 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualia Optimization
May 16, 2025This report explores the speculative question: what if current or future AI systems have qualia, such as pain or pleasure? It does so by assuming that AI systems might someday possess qualia -- and that the quality of these subjective experiences should be considered alongside performance metrics. Concrete mathematical problem settings, inspired by reinforcement learning formulations and theories from philosophy of mind, are then proposed and initial approaches and properties are presented. These properties enable refinement of the problem setting, culminating with the proposal of methods that promote reinforcement.
Are Deep Speech Denoising Models Robust to Adversarial Noise?
Mar 14, 2025Deep noise suppression (DNS) models enjoy widespread use throughout a variety of high-stakes speech applications. However, in this paper, we show that four recent DNS models can each be reduced to outputting unintelligible gibberish through the addition of imperceptible adversarial noise. Furthermore, our results show the near-term plausibility of targeted attacks, which could induce models to output arbitrary utterances, and over-the-air attacks. While the success of these attacks varies by model and setting, and attacks appear to be strongest when model-specific (i.e., white-box and non-transferable), our results highlight a pressing need for practical countermeasures in DNS systems.
Supervised Reward Inference
Feb 25, 2025Existing approaches to reward inference from behavior typically assume that humans provide demonstrations according to specific models of behavior. However, humans often indicate their goals through a wide range of behaviors, from actions that are suboptimal due to poor planning or execution to behaviors which are intended to communicate goals rather than achieve them. We propose that supervised learning offers a unified framework to infer reward functions from any class of behavior, and show that such an approach is asymptotically Bayes-optimal under mild assumptions. Experiments on simulated robotic manipulation tasks show that our method can efficiently infer rewards from a wide variety of arbitrarily suboptimal demonstrations.
Abstract Reward Processes: Leveraging State Abstraction for Consistent Off-Policy Evaluation
Oct 03, 2024Evaluating policies using off-policy data is crucial for applying reinforcement learning to real-world problems such as healthcare and autonomous driving. Previous methods for off-policy evaluation (OPE) generally suffer from high variance or irreducible bias, leading to unacceptably high prediction errors. In this work, we introduce STAR, a framework for OPE that encompasses a broad range of estimators -- which include existing OPE methods as special cases -- that achieve lower