 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Invasive Fairness in Learning through the Lens of Data Drift
Paper and Code
Apr 05, 2023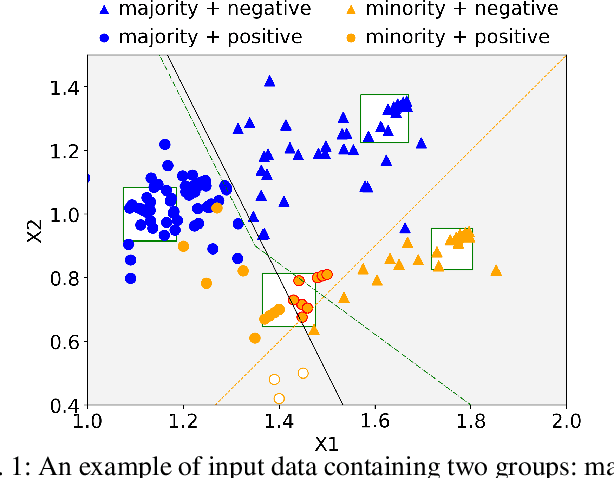
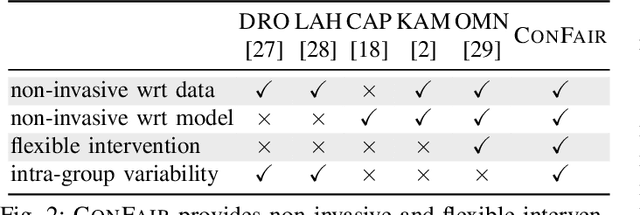

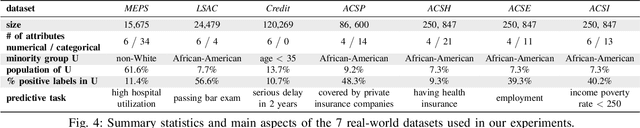
Machine Learning (ML) models are widely employed to drive many modern data systems. While they are undeniably powerful tools, ML models often demonstrate imbalanced performance and unfair behaviors. The root of this problem often lies in the fact that different subpopulations commonly display divergent trends: as a learning algorithm tries to identify trends in the data, it naturally favors the trends of the majority groups, leading to a model that performs poorly and unfairly for minority populations. Our goal is to improve the fairness and trustworthiness of ML models by applying only non-invasive interventions, i.e., without altering the data or the learning algorithm. We use a simple but key insight: the divergence of trends between different populations, and, consecutively, between a learned model and minority populations, is analogous to data drift, which indicates the poor conformance between parts of the data and the trained model. We explore two strategies (model-splitting and reweighing) to resolve this drift, aiming to improve the overall conformance of models to the underlying data. Both our methods introduce novel ways to employ the recently-proposed data profiling primitive of Conformance Constraints. Our experimental evaluation over 7 real-world datasets shows that both DifFair and ConFair improve the fairness of ML models. We demonstrate scenarios where DifFair has an edge, though ConFair has the greatest practical impact and outperforms other baselines. Moreover, as a model-agnostic technique, ConFair stays robust when used against different models than the ones on which the weights have been learned, which is not the case for other state of the art.