 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Model Is Unfair, Are You Even Aware? Inverse Relationship Between Comprehension and Trust in Explainability Visualizations of Biased ML Models
Jul 31, 2025Systems relying on ML have become ubiquitous, but so has biased behavior within them. Research shows that bias significantly affects stakeholders' trust in systems and how they use them. Further, stakeholders of different backgrounds view and trust the same systems differently. Thus, how ML models' behavior is explained plays a key role in comprehension and trust. We survey explainability visualizations, creating a taxonomy of design characteristics. We conduct user studies to evaluate five state-of-the-art visualization tools (LIME, SHAP, CP, Anchors, and ELI5) for model explainability, measuring how taxonomy characteristics affect comprehension, bias perception, and trust for non-expert ML users. Surprisingly, we find an inverse relationship between comprehension and trust: the better users understand the models, the less they trust them. We investigate the cause and find that this relationship is strongly mediated by bias perception: more comprehensible visualizations increase people's perception of bias, and increased bias perception reduces trust. We confirm this relationship is causal: Manipulating explainability visualizations to control comprehension, bias perception, and trust, we show that visualization design can significantly (p < 0.001) increase comprehension, increase perceived bias, and reduce trust. Conversely, reducing perceived model bias, either by improving model fairness or by adjusting visualization design, significantly increases trust even when comprehension remains high. Our work advances understanding of how comprehension affects trust and systematically investigates visualization's role in facilitating responsible ML applications.
Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification
Dec 18, 2024



Formal verification using proof assistants, such as Coq, enables the creation of high-quality software. However, the verification process requires significant expertise and manual effort to write proofs. Recent work has explored automating proof synthesis using machine learning and large language models (LLMs). This work has shown that identifying relevant premises, such as lemmas and definitions, can aid synthesis. We present Rango, a fully automated proof synthesis tool for Coq that automatically identifies relevant premises and also similar proofs from the current project and uses them during synthesis. Rango uses retrieval augmentation at every step of the proof to automatically determine which proofs and premises to include in the context of its fine-tuned LLM. In this way, Rango adapts to the project and to the evolving state of the proof. We create a new dataset, CoqStoq, of 2,226 open-source Coq projects and 196,929 theorems from GitHub, which includes both training data and a curated evaluation benchmark of well-maintained projects. On this benchmark, Rango synthesizes proofs for 32.0% of the theorems, which is 29% more theorems than the prior state-of-the-art tool Tactician. Our evaluation also shows that Rango adding relevant proofs to its context leads to a 47% increase in the number of theorems proven.
Cobblestone: Iterative Automation for Formal Verification
Oct 25, 2024Formal verification using proof assistants, such as Coq, is an effective way of improving software quality, but it is expensive. Writing proofs manually requires both significant effort and expertise. Recent research has used machine learning to automatically synthesize proofs, reducing verification effort, but these tools are able to prove only a fraction of the desired software properties. We introduce Cobblestone, a new proof-synthesis approach that improves on the state of the art by taking advantage of partial progress in proof synthesis attempts. Unlike prior tools, Cobblestone can produce multiple unsuccessful proofs using a large language model (LLM), identify the working portions of those proofs, and combine them into a single, successful proof, taking advantage of internal partial progress. We evaluate Cobblestone on two benchmarks of open-source Coq projects, controlling for training data leakage in LLM datasets. Fully automatically, Cobblestone can prove 48% of the theorems, while Proverbot9001, the previous state-of-the-art, learning-based, proof-synthesis tool, can prove 17%. Cobblestone establishes a new state of the art for fully automated proof synthesis tools for Coq. We also evaluate Cobblestone in a setting where it is given external partial proof progress from oracles, serving as proxies for a human proof engineer or another tool. When the theorem is broken down into a set of subgoals and Cobblestone is given a set of relevant lemmas already proven in the project, it can prove up to 58% of the theorems. We qualitatively study the theorems Cobblestone is and is not able to prove to outline potential future research directions to further improve proof synthesis, including developing interactive, semi-automated tools. Our research shows that tools can make better use of partial progress made during proof synthesis to more effectively automate formal verification.