mean squared prediction errors. STAR leverages state abstraction to distill complex, potentially continuous problems into compact, discrete models which we call abstract reward processes (ARPs). Predictions from ARPs estimated from off-policy data are provably consistent (asymptotically correct). Rather than proposing a specific estimator, we present a new framework for OPE and empirically demonstrate that estimators within STAR outperform existing methods. The best STAR estimator outperforms baselines in all twelve cases studied, and even the median STAR estimator surpasses the baselines in seven out of the twelve cases.
Position: Benchmarking is Limited in Reinforcement Learning Research
Jun 23, 2024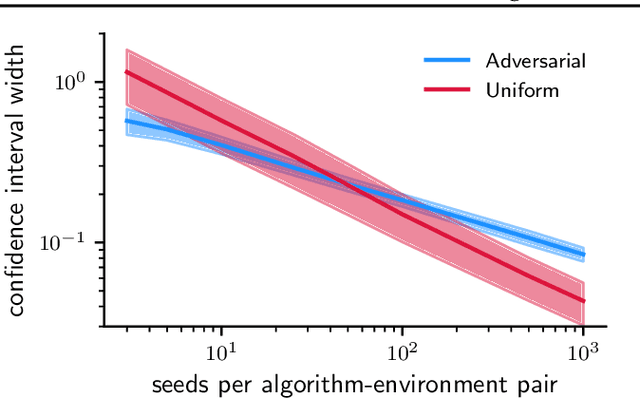

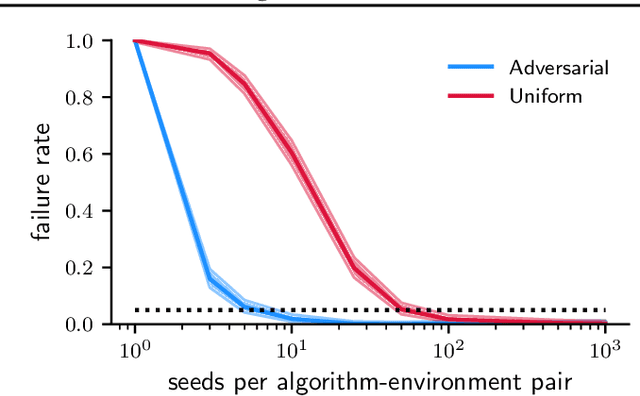
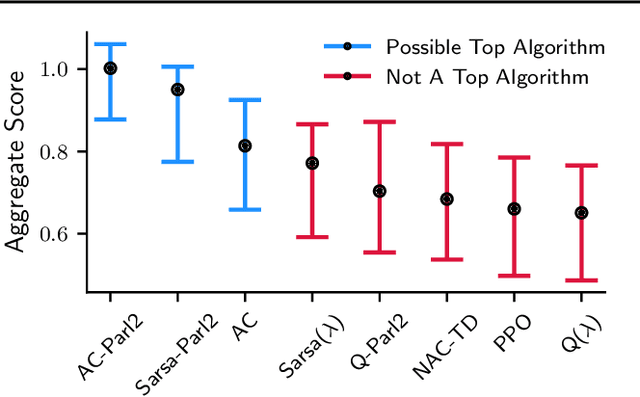
Novel reinforcement learning algorithms, or improvements on existing ones, are commonly justified by evaluating their performance on benchmark environments and are compared to an ever-changing set of standard algorithms. However, despite numerous calls for improvements, experimental practices continue to produce misleading or unsupported claims. One reason for the ongoing substandard practices is that conducting rigorous benchmarking experiments requires substantial computational time. This work investigates the sources of increased computation costs in rigorous experiment designs. We show that conducting rigorous performance benchmarks will likely have computational costs that are often prohibitive. As a result, we argue for using an additional experimentation paradigm to overcome the limitations of benchmarking.
ICU-Sepsis: A Benchmark MDP Built from Real Medical Data
Jun 09, 2024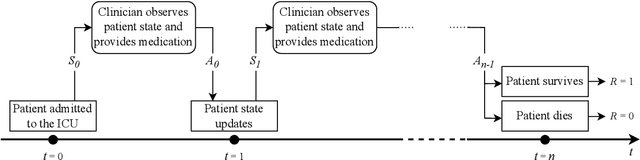
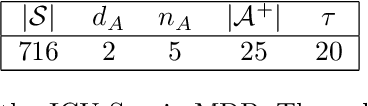

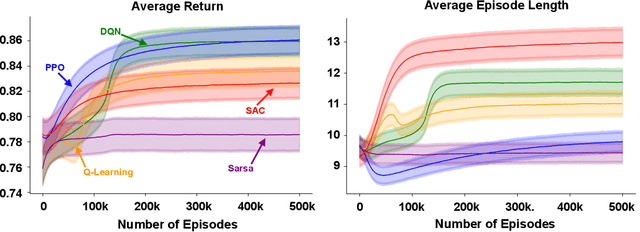
We present ICU-Sepsis, an environment that can be used in benchmarks for evaluating reinforcement learning (RL) algorithms. Sepsis management is a complex task that has been an important topic in applied RL research in recent years. Therefore, MDPs that model sepsis management can serve as part of a benchmark to evaluate RL algorithms on a challenging real-world problem. However, creating usable MDPs that simulate sepsis care in the ICU remains a challenge due to the complexities involved in acquiring and processing patient data. ICU-Sepsis is a lightweight environment that models personalized care of sepsis patients in the ICU. The environment is a tabular MDP that is widely compatible and is challenging even for state-of-the-art RL algorithms, making it a valuable tool for benchmarking their performance. However, we emphasize that while ICU-Sepsis provides a standardized environment for evaluating RL algorithms, it should not be used to draw conclusions that guide medical practice.
