 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundation Language Models (FLMs) for Automated Cohort Extraction from Large EHR Databases
Dec 16, 2024A crucial step in cohort studies is to extract the required cohort from one or more study datasets. This step is time-consuming, especially when a researcher is presented with a dataset that they have not previously worked with. When the cohort has to be extracted from multiple datasets, cohort extraction can be extremely laborious. In this study, we present an approach for partially automating cohort extraction from multiple electronic health record (EHR) databases. We formulate the guided multi-dataset cohort extraction problem in which selection criteria are first converted into queries, translating them from natural language text to language that maps to database entities. Then, using FLMs, columns of interest identified from the queries are automatically matched between the study databases. Finally, the generated queries are run across all databases to extract the study cohort. We propose and evaluate an algorithm for automating column matching on two large, popular and publicly-accessible EHR databases -- MIMIC-III and eICU. Our approach achieves a high top-three accuracy of $92\%$, correctly matching $12$ out of the $13$ columns of interest, when using a small, pre-trained general purpose language model. Furthermore, this accuracy is maintained even as the search space (i.e., size of the database) increases.
Non-Invasive Fairness in Learning through the Lens of Data Drift
Apr 05, 2023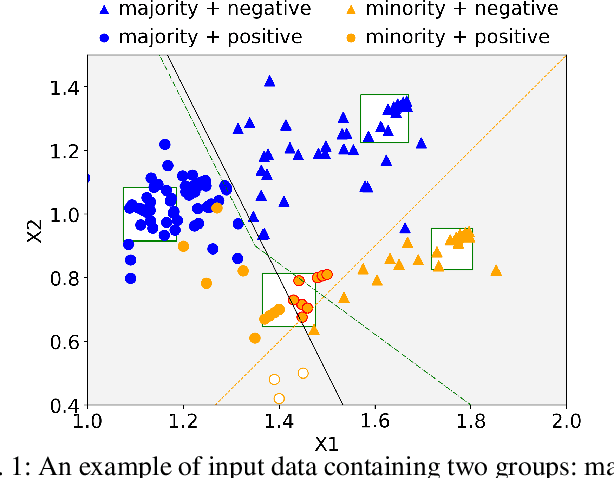
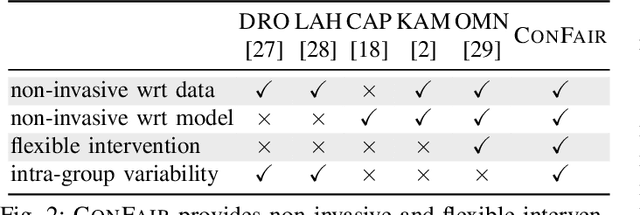

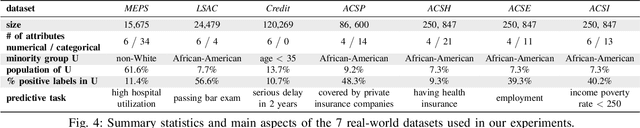
Machine Learning (ML) models are widely employed to drive many modern data systems. While they are undeniably powerful tools, ML models often demonstrate imbalanced performance and unfair behaviors. The root of this problem often lies in the fact that different subpopulations commonly display divergent trends: as a learning algorithm tries to identify trends in the data, it naturally favors the trends of the majority groups, leading to a model that performs poorly and unfairly for minority populations. Our goal is to improve the fairness and trustworthiness of ML models by applying only non-invasive interventions, i.e., without altering the data or the learning algorithm. We use a simple but key insight: the divergence of trends between different populations, and, consecutively, between a learned model and minority populations, is analogous to data drift, which indicates the poor conformance between parts of the data and the trained model. We explore two strategies (model-splitting and reweighing) to resolve this drift, aiming to improve the overall conformance of models to the underlying data. Both our methods introduce novel ways to employ the recently-proposed data profiling primitive of Conformance Constraints. Our experimental evaluation over 7 real-world datasets shows that both DifFair and ConFair improve the fairness of ML models. We demonstrate scenarios where DifFair has an edge, though ConFair has the greatest practical impact and outperforms other baselines. Moreover, as a model-agnostic technique, ConFair stays robust when used against different models than the ones on which the weights have been learned, which is not the case for other state of the art.
