 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermissioned LLMs: Enforcing Access Control in Large Language Models
May 28, 2025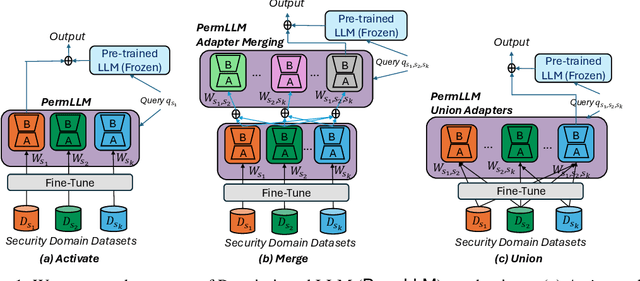

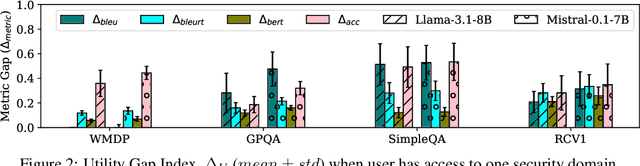
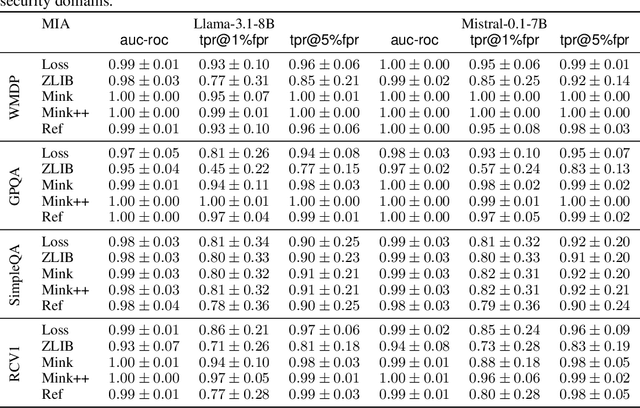
In enterprise settings, organizational data is segregated, siloed and carefully protected by elaborate access control frameworks. These access control structures can completely break down if an LLM fine-tuned on the siloed data serves requests, for downstream tasks, from individuals with disparate access privileges. We propose Permissioned LLMs (PermLLM), a new class of LLMs that superimpose the organizational data access control structures on query responses they generate. We formalize abstractions underpinning the means to determine whether access control enforcement happens correctly over LLM query responses. Our formalism introduces the notion of a relevant response that can be used to prove whether a PermLLM mechanism has been implemented correctly. We also introduce a novel metric, called access advantage, to empirically evaluate the efficacy of a PermLLM mechanism. We introduce three novel PermLLM mechanisms that build on Parameter Efficient Fine-Tuning to achieve the desired access control. We furthermore present two instantiations of access advantage--(i) Domain Distinguishability Index (DDI) based on Membership Inference Attacks, and (ii) Utility Gap Index (UGI) based on LLM utility evaluation. We demonstrate the efficacy of our PermLLM mechanisms through extensive experiments on four public datasets (GPQA, RCV1, SimpleQA, and WMDP), in addition to evaluating the validity of DDI and UGI metrics themselves for quantifying access control in LLMs.
Semantic Membership Inference Attack against Large Language Models
Jun 14, 2024Membership Inference Attacks (MIAs) determine whether a specific data point was included in the training set of a target model. In this paper, we introduce the Semantic Membership Inference Attack (SMIA), a novel approach that enhances MIA performance by leveraging the semantic content of inputs and their perturbations. SMIA trains a neural network to analyze the target model's behavior on perturbed inputs, effectively capturing variations in output probability distributions between members and non-members. We conduct comprehensive evaluations on the Pythia and GPT-Neo model families using the Wikipedia dataset. Our results show that SMIA significantly outperforms existing MIAs; for instance, SMIA achieves an AUC-ROC of 67.39% on Pythia-12B, compared to 58.90% by the second-best attack.
Fake or Compromised? Making Sense of Malicious Clients in Federated Learning
Mar 10, 2024



Federated learning (FL) is a distributed machine learning paradigm that enables training models on decentralized data. The field of FL security against poisoning attacks is plagued with confusion due to the proliferation of research that makes different assumptions about the capabilities of adversaries and the adversary models they operate under. Our work aims to clarify this confusion by presenting a comprehensive analysis of the various poisoning attacks and defensive aggregation rules (AGRs) proposed in the literature, and connecting them under a common framework. To connect existing adversary models, we present a hybrid adversary model, which lies in the middle of the spectrum of adversaries, where the adversary compromises a few clients, trains a generative (e.g., DDPM) model with their compromised samples, and generates new synthetic data to solve an optimization for a stronger (e.g., cheaper, more practical) attack against different robust aggregation rules. By presenting the spectrum of FL adversaries, we aim to provide practitioners and researchers with a clear understanding of the different types of threats they need to consider when designing FL systems, and identify areas where further research is needed.
