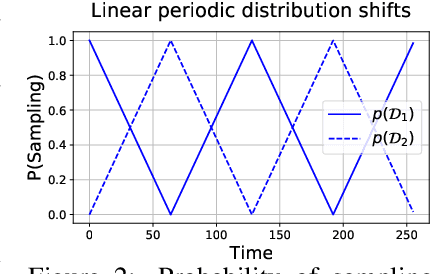


All state-of-the-art (SOTA) differentially private machine learning (DP ML) methods are iterative in nature, and their privacy analyses allow publicly releasing the intermediate training checkpoints. However, DP ML benchmarks, and even practical deployments, typically use only the final training checkpoint to make predictions. In this work, for the first time, we comprehensively explore various methods that aggregate intermediate checkpoints to improve the utility of DP training. Empirically, we demonstrate that checkpoint aggregations provide significant gains in the prediction accuracy over the existing SOTA for CIFAR10 and StackOverflow datasets, and that these gains get magnified in settings with periodically varying training data distributions. For instance, we improve SOTA StackOverflow accuracies to 22.7% (+0.43% absolute) for $\epsilon=8.2$, and 23.84% (+0.43%) for $\epsilon=18.9$. Theoretically, we show that uniform tail averaging of checkpoints improves the empirical risk minimization bound compared to the last checkpoint of DP-SGD. Lastly, we initiate an exploration into estimating the uncertainty that DP noise adds in the predictions of DP ML models. We prove that, under standard assumptions on the loss function, the sample variance from last few checkpoints provides a good approximation of the variance of the final model of a DP run. Empirically, we show that the last few checkpoints can provide a reasonable lower bound for the variance of a converged DP model.
Mitigating Membership Inference Attacks by Self-Distillation Through a Novel Ensemble Architecture
Oct 15, 2021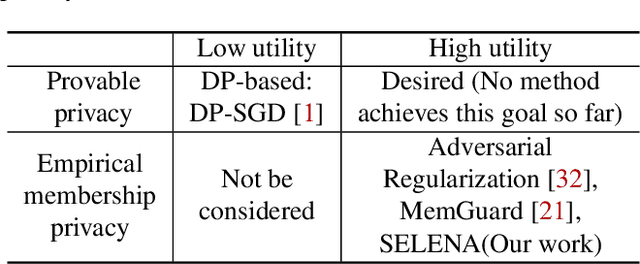

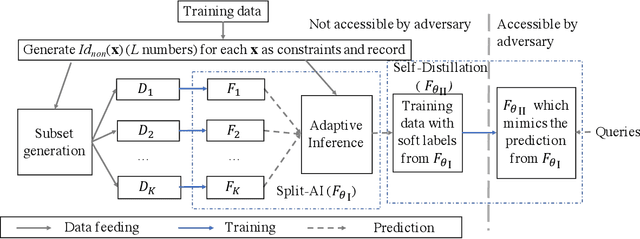
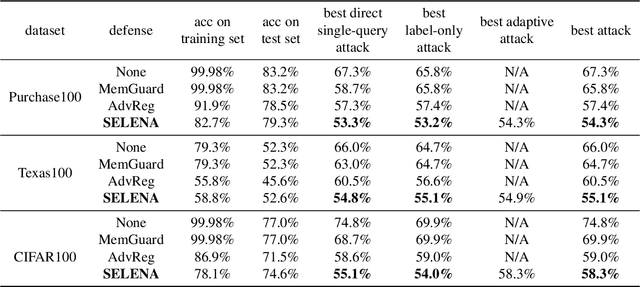
Membership inference attacks are a key measure to evaluate privacy leakage in machine learning (ML) models. These attacks aim to distinguish training members from non-members by exploiting differential behavior of the models on member and non-member inputs. The goal of this work is to train ML models that have high membership privacy while largely preserving their utility; we therefore aim for an empirical membership privacy guarantee as opposed to the provable privacy guarantees provided by techniques like differential privacy, as such techniques are shown to deteriorate model utility. Specifically, we propose a new framework to train privacy-preserving models that induces similar behavior on member and non-member inputs to mitigate membership inference attacks. Our framework, called SELENA, has two major components. The first component and the core of our defense is a novel ensemble architecture for training. This architecture, which we call Split-AI, splits the training data into random subsets, and trains a model on each subset of the data. We use an adaptive inference strategy at test time: our ensemble architecture aggregates the outputs of only those models that did not contain the input sample in their training data. We prove that our Split-AI architecture defends against a large family of membership inference attacks, however, it is susceptible to new adaptive attacks. Therefore, we use a second component in our framework called Self-Distillation to protect against such stronger attacks. The Self-Distillation component (self-)distills the training dataset through our Split-AI ensemble, without using any external public datasets. Through extensive experiments on major benchmark datasets we show that SELENA presents a superior trade-off between membership privacy and utility compared to the state of the art.
