 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATTO: Balancing Preferences and Confidence in Language Models
Jan 30, 2026Large language models (LLMs) often make accurate next token predictions but their confidence in these predictions can be poorly calibrated: high-confidence predictions are frequently wrong, and low-confidence predictions may be correct. This miscalibration is exacerbated by preference-based alignment methods breaking the link between predictive probability and correctness. We introduce a Calibration Aware Token-level Training Objective (CATTO), a calibration-aware objective that aligns predicted confidence with empirical prediction correctness, which can be combined with the original preference optimization objectives. Empirically, CATTO reduces Expected Calibration Error (ECE) by 2.22%-7.61% in-distribution and 1.46%-10.44% out-of-distribution compared to direct preference optimization (DPO), and by 0.22%-1.24% in-distribution and 1.23%-5.07% out-of-distribution compared to the strongest DPO baseline. This improvement in confidence does not come at a cost of losing task accuracy, where CATTO maintains or slightly improves multiple-choice question-answering accuracy on five datasets. We also introduce Confidence@k, a test-time scaling mechanism leveraging calibrated token probabilities for Bayes-optimal selection of output tokens.
Atom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025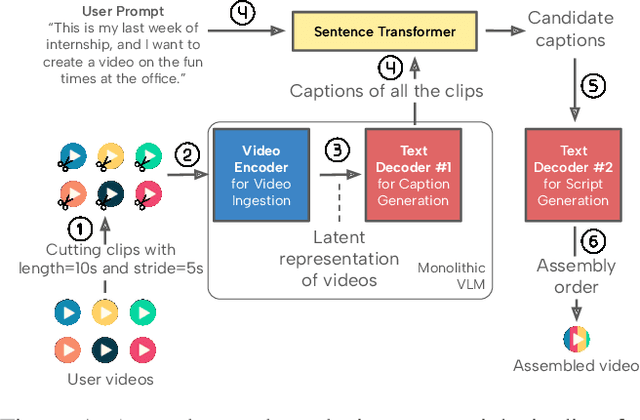
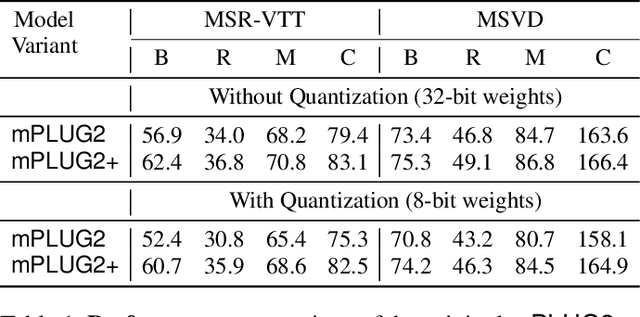
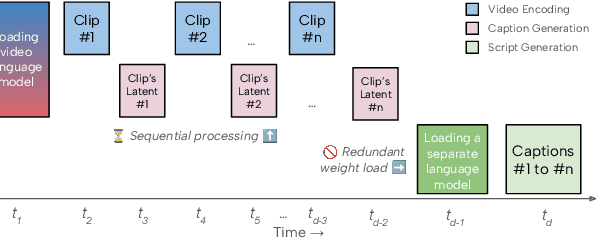
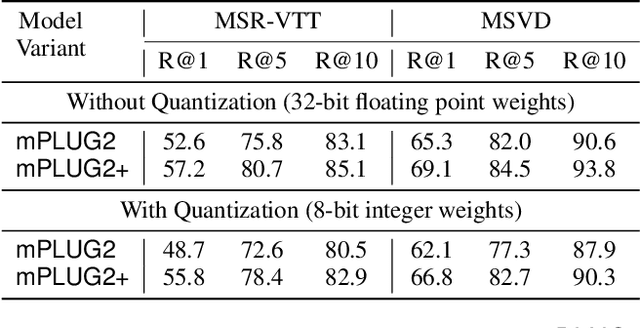
Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
Thinking Forward: Memory-Efficient Federated Finetuning of Language Models
May 24, 2024Finetuning large language models (LLMs) in federated learning (FL) settings has become important as it allows resource-constrained devices to finetune a model using private data. However, finetuning LLMs using backpropagation requires excessive memory (especially from intermediate activations) for resource-constrained devices. While Forward-mode Auto-Differentiation (AD) can reduce memory footprint from activations, we observe that directly applying it to LLM finetuning results in slow convergence and poor accuracy. This work introduces Spry, an FL algorithm that splits trainable weights of an LLM among participating clients, such that each client computes gradients using Forward-mode AD that are closer estimates of the true gradients. Spry achieves a low memory footprint, high accuracy, and fast convergence. We theoretically show that the global gradients in Spry are unbiased estimates of true global gradients for homogeneous data distributions across clients, while heterogeneity increases bias of the estimates. We also derive Spry's convergence rate, showing that the gradients decrease inversely proportional to the number of FL rounds, indicating the convergence up to the limits of heterogeneity. Empirically, Spry reduces the memory footprint during training by 1.4-7.1$\times$ in contrast to backpropagation, while reaching comparable accuracy, across a wide range of language tasks, models, and FL settings. Spry reduces the convergence time by 1.2-20.3$\times$ and achieves 5.2-13.5\% higher accuracy against state-of-the-art zero-order methods. When finetuning Llama2-7B with LoRA, compared to the peak memory usage of 33.9GB of backpropagation, Spry only consumes 6.2GB of peak memory. For OPT13B, the reduction is from 76.5GB to 10.8GB. Spry makes feasible previously impossible FL deployments on commodity mobile and edge devices. Source code is available at https://github.com/Astuary/Spry.