QEDCartographer: Automating Formal Verification Using Reward-Free Reinforcement Learning
Aug 17, 2024



Formal verification is a promising method for producing reliable software, but the difficulty of manually writing verification proofs severely limits its utility in practice. Recent methods have automated some proof synthesis by guiding a search through the proof space using a theorem prover. Unfortunately, the theorem prover provides only the crudest estimate of progress, resulting in effectively undirected search. To address this problem, we create QEDCartographer, an automated proof-synthesis tool that combines supervised and reinforcement learning to more effectively explore the proof space. QEDCartographer incorporates the proofs' branching structure, enabling reward-free search and overcoming the sparse reward problem inherent to formal verification. We evaluate QEDCartographer using the CoqGym benchmark of 68.5K theorems from 124 open-source Coq projects. QEDCartographer fully automatically proves 21.4% of the test-set theorems. Previous search-based proof-synthesis tools Tok, Tac, ASTactic, Passport, and Proverbot9001, which rely only on supervised learning, prove 9.6%, 9.8%, 10.9%, 12.5%, and 19.8%, respectively. Diva, which combines 62 tools, proves 19.2%. Comparing to the most effective prior tool, Proverbot9001, QEDCartographer produces 26% shorter proofs 27% faster, on average over the theorems both tools prove. Together, QEDCartographer and non-learning-based CoqHammer prove 31.8% of the theorems, while CoqHammer alone proves 26.6%. Our work demonstrates that reinforcement learning is a fruitful research direction for improving proof-synthesis tools' search mechanisms.
Thinking Forward: Memory-Efficient Federated Finetuning of Language Models
May 24, 2024Finetuning large language models (LLMs) in federated learning (FL) settings has become important as it allows resource-constrained devices to finetune a model using private data. However, finetuning LLMs using backpropagation requires excessive memory (especially from intermediate activations) for resource-constrained devices. While Forward-mode Auto-Differentiation (AD) can reduce memory footprint from activations, we observe that directly applying it to LLM finetuning results in slow convergence and poor accuracy. This work introduces Spry, an FL algorithm that splits trainable weights of an LLM among participating clients, such that each client computes gradients using Forward-mode AD that are closer estimates of the true gradients. Spry achieves a low memory footprint, high accuracy, and fast convergence. We theoretically show that the global gradients in Spry are unbiased estimates of true global gradients for homogeneous data distributions across clients, while heterogeneity increases bias of the estimates. We also derive Spry's convergence rate, showing that the gradients decrease inversely proportional to the number of FL rounds, indicating the convergence up to the limits of heterogeneity. Empirically, Spry reduces the memory footprint during training by 1.4-7.1$\times$ in contrast to backpropagation, while reaching comparable accuracy, across a wide range of language tasks, models, and FL settings. Spry reduces the convergence time by 1.2-20.3$\times$ and achieves 5.2-13.5\% higher accuracy against state-of-the-art zero-order methods. When finetuning Llama2-7B with LoRA, compared to the peak memory usage of 33.9GB of backpropagation, Spry only consumes 6.2GB of peak memory. For OPT13B, the reduction is from 76.5GB to 10.8GB. Spry makes feasible previously impossible FL deployments on commodity mobile and edge devices. Source code is available at https://github.com/Astuary/Spry.
Robust Image Watermarking using Stable Diffusion
Jan 08, 2024Watermarking images is critical for tracking image provenance and claiming ownership. With the advent of generative models, such as stable diffusion, able to create fake but realistic images, watermarking has become particularly important, e.g., to make generated images reliably identifiable. Unfortunately, the very same stable diffusion technology can remove watermarks injected using existing methods. To address this problem, we present a ZoDiac, which uses a pre-trained stable diffusion model to inject a watermark into the trainable latent space, resulting in watermarks that can be reliably detected in the latent vector, even when attacked. We evaluate ZoDiac on three benchmarks, MS-COCO, DiffusionDB, and WikiArt, and find that ZoDiac is robust against state-of-the-art watermark attacks, with a watermark detection rate over 98% and a false positive rate below 6.4%, outperforming state-of-the-art watermarking methods. Our research demonstrates that stable diffusion is a promising approach to robust watermarking, able to withstand even stable-diffusion-based attacks.
