 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Selective Classification with Pairwise Queries for Binary Classification
May 28, 2026In selective classification, a model predicts the labels of data samples where it is confident, and abstains from predicting labels for samples on which it is not confident. The rejected samples are often labeled by an expert, which is expensive. The budget for the expert is best utilized when the model has low error on non-rejected samples. However, the estimate of a model's confidence might be inconsistent with the model's predictions, which can lead to high error on non-rejected points. Such situations can readily occur in in-context binary classification by LLMs. To remedy this, we propose making additional pairwise queries to the same model. These pairwise queries can detect high-error samples and be incorporated into selective classification techniques to reduce the error on non-rejected samples. Theoretically, we establish the conditions under which a simple algorithm using pairwise queries outperforms an inconsistent confidence estimate. We support this insight through extensive experiments for $1$ synthetic and $4$ in-context learning-based real binary classification datasets. In all these cases, we show that our algorithms, using pairwise queries, obtain a better accuracy-cost tradeoff than using only the raw confidence estimates, for instance, the LLM's next-token logits.
PRISM: Learning Design Knowledge from Data for Stylistic Design Improvement
Jan 16, 2026Graphic design often involves exploring different stylistic directions, which can be time-consuming for non-experts. We address this problem of stylistically improving designs based on natural language instructions. While VLMs have shown initial success in graphic design, their pretrained knowledge on styles is often too general and misaligned with specific domain data. For example, VLMs may associate minimalism with abstract designs, whereas designers emphasize shape and color choices. Our key insight is to leverage design data -- a collection of real-world designs that implicitly capture designer's principles -- to learn design knowledge and guide stylistic improvement. We propose PRISM (PRior-Informed Stylistic Modification) that constructs and applies a design knowledge base through three stages: (1) clustering high-variance designs to capture diversity within a style, (2) summarizing each cluster into actionable design knowledge, and (3) retrieving relevant knowledge during inference to enable style-aware improvement. Experiments on the Crello dataset show that PRISM achieves the highest average rank of 1.49 (closer to 1 is better) over baselines in style alignment. User studies further validate these results, showing that PRISM is consistently preferred by designers.