Flow: Per-Instance Personalized Federated Learning Through Dynamic Routing
Nov 28, 2022
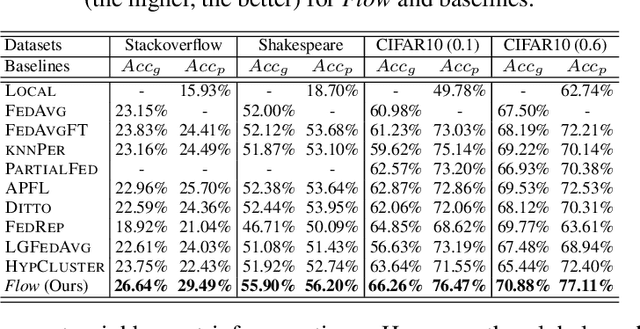


Personalization in Federated Learning (FL) aims to modify a collaboratively trained global model according to each client. Current approaches to personalization in FL are at a coarse granularity, i.e. all the input instances of a client use the same personalized model. This ignores the fact that some instances are more accurately handled by the global model due to better generalizability. To address this challenge, this work proposes Flow, a fine-grained stateless personalized FL approach. Flow creates dynamic personalized models by learning a routing mechanism that determines whether an input instance prefers the local parameters or its global counterpart. Thus, Flow introduces per-instance routing in addition to leveraging per-client personalization to improve accuracies at each client. Further, Flow is stateless which makes it unnecessary for a client to retain its personalized state across FL rounds. This makes Flow practical for large-scale FL settings and friendly to newly joined clients. Evaluations on Stackoverflow, Reddit, and EMNIST datasets demonstrate the superiority in prediction accuracy of Flow over state-of-the-art non-personalized and only per-client personalized approaches to FL.
Hierachical Delta-Attention Method for Multimodal Fusion
Nov 22, 2020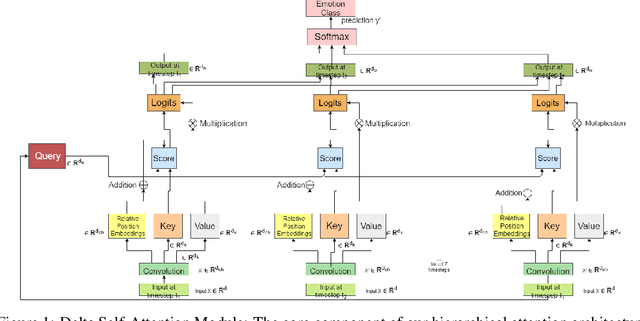
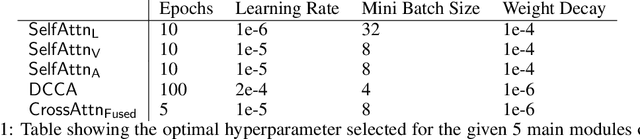
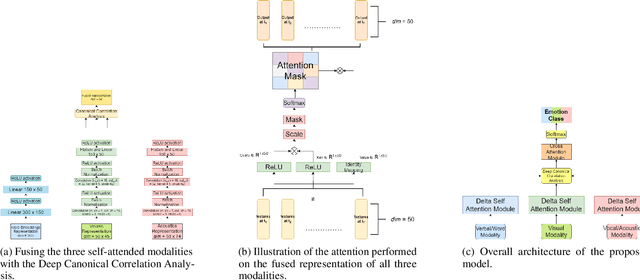
In vision and linguistics; the main input modalities are facial expressions, speech patterns, and the words uttered. The issue with analysis of any one mode of expression (Visual, Verbal or Vocal) is that lot of contextual information can get lost. This asks researchers to inspect multiple modalities to get a thorough understanding of the cross-modal dependencies and temporal context of the situation to analyze the expression. This work attempts at preserving the long-range dependencies within and across different modalities, which would be bottle-necked by the use of recurrent networks and adds the concept of delta-attention to focus on local differences per modality to capture the idiosyncrasy of different people. We explore a cross-attention fusion technique to get the global view of the emotion expressed through these delta-self-attended modalities, in order to fuse all the local nuances and global context together. The addition of attention is new to the multi-modal fusion field and currently being scrutinized for on what stage the attention mechanism should be used, this work achieves competitive accuracy for overall and per-class classification which is close to the current state-of-the-art with almost half number of parameters.