FedPerm: Private and Robust Federated Learning by Parameter Permutation
Aug 16, 2022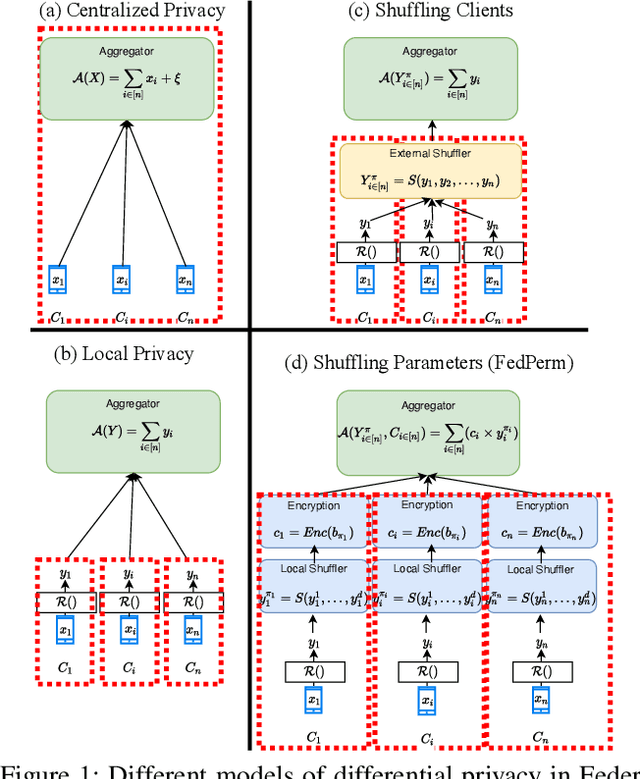

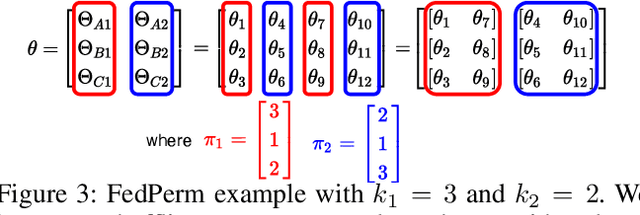
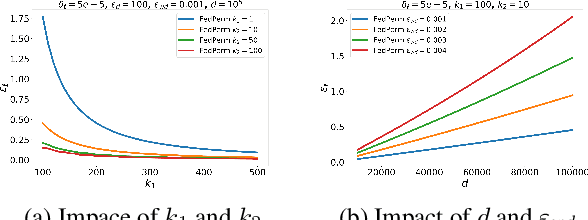
Federated Learning (FL) is a distributed learning paradigm that enables mutually untrusting clients to collaboratively train a common machine learning model. Client data privacy is paramount in FL. At the same time, the model must be protected from poisoning attacks from adversarial clients. Existing solutions address these two problems in isolation. We present FedPerm, a new FL algorithm that addresses both these problems by combining a novel intra-model parameter shuffling technique that amplifies data privacy, with Private Information Retrieval (PIR) based techniques that permit cryptographic aggregation of clients' model updates. The combination of these techniques further helps the federation server constrain parameter updates from clients so as to curtail effects of model poisoning attacks by adversarial clients. We further present FedPerm's unique hyperparameters that can be used effectively to trade off computation overheads with model utility. Our empirical evaluation on the MNIST dataset demonstrates FedPerm's effectiveness over existing Differential Privacy (DP) enforcement solutions in FL.
E2FL: Equal and Equitable Federated Learning
May 20, 2022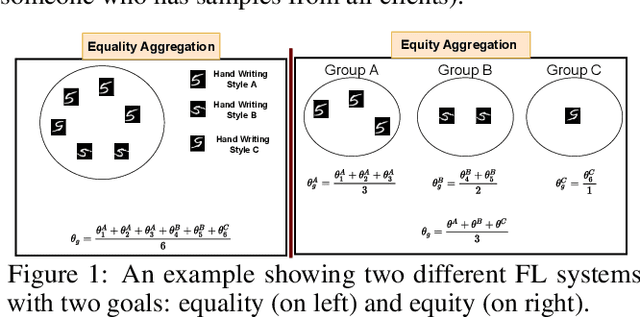


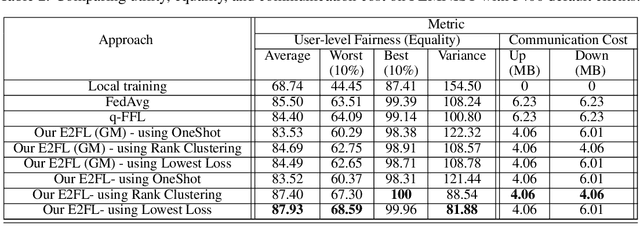
Federated Learning (FL) enables data owners to train a shared global model without sharing their private data. Unfortunately, FL is susceptible to an intrinsic fairness issue: due to heterogeneity in clients' data distributions, the final trained model can give disproportionate advantages across the participating clients. In this work, we present Equal and Equitable Federated Learning (E2FL) to produce fair federated learning models by preserving two main fairness properties, equity and equality, concurrently. We validate the efficiency and fairness of E2FL in different real-world FL applications, and show that E2FL outperforms existing baselines in terms of the resulting efficiency, fairness of different groups, and fairness among all individual clients.