FSL: Federated Supermask Learning
Oct 08, 2021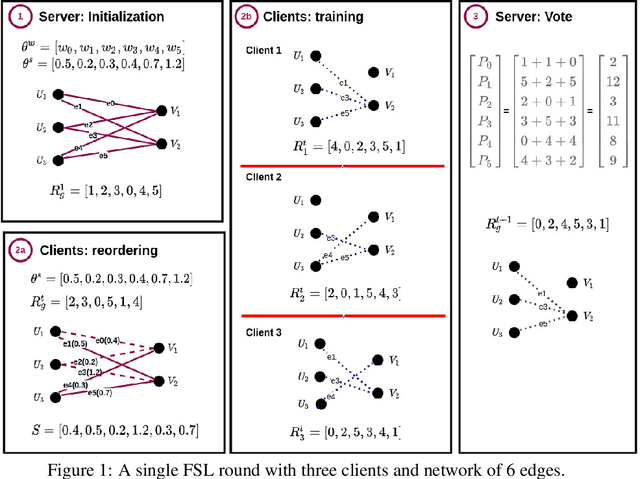
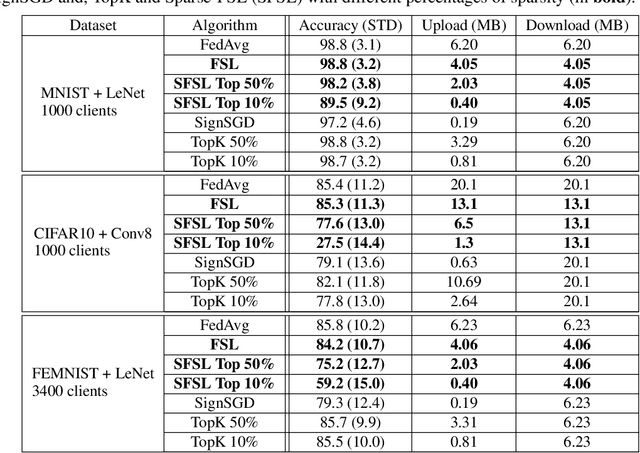
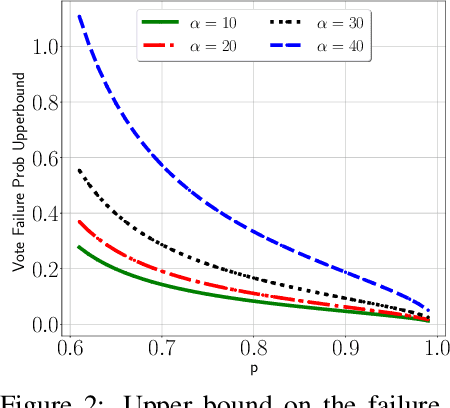
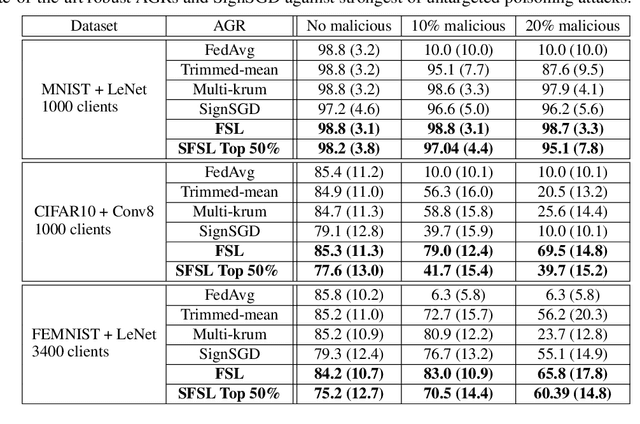
Federated learning (FL) allows multiple clients with (private) data to collaboratively train a common machine learning model without sharing their private training data. In-the-wild deployment of FL faces two major hurdles: robustness to poisoning attacks and communication efficiency. To address these concurrently, we propose Federated Supermask Learning (FSL). FSL server trains a global subnetwork within a randomly initialized neural network by aggregating local subnetworks of all collaborating clients. FSL clients share local subnetworks in the form of rankings of network edges; more useful edges have higher ranks. By sharing integer rankings, instead of float weights, FSL restricts the space available to craft effective poisoning updates, and by sharing subnetworks, FSL reduces the communication cost of training. We show theoretically and empirically that FSL is robust by design and also significantly communication efficient; all this without compromising clients' privacy. Our experiments demonstrate the superiority of FSL in real-world FL settings; in particular, (1) FSL achieves similar performances as state-of-the-art FedAvg with significantly lower communication costs: for