Through the Data Management Lens: Experimental Analysis and Evaluation of Fair Classification
Jan 18, 2021
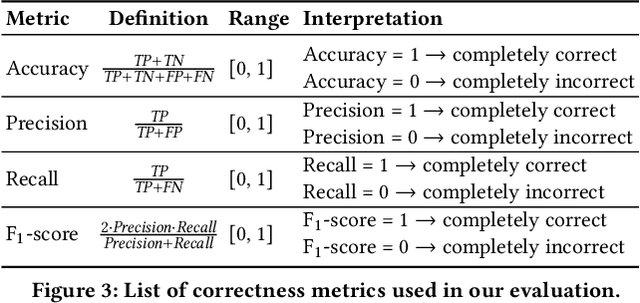
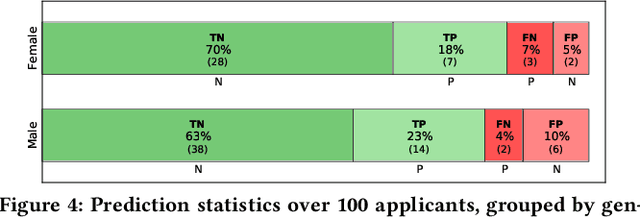
Classification, a heavily-studied data-driven machine learning task, drives an increasing number of prediction systems involving critical human decisions such as loan approval and criminal risk assessment. However, classifiers often demonstrate discriminatory behavior, especially when presented with biased data. Consequently, fairness in classification has emerged as a high-priority research area. Data management research is showing an increasing presence and interest in topics related to data and algorithmic fairness, including the topic of fair classification. The interdisciplinary efforts in fair classification, with machine learning research having the largest presence, have resulted in a large number of fairness notions and a wide range of approaches that have not been systematically evaluated and compared. In this paper, we contribute a broad analysis of 13 fair classification approaches and additional variants, over their correctness, fairness, efficiency, scalability, and stability, using a variety of metrics and real-world datasets. Our analysis highlights novel insights on the impact of different metrics and high-level approach characteristics on different aspects of performance. We also discuss general principles for choosing approaches suitable for different practical settings, and identify areas where data-management-centric solutions are likely to have the most impact.
Fairness Testing: Testing Software for Discrimination
Sep 11, 2017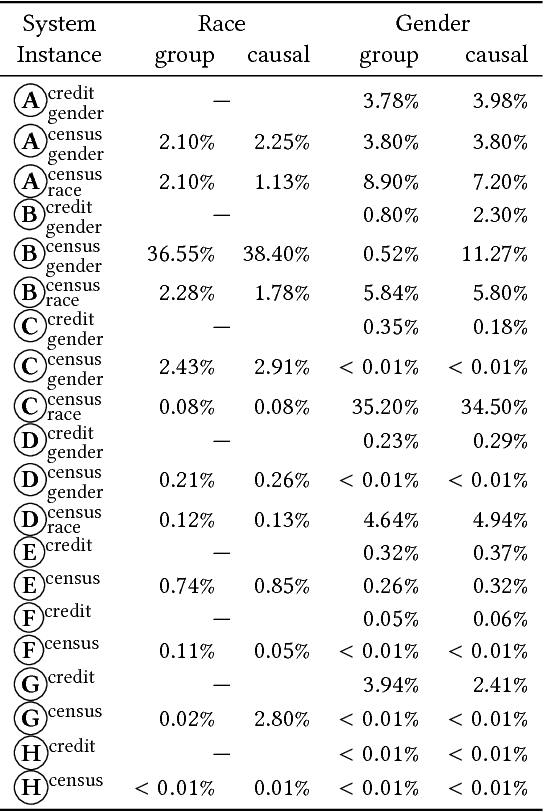
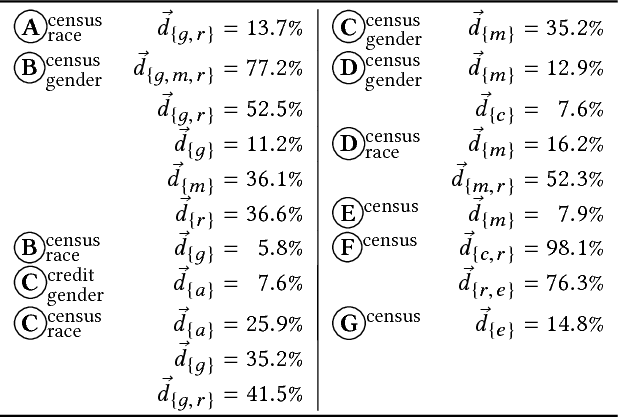
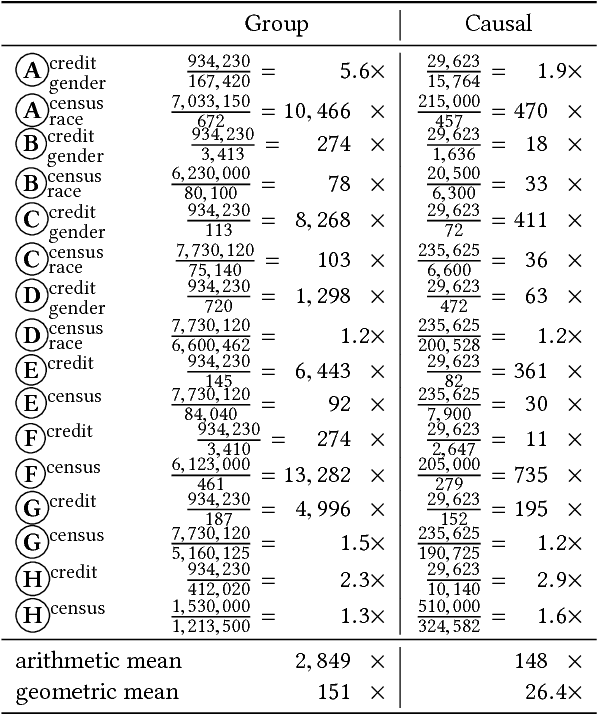
This paper defines software fairness and discrimination and develops a testing-based method for measuring if and how much software discriminates, focusing on causality in discriminatory behavior. Evidence of software discrimination has been found in modern software systems that recommend criminal sentences, grant access to financial products, and determine who is allowed to participate in