FSL: Federated Supermask Learning
Oct 08, 2021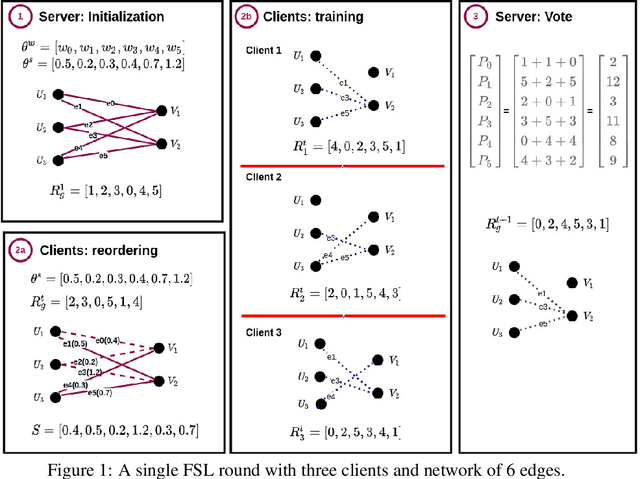
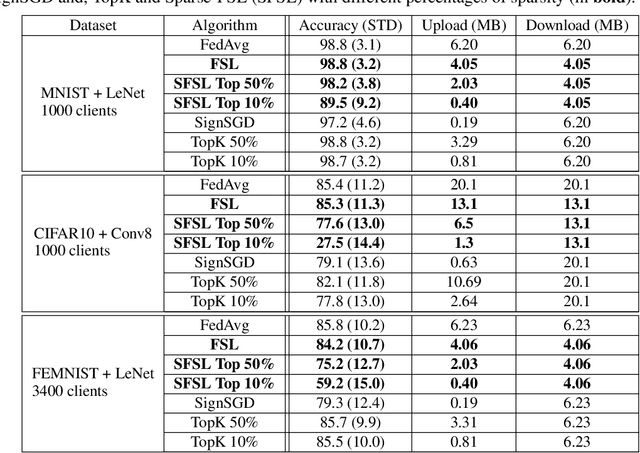
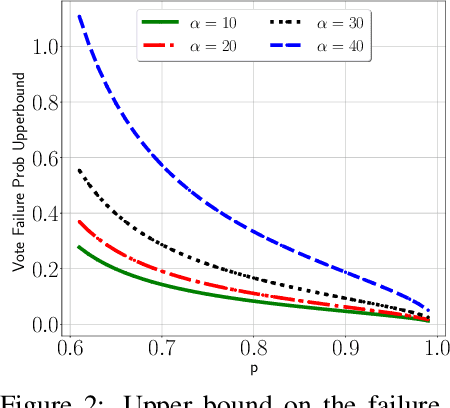
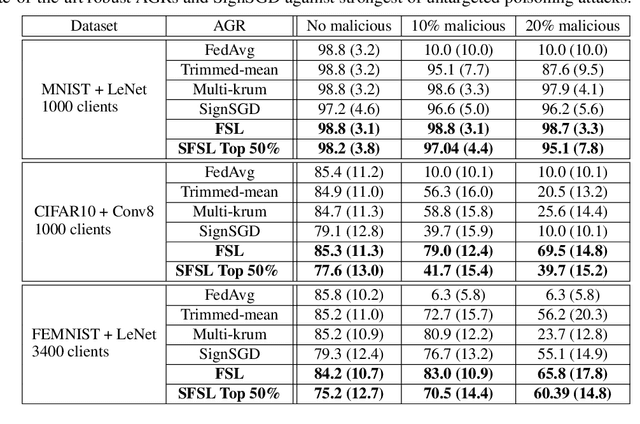
Federated learning (FL) allows multiple clients with (private) data to collaboratively train a common machine learning model without sharing their private training data. In-the-wild deployment of FL faces two major hurdles: robustness to poisoning attacks and communication efficiency. To address these concurrently, we propose Federated Supermask Learning (FSL). FSL server trains a global subnetwork within a randomly initialized neural network by aggregating local subnetworks of all collaborating clients. FSL clients share local subnetworks in the form of rankings of network edges; more useful edges have higher ranks. By sharing integer rankings, instead of float weights, FSL restricts the space available to craft effective poisoning updates, and by sharing subnetworks, FSL reduces the communication cost of training. We show theoretically and empirically that FSL is robust by design and also significantly communication efficient; all this without compromising clients' privacy. Our experiments demonstrate the superiority of FSL in real-world FL settings; in particular, (1) FSL achieves similar performances as state-of-the-art FedAvg with significantly lower communication costs: for CIFAR10, FSL achieves same performance as Federated Averaging while reducing communication cost by ~35%. (2) FSL is substantially more robust to poisoning attacks than state-of-the-art robust aggregation algorithms. We have released the code for reproducibility.