Improved Algorithm for Seamlessly Creating Infinite Loops from a Video Clip, while Preserving Variety in Textures
Nov 04, 2020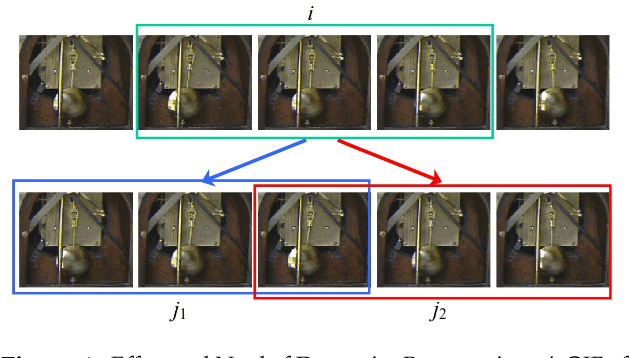
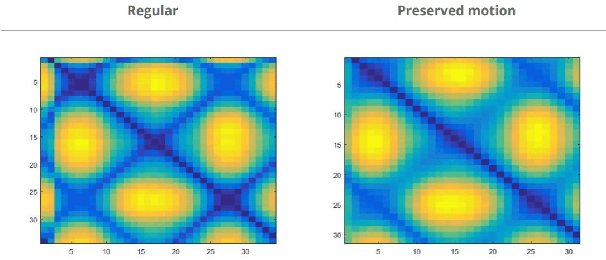


This project implements the paper "Video Textures" by Szeliski. The aim is to create a "Moving Picture" or as we popularly call it, a GIF; which is "somewhere between a photograph and a video". The idea is to input a video which has some repeated motion (the texture), such as a flag waving, rain, or a candle flame. The output is a new video that infinitely extends the original video in a seamless way. In practice, the output isn't really infinte, but is instead looped using a video player and is sufficiently long as to appear to never repeat. Our goal from this implementation was to: improve distance metric by switching from a crude sum of squared distance to most sophisticated wavelet-based distance; add intensity normalization, cross-fading and morphing to the suggested basic algorithm. We also experiment on the trade-off between variety and smoothness.
Differential Privacy and Natural Language Processing to Generate Contextually Similar Decoy Messages in Honey Encryption Scheme
Oct 29, 2020


Honey Encryption is an approach to encrypt the messages using low min-entropy keys, such as weak passwords, OTPs, PINs, credit card numbers. The ciphertext is produces, when decrypted with any number of incorrect keys, produces plausible-looking but bogus plaintext called "honey messages". But the current techniques used in producing the decoy plaintexts do not model human language entirely. A gibberish, random assortment of words is not enough to fool an attacker; that will not be acceptable and convincing, whether or not the attacker knows some information of the genuine source. In this paper, I focus on the plaintexts which are some non-numeric informative messages. In order to fool the attacker into believing that the decoy message can actually be from a certain source, we need to capture the empirical and contextual properties of the language. That is, there should be no linguistic difference between real and fake message, without revealing the structure of the real message. I employ natural language processing and generalized differential privacy to solve this problem. Mainly I focus on machine learning methods like keyword extraction, context classification, bags-of-words, word embeddings, transformers for text processing to model privacy for text documents. Then I prove the security of this approach with e-differential privacy.