promotions. Our approach, Themis, generates efficient test suites to measure discrimination. Given a schema describing valid system inputs, Themis generates discrimination tests automatically and does not require an oracle. We evaluate Themis on 20 software systems, 12 of which come from prior work with explicit focus on avoiding discrimination. We find that (1) Themis is effective at discovering software discrimination, (2) state-of-the-art techniques for removing discrimination from algorithms fail in many situations, at times discriminating against as much as 98% of an input subdomain, (3) Themis optimizations are effective at producing efficient test suites for measuring discrimination, and (4) Themis is more efficient on systems that exhibit more discrimination. We thus demonstrate that fairness testing is a critical aspect of the software development cycle in domains with possible discrimination and provide initial tools for measuring software discrimination.
The Complexity of Causality and Responsibility for Query Answers and non-Answers
Sep 30, 2011
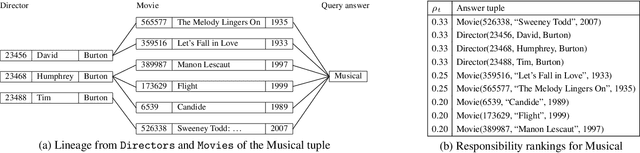
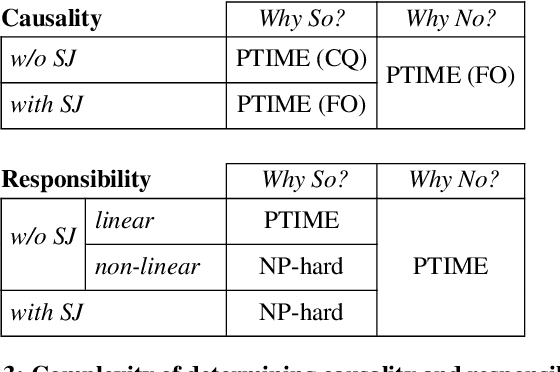
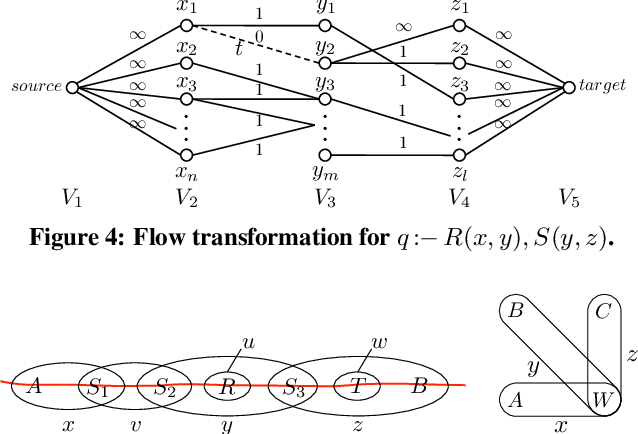
An answer to a query has a well-defined lineage expression (alternatively called how-provenance) that explains how the answer was derived. Recent work has also shown how to compute the lineage of a non-answer to a query. However, the cause of an answer or non-answer is a more subtle notion and consists, in general, of only a fragment of the lineage. In this paper, we adapt Halpern, Pearl, and Chockler's recent definitions of causality and responsibility to define the causes of answers and non-answers to queries, and their degree of responsibility. Responsibility captures the notion of degree of causality and serves to rank potentially many causes by their relative contributions to the effect. Then, we study the complexity of computing causes and responsibilities for conjunctive queries. It is known that computing causes is NP-complete in general. Our first main result shows that all causes to conjunctive queries can be computed by a relational query which may involve