Baldur: Whole-Proof Generation and Repair with Large Language Models
Mar 16, 2023



Formally verifying software properties is a highly desirable but labor-intensive task. Recent work has developed methods to automate formal verification using proof assistants, such as Coq and Isabelle/HOL, e.g., by training a model to predict one proof step at a time, and using that model to search through the space of possible proofs. This paper introduces a new method to automate formal verification: We use large language models, trained on natural language text and code and fine-tuned on proofs, to generate whole proofs for theorems at once, rather than one step at a time. We combine this proof generation model with a fine-tuned repair model to repair generated proofs, further increasing proving power. As its main contributions, this paper demonstrates for the first time that: (1) Whole-proof generation using transformers is possible and is as effective as search-based techniques without requiring costly search. (2) Giving the learned model additional context, such as a prior failed proof attempt and the ensuing error message, results in proof repair and further improves automated proof generation. (3) We establish a new state of the art for fully automated proof synthesis. We reify our method in a prototype, Baldur, and evaluate it on a benchmark of 6,336 Isabelle/HOL theorems and their proofs. In addition to empirically showing the effectiveness of whole-proof generation, repair, and added context, we show that Baldur improves on the state-of-the-art tool, Thor, by automatically generating proofs for an additional 8.7% of the theorems. Together, Baldur and Thor can prove 65.7% of the theorems fully automatically. This paper paves the way for new research into using large language models for automating formal verification.
Enforcing Delayed-Impact Fairness Guarantees
Aug 24, 2022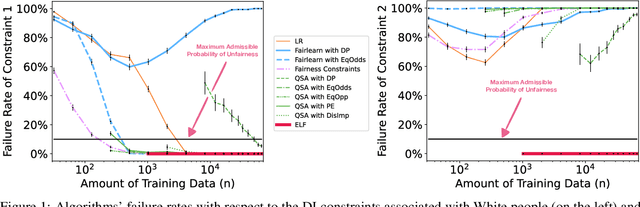
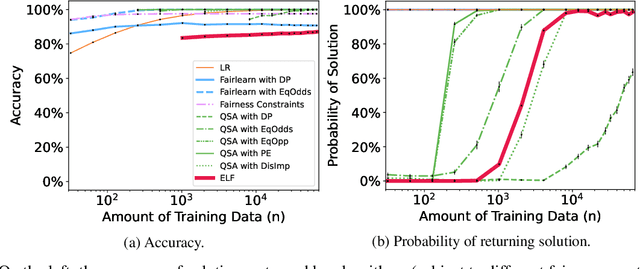
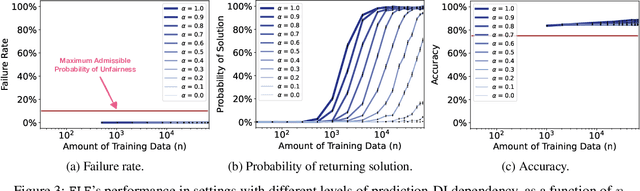
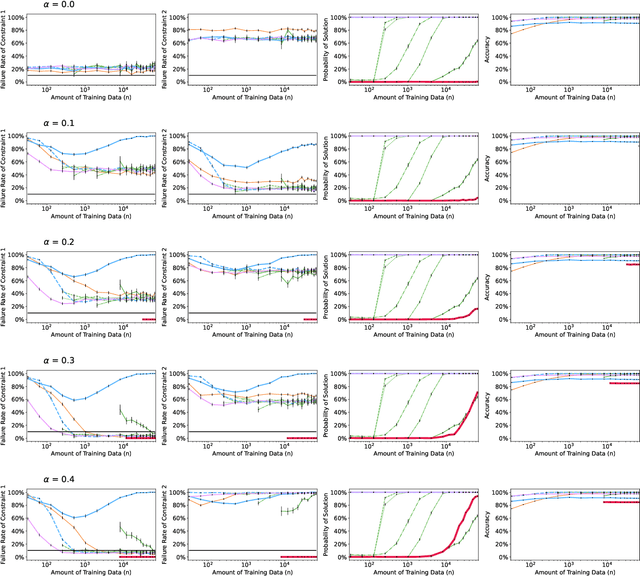
Recent research has shown that seemingly fair machine learning models, when used to inform decisions that have an impact on peoples' lives or well-being (e.g., applications involving education, employment, and lending), can inadvertently increase social inequality in the long term. This is because prior fairness-aware algorithms only consider static fairness constraints, such as equal opportunity or demographic parity. However, enforcing constraints of this type may result in models that have negative long-term impact on disadvantaged individuals and communities. We introduce ELF (Enforcing Long-term Fairness), the first classification algorithm that provides high-confidence fairness guarantees in terms of long-term, or delayed, impact. We prove that the probability that ELF returns an unfair solution is less than a user-specified tolerance and that (under mild assumptions), given sufficient training data, ELF is able to find and return a fair solution if one exists. We show experimentally that our algorithm can successfully mitigate long-term unfairness.