CIFAR10, FSL achieves same performance as Federated Averaging while reducing communication cost by ~35%. (2) FSL is substantially more robust to poisoning attacks than state-of-the-art robust aggregation algorithms. We have released the code for reproducibility.
Back to the Drawing Board: A Critical Evaluation of Poisoning Attacks on Federated Learning
Aug 23, 2021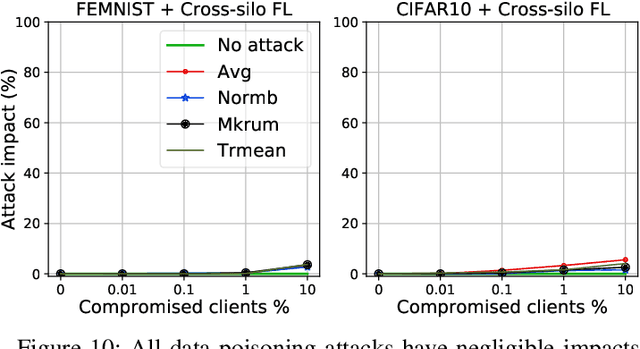
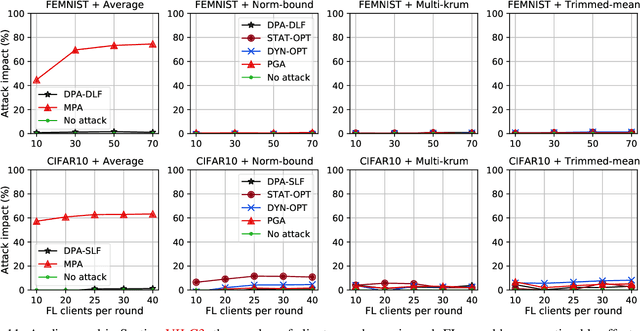
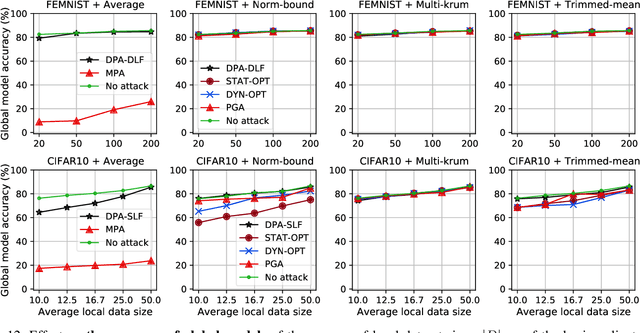
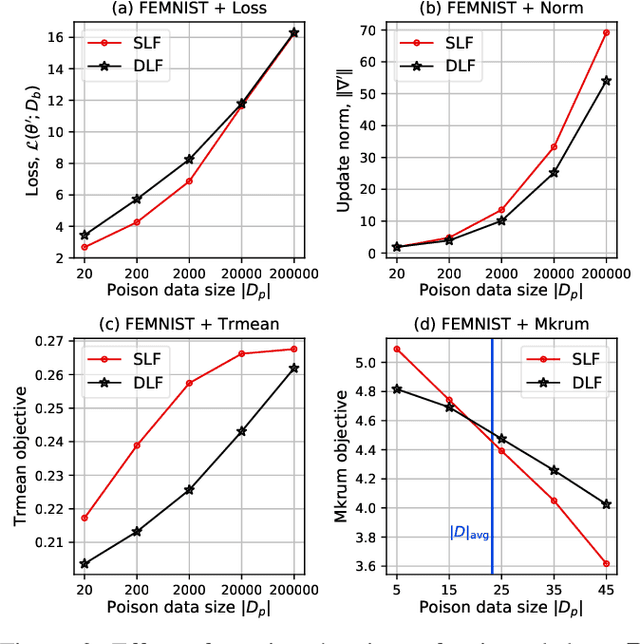
While recent works have indicated that federated learning (FL) is vulnerable to poisoning attacks by compromised clients, we show that these works make a number of unrealistic assumptions and arrive at somewhat misleading conclusions. For instance, they often use impractically high percentages of compromised clients or assume unrealistic capabilities for the adversary. We perform the first critical analysis of poisoning attacks under practical production FL environments by carefully characterizing the set of realistic threat models and adversarial capabilities. Our findings are rather surprising: contrary to the established belief, we show that FL, even without any defenses, is highly robust in practice. In fact, we go even further and propose novel, state-of-the-art poisoning attacks under two realistic threat models, and show via an extensive set of experiments