negation. Thus, causality can be computed in PTIME, and very efficiently so. Next, we study computing responsibility. Here, we prove that the complexity depends on the conjunctive query and demonstrate a dichotomy between PTIME and NP-complete cases. For the PTIME cases, we give a non-trivial algorithm, consisting of a reduction to the max-flow computation problem. Finally, we prove that, even when it is in PTIME, responsibility is complete for LOGSPACE, implying that, unlike causality, it cannot be computed by a relational query.
Why so? or Why no? Functional Causality for Explaining Query Answers
Dec 29, 2009
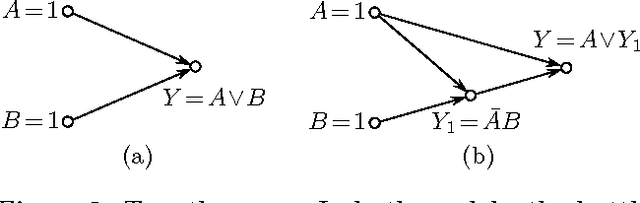
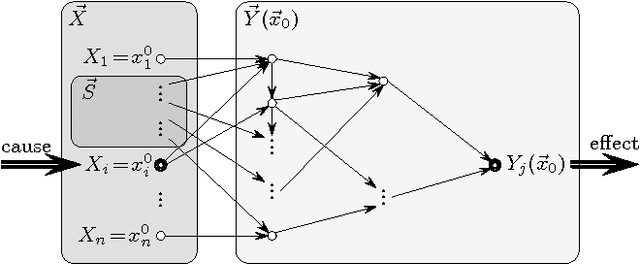
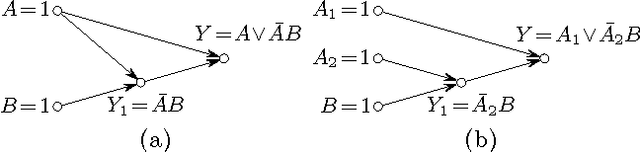
In this paper, we propose causality as a unified framework to explain query answers and non-answers, thus generalizing and extending several previously proposed approaches of provenance and missing query result explanations. We develop our framework starting from the well-studied definition of actual causes by Halpern and Pearl. After identifying some undesirable characteristics of the original definition, we propose functional causes as a refined definition of causality with several desirable properties. These properties allow us to apply our notion of causality in a database context and apply it uniformly to define the causes of query results and their individual contributions in several ways: (i) we can model both provenance as well as non-answers, (ii) we can define explanations as either data in the input relations or relational operations in a query plan, and (iii) we can give graded degrees of responsibility to individual causes, thus allowing us to rank causes. In particular, our approach allows us to explain contributions to relational aggregate functions and to rank causes according to their respective responsibilities. We give complexity results and describe polynomial algorithms for evaluating causality in tractable cases. Throughout the paper, we illustrate the applicability of our framework with several examples. Overall, we develop in this paper the theoretical foundations of causality theory in a database context.