Learning to Reason in LLMs by Expectation Maximization
Dec 23, 2025

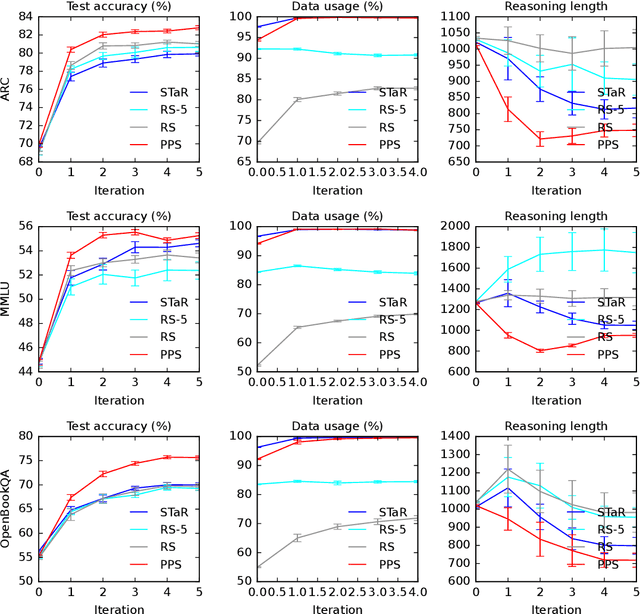
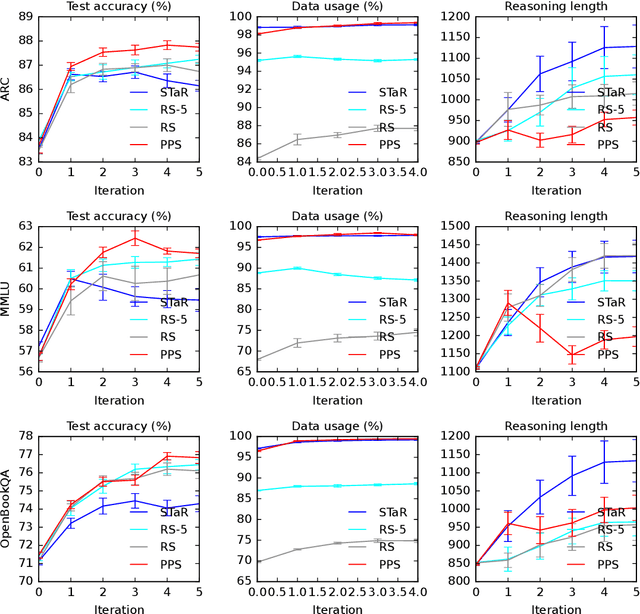
Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive an expectation-maximization (EM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution that generates rationales that justify correct answers. We instantiate and compare several sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR. Our experiments on the ARC, MMLU, and OpenBookQA datasets with the Llama and Qwen models show that the sampling scheme can significantly affect the accuracy of learned reasoning models. Despite its simplicity, we observe that PPS outperforms the other sampling schemes.
Annotation Efficiency: Identifying Hard Samples via Blocked Sparse Linear Bandits
Oct 26, 2024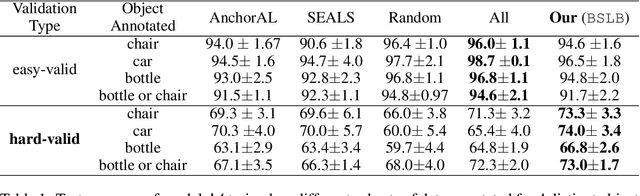
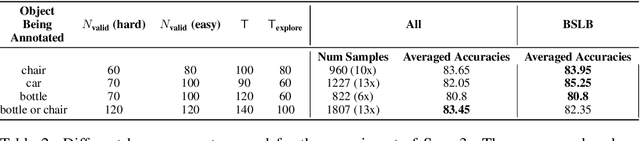
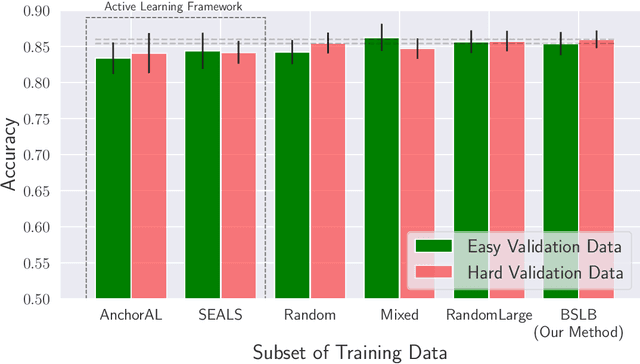
This paper considers the problem of annotating datapoints using an expert with only a few annotation rounds in a label-scarce setting. We propose soliciting reliable feedback on difficulty in annotating a datapoint from the expert in addition to ground truth label. Existing literature in active learning or coreset selection turns out to be less relevant to our setting since they presume the existence of a reliable trained model, which is absent in the label-scarce regime. However, the literature on coreset selection emphasizes the presence of difficult data points in the training set to perform supervised learning in downstream tasks (Mindermann et al., 2022). Therefore, for a given fixed annotation budget of $\mathsf{T}$ rounds, we model the sequential decision-making problem of which (difficult) datapoints to choose for annotation in a sparse linear bandits framework with the constraint that no arm can be pulled more than once (blocking constraint). With mild assumptions on the datapoints, our (computationally efficient) Explore-Then-Commit algorithm BSLB achieves a regret guarantee of $\widetilde{\mathsf{O}}(k^{\frac{1}{3}} \mathsf{T}^{\frac{2}{3}} +k^{-\frac{1}{2}} \beta_k + k^{-\frac{1}{12}} \beta_k^{\frac{1}{2}}\mathsf{T}^{\frac{5}{6}})$ where the unknown parameter vector has tail magnitude $\beta_k$ at sparsity level $k$. To this end, we show offline statistical guarantees of Lasso estimator with mild Restricted Eigenvalue (RE) condition that is also robust to sparsity. Finally, we propose a meta-algorithm C-BSLB that does not need knowledge of the optimal sparsity parameters at a no-regret cost. We demonstrate the efficacy of our BSLB algorithm for annotation in the label-scarce setting for an image classification task on the PASCAL-VOC dataset, where we use real-world annotation difficulty scores.