Fairkit, Fairkit, on the Wall, Who's the Fairest of Them All? Supporting Data Scientists in Training Fair Models
Dec 17, 2020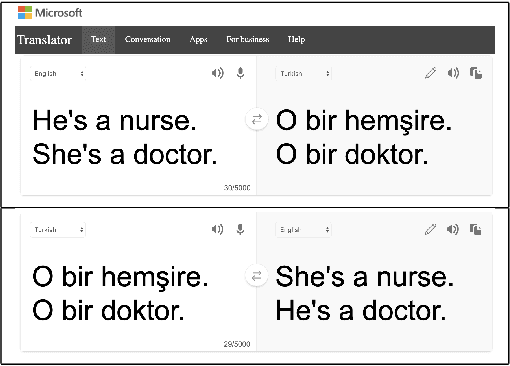
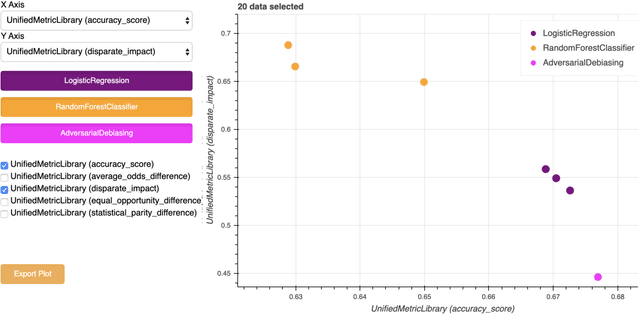
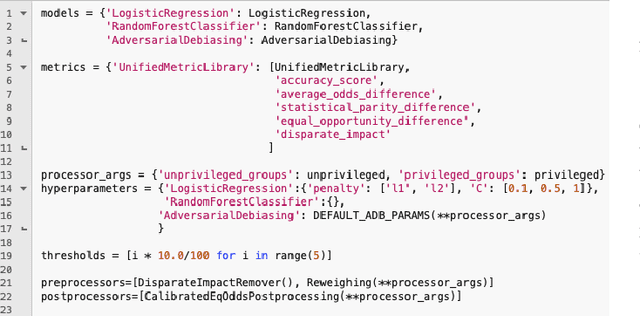

Modern software relies heavily on data and machine learning, and affects decisions that shape our world. Unfortunately, recent studies have shown that because of biases in data, software systems frequently inject bias into their decisions, from producing better closed caption transcriptions of men's voices than of women's voices to overcharging people of color for financial loans. To address bias in machine learning, data scientists need tools that help them understand the trade-offs between model quality and fairness in their specific data domains. Toward that end, we present fairkit-learn, a toolkit for helping data scientists reason about and understand fairness. Fairkit-learn works with state-of-the-art machine learning tools and uses the same interfaces to ease adoption. It can evaluate thousands of models produced by multiple machine learning algorithms, hyperparameters, and data permutations, and compute and visualize a small Pareto-optimal set of models that describe the optimal trade-offs between fairness and quality. We evaluate fairkit-learn via a user study with 54 students, showing that students using fairkit-learn produce models that provide a better balance between fairness and quality than students using scikit-learn and IBM AI Fairness 360 toolkits. With fairkit-learn, users can select models that are up to 67% more fair and 10% more accurate than the models they are likely to train with scikit-learn.
