 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Complexity of Causality and Responsibility for Query Answers and non-Answers
Sep 30, 2011
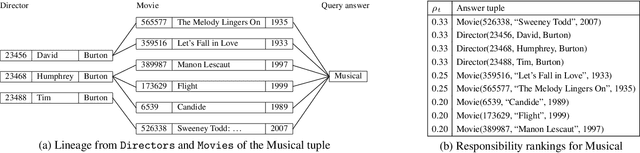
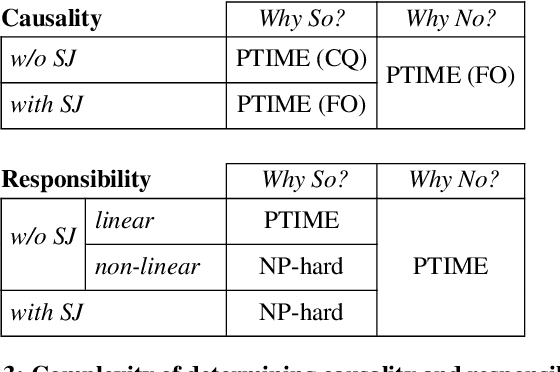
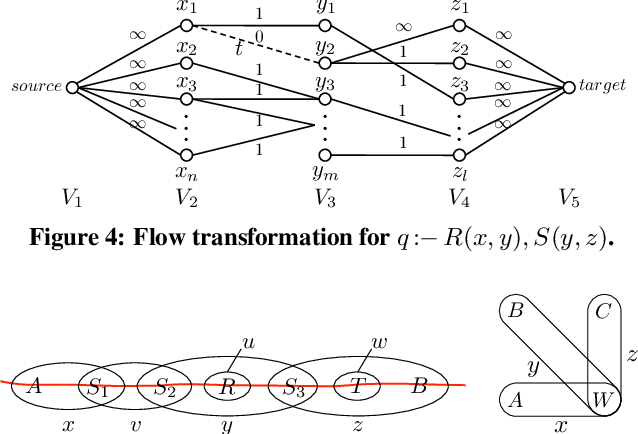
An answer to a query has a well-defined lineage expression (alternatively called how-provenance) that explains how the answer was derived. Recent work has also shown how to compute the lineage of a non-answer to a query. However, the cause of an answer or non-answer is a more subtle notion and consists, in general, of only a fragment of the lineage. In this paper, we adapt Halpern, Pearl, and Chockler's recent definitions of causality and responsibility to define the causes of answers and non-answers to queries, and their degree of responsibility. Responsibility captures the notion of degree of causality and serves to rank potentially many causes by their relative contributions to the effect. Then, we study the complexity of computing causes and responsibilities for conjunctive queries. It is known that computing causes is NP-complete in general. Our first main result shows that all causes to conjunctive queries can be computed by a relational query which may involve negation. Thus, causality can be computed in PTIME, and very efficiently so. Next, we study computing responsibility. Here, we prove that the complexity depends on the conjunctive query and demonstrate a dichotomy between PTIME and NP-complete cases. For the PTIME cases, we give a non-trivial algorithm, consisting of a reduction to the max-flow computation problem. Finally, we prove that, even when it is in PTIME, responsibility is complete for LOGSPACE, implying that, unlike causality, it cannot be computed by a relational query.
Why so? or Why no? Functional Causality for Explaining Query Answers
Dec 29, 2009
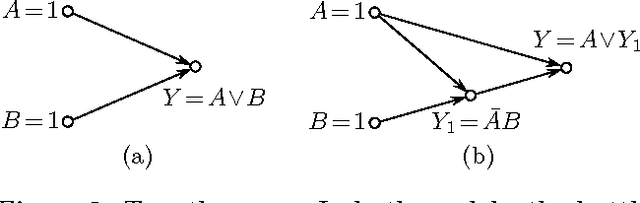
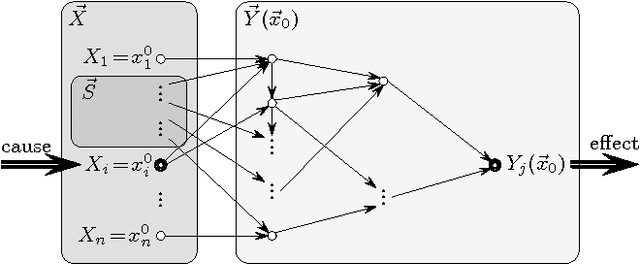
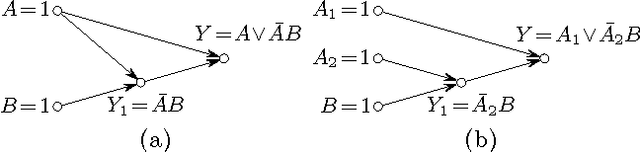
In this paper, we propose causality as a unified framework to explain query answers and non-answers, thus generalizing and extending several previously proposed approaches of provenance and missing query result explanations. We develop our framework starting from the well-studied definition of actual causes by Halpern and Pearl. After identifying some undesirable characteristics of the original definition, we propose functional causes as a refined definition of causality with several desirable properties. These properties allow us to apply our notion of causality in a database context and apply it uniformly to define the causes of query results and their individual contributions in several ways: (i) we can model both provenance as well as non-answers, (ii) we can define explanations as either data in the input relations or relational operations in a query plan, and (iii) we can give graded degrees of responsibility to individual causes, thus allowing us to rank causes. In particular, our approach allows us to explain contributions to relational aggregate functions and to rank causes according to their respective responsibilities. We give complexity results and describe polynomial algorithms for evaluating causality in tractable cases. Throughout the paper, we illustrate the applicability of our framework with several examples. Overall, we develop in this paper the theoretical foundations of causality theory in a database context.