Thinking Forward: Memory-Efficient Federated Finetuning of Language Models
May 24, 2024Finetuning large language models (LLMs) in federated learning (FL) settings has become important as it allows resource-constrained devices to finetune a model using private data. However, finetuning LLMs using backpropagation requires excessive memory (especially from intermediate activations) for resource-constrained devices. While Forward-mode Auto-Differentiation (AD) can reduce memory footprint from activations, we observe that directly applying it to LLM finetuning results in slow convergence and poor accuracy. This work introduces Spry, an FL algorithm that splits trainable weights of an LLM among participating clients, such that each client computes gradients using Forward-mode AD that are closer estimates of the true gradients. Spry achieves a low memory footprint, high accuracy, and fast convergence. We theoretically show that the global gradients in Spry are unbiased estimates of true global gradients for homogeneous data distributions across clients, while heterogeneity increases bias of the estimates. We also derive Spry's convergence rate, showing that the gradients decrease inversely proportional to the number of FL rounds, indicating the convergence up to the limits of heterogeneity. Empirically, Spry reduces the memory footprint during training by 1.4-7.1$\times$ in contrast to backpropagation, while reaching comparable accuracy, across a wide range of language tasks, models, and FL settings. Spry reduces the convergence time by 1.2-20.3$\times$ and achieves 5.2-13.5\% higher accuracy against state-of-the-art zero-order methods. When finetuning Llama2-7B with LoRA, compared to the peak memory usage of 33.9GB of backpropagation, Spry only consumes 6.2GB of peak memory. For OPT13B, the reduction is from 76.5GB to 10.8GB. Spry makes feasible previously impossible FL deployments on commodity mobile and edge devices. Source code is available at https://github.com/Astuary/Spry.
Fake or Compromised? Making Sense of Malicious Clients in Federated Learning
Mar 10, 2024



Federated learning (FL) is a distributed machine learning paradigm that enables training models on decentralized data. The field of FL security against poisoning attacks is plagued with confusion due to the proliferation of research that makes different assumptions about the capabilities of adversaries and the adversary models they operate under. Our work aims to clarify this confusion by presenting a comprehensive analysis of the various poisoning attacks and defensive aggregation rules (AGRs) proposed in the literature, and connecting them under a common framework. To connect existing adversary models, we present a hybrid adversary model, which lies in the middle of the spectrum of adversaries, where the adversary compromises a few clients, trains a generative (e.g., DDPM) model with their compromised samples, and generates new synthetic data to solve an optimization for a stronger (e.g., cheaper, more practical) attack against different robust aggregation rules. By presenting the spectrum of FL adversaries, we aim to provide practitioners and researchers with a clear understanding of the different types of threats they need to consider when designing FL systems, and identify areas where further research is needed.