across three benchmark datasets how (in)effective poisoning attacks are, especially when simple defense mechanisms are used. We correct previous misconceptions and give concrete guidelines that we hope will encourage our community to conduct more accurate research in this space and build stronger (and more realistic) attacks and defenses.
GECKO: Reconciling Privacy, Accuracy and Efficiency in Embedded Deep Learning
Oct 02, 2020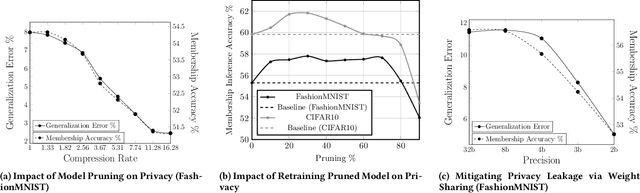
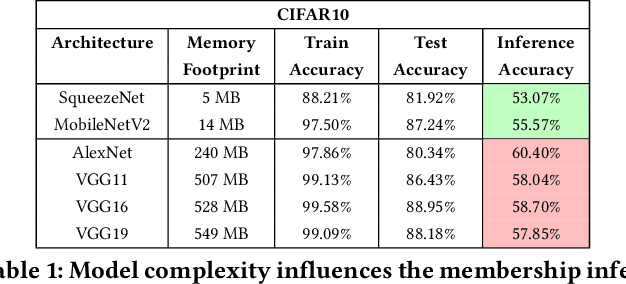
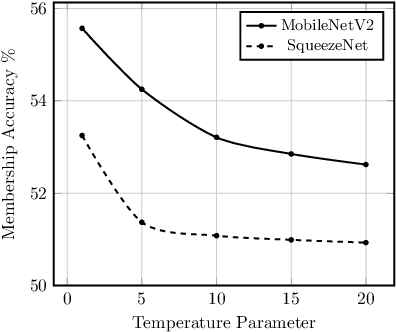
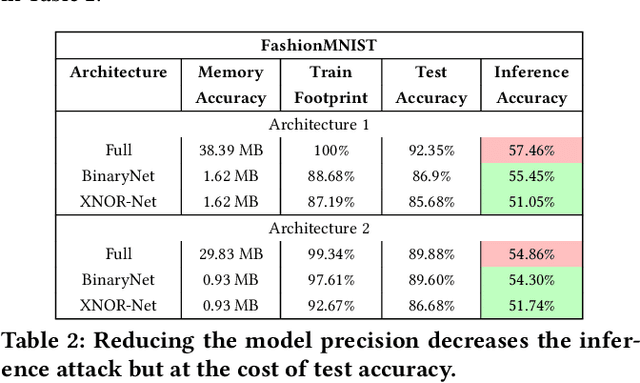
Embedded systems demand on-device processing of data using Neural Networks (NNs) while conforming to the memory, power and computation constraints, leading to an efficiency and accuracy tradeoff. To bring NNs to edge devices, several optimizations such as model compression through pruning, quantization, and off-the-shelf architectures with efficient design have been extensively adopted. These algorithms when deployed to real world sensitive applications, requires to resist inference attacks to protect privacy of users training data. However, resistance against inference attacks is not accounted for designing NN models for IoT. In this work, we analyse the three-dimensional privacy-accuracy-efficiency tradeoff in NNs for IoT devices and propose Gecko training methodology where we explicitly add resistance