Fairness Testing: Testing Software for Discrimination
Sep 11, 2017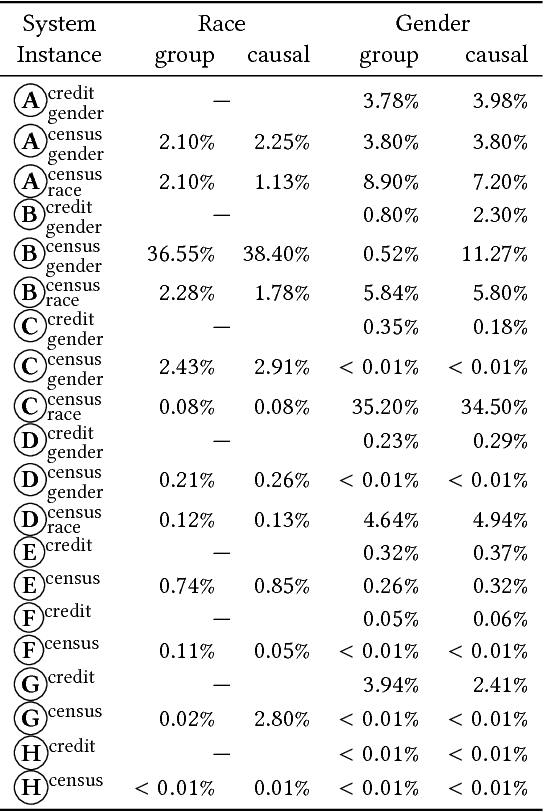
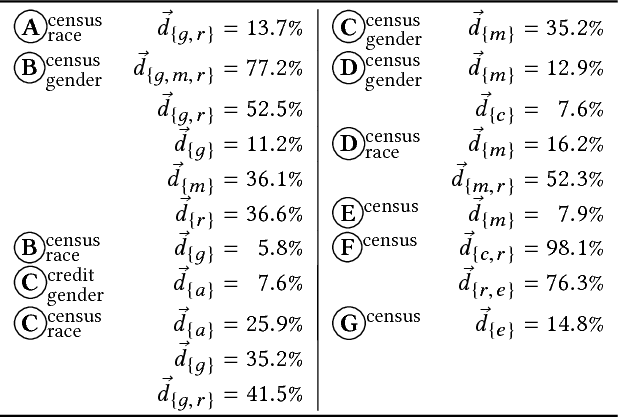
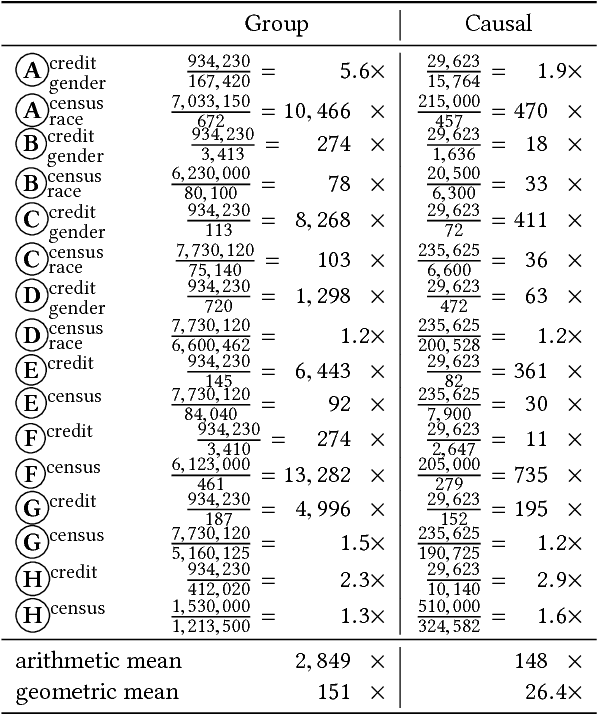
This paper defines software fairness and discrimination and develops a testing-based method for measuring if and how much software discriminates, focusing on causality in discriminatory behavior. Evidence of software discrimination has been found in modern software systems that recommend criminal sentences, grant access to financial products, and determine who is allowed to participate in promotions. Our approach, Themis, generates efficient test suites to measure discrimination. Given a schema describing valid system inputs, Themis generates discrimination tests automatically and does not require an oracle. We evaluate Themis on 20 software systems, 12 of which come from prior work with explicit focus on avoiding discrimination. We find that (1) Themis is effective at discovering software discrimination, (2) state-of-the-art techniques for removing discrimination from algorithms fail in many situations, at times discriminating against as much as 98% of an input subdomain, (3) Themis optimizations are effective at producing efficient test suites for measuring discrimination, and (4) Themis is more efficient on systems that exhibit more discrimination. We thus demonstrate that fairness testing is a critical aspect of the software development cycle in domains with possible discrimination and provide initial tools for measuring software discrimination.