Delivery Optimized Discovery in Behavioral User Segmentation under Budget Constrain
Feb 04, 2024



Users' behavioral footprints online enable firms to discover behavior-based user segments (or, segments) and deliver segment specific messages to users. Following the discovery of segments, delivery of messages to users through preferred media channels like Facebook and Google can be challenging, as only a portion of users in a behavior segment find match in a medium, and only a fraction of those matched actually see the message (exposure). Even high quality discovery becomes futile when delivery fails. Many sophisticated algorithms exist for discovering behavioral segments; however, these ignore the delivery component. The problem is compounded because (i) the discovery is performed on the behavior data space in firms' data (e.g., user clicks), while the delivery is predicated on the static data space (e.g., geo, age) as defined by media; and (ii) firms work under budget constraint. We introduce a stochastic optimization based algorithm for delivery optimized discovery of behavioral user segmentation and offer new metrics to address the joint optimization. We leverage optimization under a budget constraint for delivery combined with a learning-based component for discovery. Extensive experiments on a public dataset from Google and a proprietary dataset show the effectiveness of our approach by simultaneously improving delivery metrics, reducing budget spend and achieving strong predictive performance in discovery.
Flow: Per-Instance Personalized Federated Learning Through Dynamic Routing
Nov 28, 2022
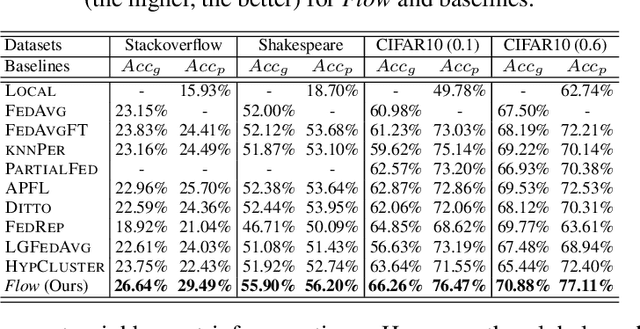


Personalization in Federated Learning (FL) aims to modify a collaboratively trained global model according to each client. Current approaches to personalization in FL are at a coarse granularity, i.e. all the input instances of a client use the same personalized model. This ignores the fact that some instances are more accurately handled by the global model due to better generalizability. To address this challenge, this work proposes Flow, a fine-grained stateless personalized FL approach. Flow creates dynamic personalized models by learning a routing mechanism that determines whether an input instance prefers the local parameters or its global counterpart. Thus, Flow introduces per-instance routing in addition to leveraging per-client personalization to improve accuracies at each client. Further, Flow is stateless which makes it unnecessary for a client to retain its personalized state across FL rounds. This makes Flow practical for large-scale FL settings and friendly to newly joined clients. Evaluations on Stackoverflow, Reddit, and EMNIST datasets demonstrate the superiority in prediction accuracy of Flow over state-of-the-art non-personalized and only per-client personalized approaches to FL.
Federated Learning with Personalization Layers
Dec 02, 2019
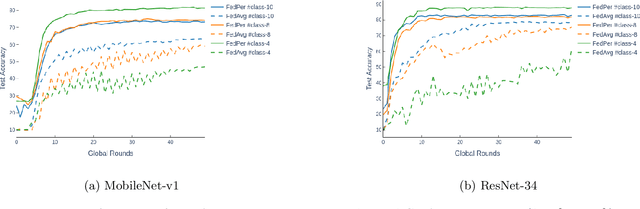
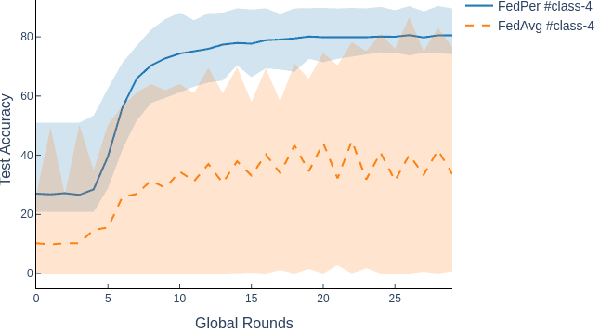
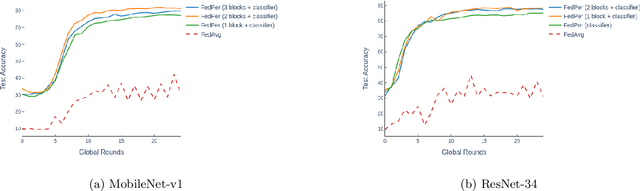
The emerging paradigm of federated learning strives to enable collaborative training of machine learning models on the network edge without centrally aggregating raw data and hence, improving data privacy. This sharply deviates from traditional machine learning and necessitates the design of algorithms robust to various sources of heterogeneity. Specifically, statistical heterogeneity of data across user devices can severely degrade the performance of standard federated averaging for traditional machine learning applications like personalization with deep learning. This paper pro-posesFedPer, a base + personalization layer approach for federated training of deep feedforward neural networks, which can combat the ill-effects of statistical heterogeneity. We demonstrate effectiveness ofFedPerfor non-identical data partitions ofCIFARdatasetsand on a personalized image aesthetics dataset from Flickr.