to private inferences as a design objective. We optimize the inference-time memory, computation, and power constraints of embedded devices as a criterion for designing NN architecture while also preserving privacy. We choose quantization as design choice for highly efficient and private models. This choice is driven by the observation that compressed models leak more information compared to baseline models while off-the-shelf efficient architectures indicate poor efficiency and privacy tradeoff. We show that models trained using Gecko methodology are comparable to prior defences against black-box membership attacks in terms of accuracy and privacy while providing efficiency.
Cronus: Robust and Heterogeneous Collaborative Learning with Black-Box Knowledge Transfer
Dec 24, 2019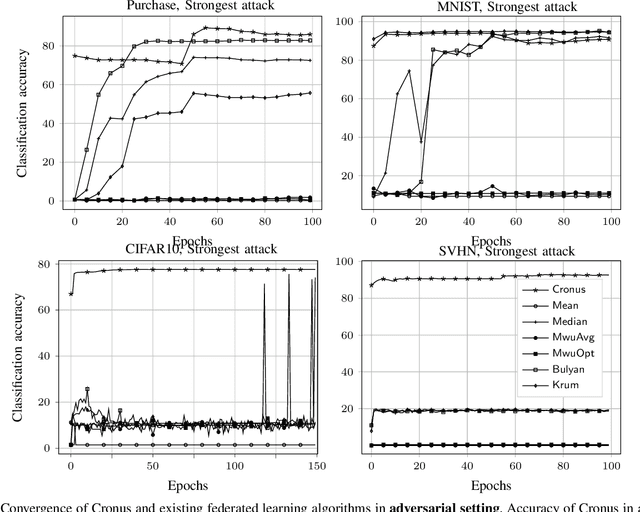
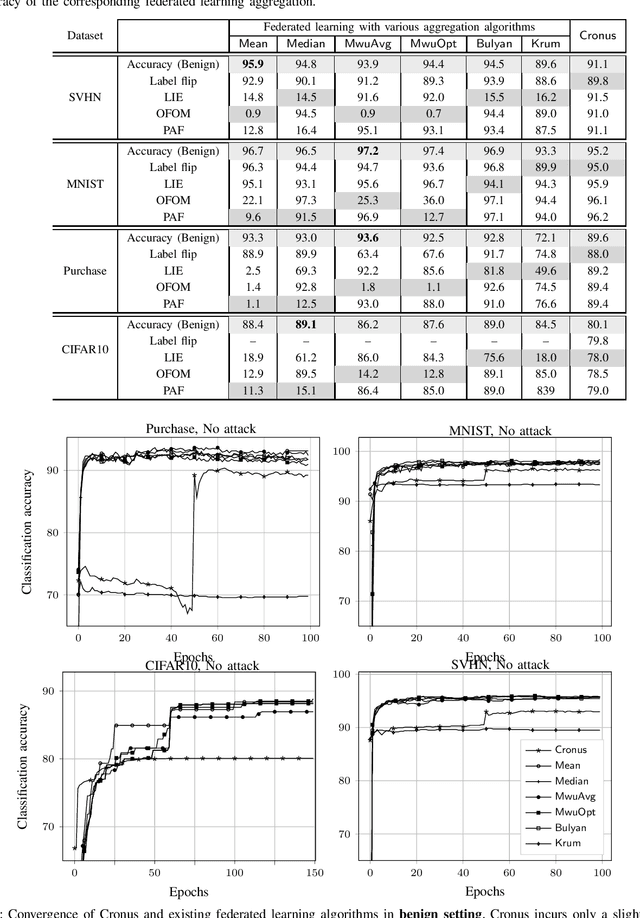
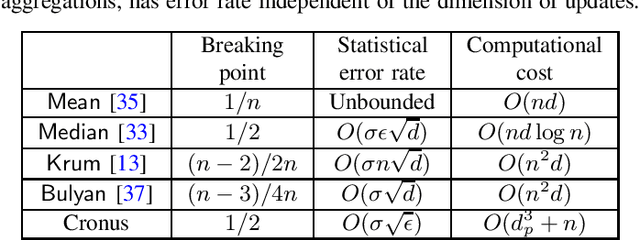
Collaborative (federated) learning enables multiple parties to train a model without sharing their private data, but through repeated sharing of the parameters of their local models. Despite its advantages, this approach has many known privacy and security weaknesses and performance overhead, in addition to being limited only to models with homogeneous architectures. Shared parameters leak a significant amount of information about the local (and supposedly private) datasets. Besides, federated learning is severely vulnerable to poisoning attacks, where some participants can adversarially influence the aggregate parameters. Large models, with high dimensional parameter vectors, are in particular highly susceptible to privacy and security attacks: curse of dimensionality in federated learning. We argue that sharing parameters is the most naive way of information exchange in collaborative learning, as they open all the internal state of the model to inference attacks, and maximize the model's malleability by stealthy poisoning attacks. We propose Cronus, a robust collaborative machine learning framework. The simple yet effective idea behind designing Cronus is to control, unify, and significantly reduce the dimensions of the exchanged information between parties, through robust knowledge transfer between their black-box local models. We evaluate all existing federated learning algorithms against poisoning attacks, and we show that Cronus is the only secure method, due to its tight robustness guarantee. Treating local models as black-box, reduces the information leakage through models, and enables us using existing privacy-preserving algorithms that mitigate the risk of information leakage through the model's output (predictions). Cronus also has a significantly lower sample complexity, compared to federated learning, which does not bind its security to the number of participants.
