 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYDRA-FL: Hybrid Knowledge Distillation for Robust and Accurate Federated Learning
Sep 30, 2024



Data heterogeneity among Federated Learning (FL) users poses a significant challenge, resulting in reduced global model performance. The community has designed various techniques to tackle this issue, among which Knowledge Distillation (KD)-based techniques are common. While these techniques effectively improve performance under high heterogeneity, they inadvertently cause higher accuracy degradation under model poisoning attacks (known as attack amplification). This paper presents a case study to reveal this critical vulnerability in KD-based FL systems. We show why KD causes this issue through empirical evidence and use it as motivation to design a hybrid distillation technique. We introduce a novel algorithm, Hybrid Knowledge Distillation for Robust and Accurate FL (HYDRA-FL), which reduces the impact of attacks in attack scenarios by offloading some of the KD loss to a shallow layer via an auxiliary classifier. We model HYDRA-FL as a generic framework and adapt it to two KD-based FL algorithms, FedNTD and MOON. Using these two as case studies, we demonstrate that our technique outperforms baselines in attack settings while maintaining comparable performance in benign settings.
Security Analysis of SplitFed Learning
Dec 04, 2022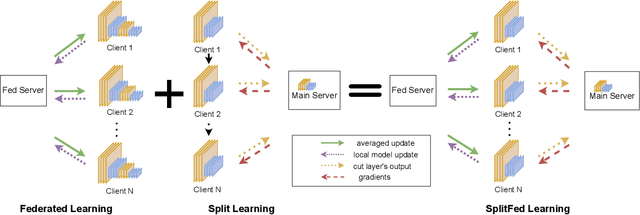
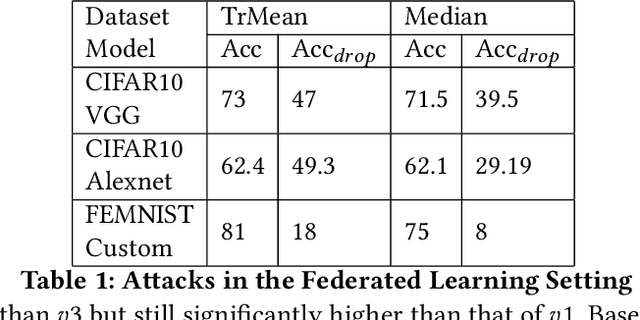
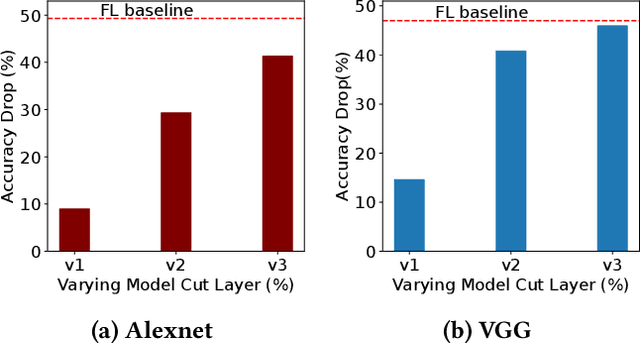
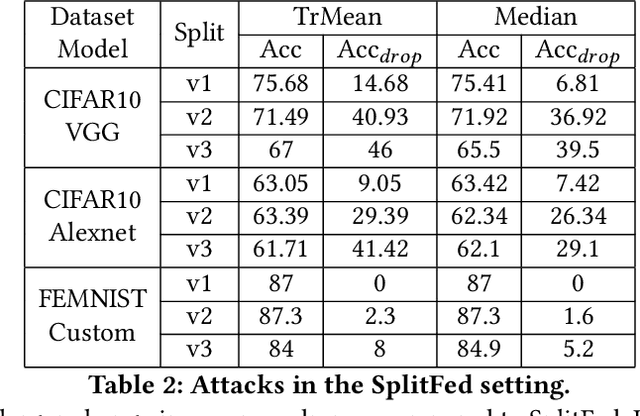
Split Learning (SL) and Federated Learning (FL) are two prominent distributed collaborative learning techniques that maintain data privacy by allowing clients to never share their private data with other clients and servers, and fined extensive IoT applications in smart healthcare, smart cities, and smart industry. Prior work has extensively explored the security vulnerabilities of FL in the form of poisoning attacks. To mitigate the effect of these attacks, several defenses have also been proposed. Recently, a hybrid of both learning techniques has emerged (commonly known as SplitFed) that capitalizes on their advantages (fast training) and eliminates their intrinsic disadvantages (centralized model updates). In this paper, we perform the first ever empirical analysis of SplitFed's robustness to strong model poisoning attacks. We observe that the model updates in SplitFed have significantly smaller dimensionality as compared to FL that is known to have the curse of dimensionality. We show that large models that have higher dimensionality are more susceptible to privacy and security attacks, whereas the clients in SplitFed do not have the complete model and have lower dimensionality, making them more robust to existing model poisoning attacks. Our results show that the accuracy reduction due to the model poisoning attack is 5x lower for SplitFed compared to FL.