Data-Driven Compression of Convolutional Neural Networks
Nov 28, 2019
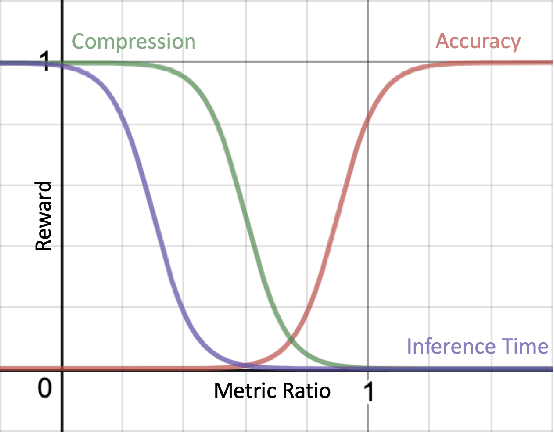
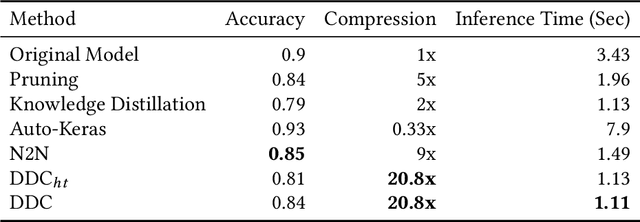
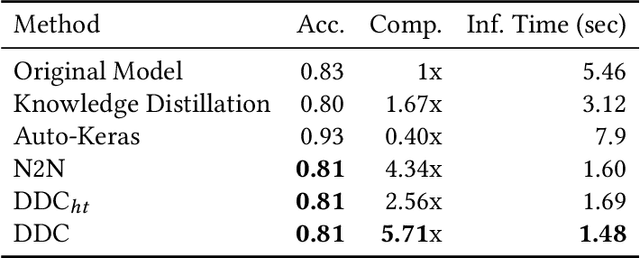
Deploying trained convolutional neural networks (CNNs) to mobile devices is a challenging task because of the simultaneous requirements of the deployed model to be fast, lightweight and accurate. Designing and training a CNN architecture that does well on all three metrics is highly non-trivial and can be very time-consuming if done by hand. One way to solve this problem is to compress the trained CNN models before deploying to mobile devices. This work asks and answers three questions on compressing CNN models automatically: a) How to control the trade-off between speed, memory and accuracy during model compression? b) In practice, a deployed model may not see all classes and/or may not need to produce all class labels. Can this fact be used to improve the trade-off? c) How to scale the compression algorithm to execute within a reasonable amount of time for many deployments? The paper demonstrates that a model compression algorithm utilizing reinforcement learning with architecture search and knowledge distillation can answer these questions in the affirmative. Experimental results are provided for current state-of-the-art CNN model families for image feature extraction like VGG and ResNet with CIFAR datasets.