Reconciling Utility and Membership Privacy via Knowledge Distillation
Jun 15, 2019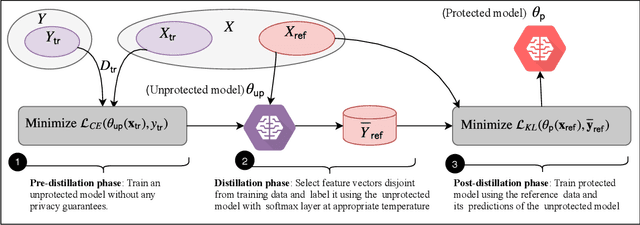
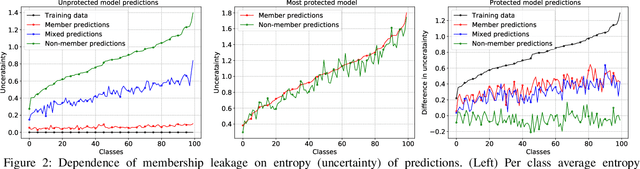
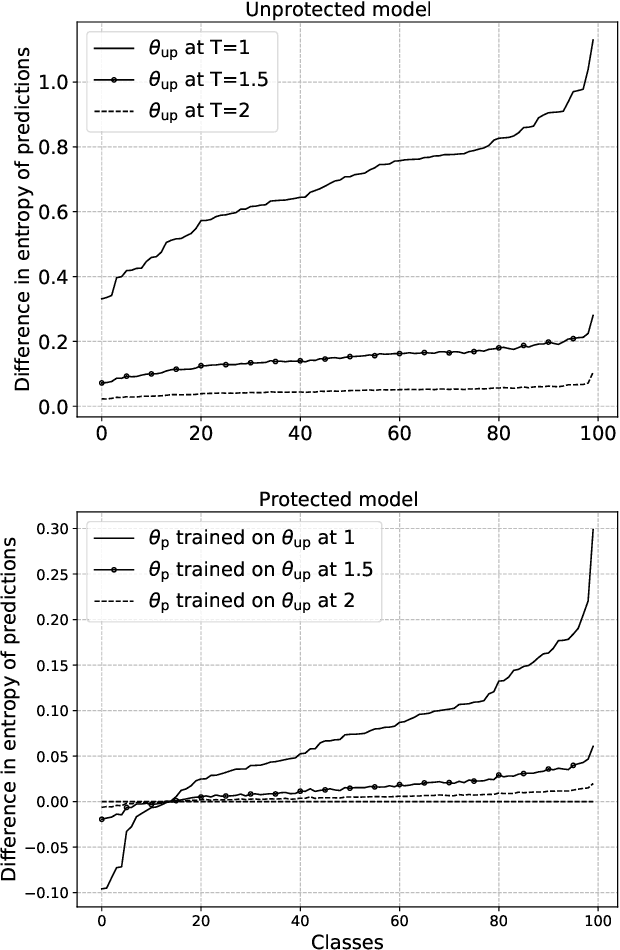
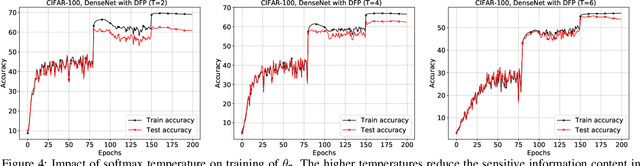
Large capacity machine learning models are prone to membership inference attacks in which an adversary aims to infer whether a particular data sample is a member of the target model's training dataset. Such membership inferences can lead to serious privacy violations as machine learning models are often trained using privacy-sensitive data such as medical records and controversial user opinions. Recently defenses against membership inference attacks are developed, in particular, based on differential privacy and adversarial regularization; unfortunately, such defenses highly impact the classification accuracy of the underlying machine learning models. In this work, we present a new defense against membership inference attacks that preserves the utility of the target machine learning models significantly better than prior defenses. Our defense, called distillation for membership privacy (DMP), leverages knowledge distillation, a model compression technique, to train machine learning models with membership privacy. We use different techniques in the DMP to maximize its membership privacy with minor degradation to utility. DMP works effectively against the attackers with either a whitebox or blackbox access to the target model. We evaluate DMP's performance through extensive experiments on different deep neural networks and using various benchmark datasets. We show that DMP provides a significantly better tradeoff between inference resilience and classification performance than state-of-the-art membership inference defenses. For instance, a DMP-trained DenseNet provides a classification accuracy of 65.3\% for a 54.4\% (54.7\%) blackbox (whitebox) membership inference attack accuracy, while an adversarially regularized DenseNet provides a classification accuracy of only 53.7\% for a (much worse) 68.7\% (69.5\%) blackbox (whitebox) membership inference attack accuracy.