From Past to Future: Rethinking Eligibility Traces
Dec 20, 2023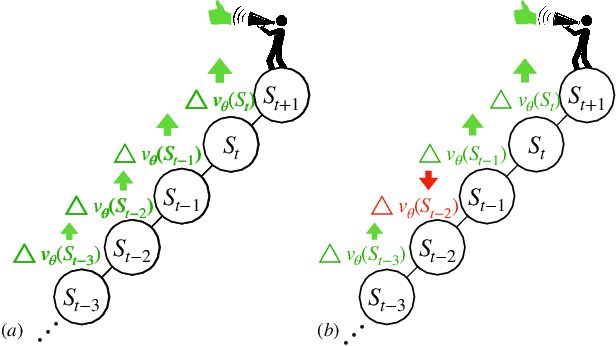
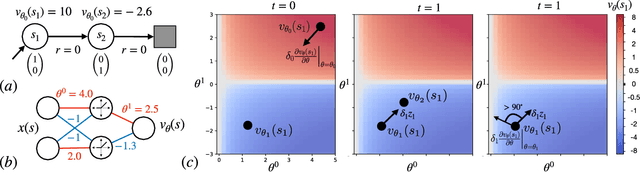
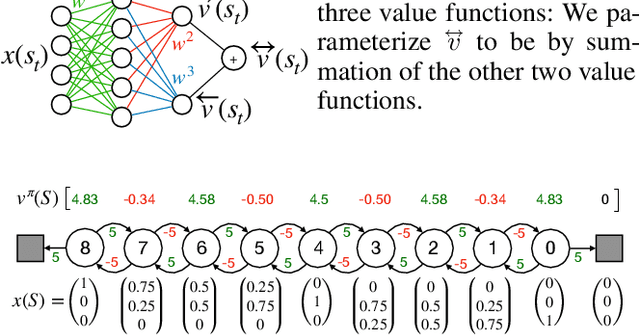
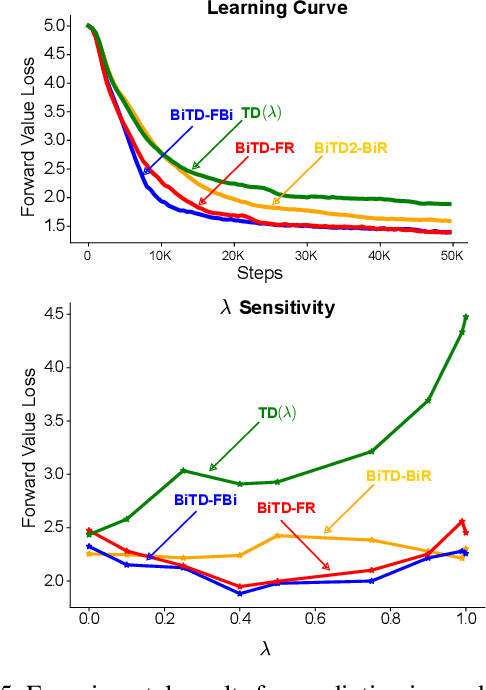
In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we refer to as the \emph{bidirectional value function}. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, perform policy evaluation more rapidly than TD($\lambda$) -- a method that learns forward value functions, $v^\pi$, \emph{directly}. Overall, our findings present a new perspective on eligibility traces and potential advantages associated with the novel value function it inspires, especially for policy evaluation.
Behavior Alignment via Reward Function Optimization
Oct 31, 2023



Designing reward functions for efficiently guiding reinforcement learning (RL) agents toward specific behaviors is a complex task. This is challenging since it requires the identification of reward structures that are not sparse and that avoid inadvertently inducing undesirable behaviors. Naively modifying the reward structure to offer denser and more frequent feedback can lead to unintended outcomes and promote behaviors that are not aligned with the designer's intended goal. Although potential-based reward shaping is often suggested as a remedy, we systematically investigate settings where deploying it often significantly impairs performance. To address these issues, we introduce a new framework that uses a bi-level objective to learn \emph{behavior alignment reward functions}. These functions integrate auxiliary rewards reflecting a designer's heuristics and domain knowledge with the environment's primary rewards. Our approach automatically determines the most effective way to blend these types of feedback, thereby enhancing robustness against heuristic reward misspecification. Remarkably, it can also adapt an agent's policy optimization process to mitigate suboptimalities resulting from limitations and biases inherent in the underlying RL algorithms. We evaluate our method's efficacy on a diverse set of tasks, from small-scale experiments to high-dimensional control challenges. We investigate heuristic auxiliary rewards of varying quality -- some of which are beneficial and others detrimental to the learning process. Our results show that our framework offers a robust and principled way to integrate designer-specified heuristics. It not only addresses key shortcomings of existing approaches but also consistently leads to high-performing solutions, even when given misaligned or poorly-specified auxiliary reward functions.
Learning Fair Representations with High-Confidence Guarantees
Oct 23, 2023Representation learning is increasingly employed to generate representations that are predictive across multiple downstream tasks. The development of representation learning algorithms that provide strong fairness guarantees is thus important because it can prevent unfairness towards disadvantaged groups for all downstream prediction tasks. To prevent unfairness towards disadvantaged groups in all downstream tasks, it is crucial to provide representation learning algorithms that provide fairness guarantees. In this paper, we formally define the problem of learning representations that are fair with high confidence. We then introduce the Fair Representation learning with high-confidence Guarantees (FRG) framework, which provides high-confidence guarantees for limiting unfairness across all downstream models and tasks, with user-defined upper bounds. After proving that FRG ensures fairness for all downstream models and tasks with high probability, we present empirical evaluations that demonstrate FRG's effectiveness at upper bounding unfairness for multiple downstream models and tasks.
Coagent Networks: Generalized and Scaled
May 16, 2023

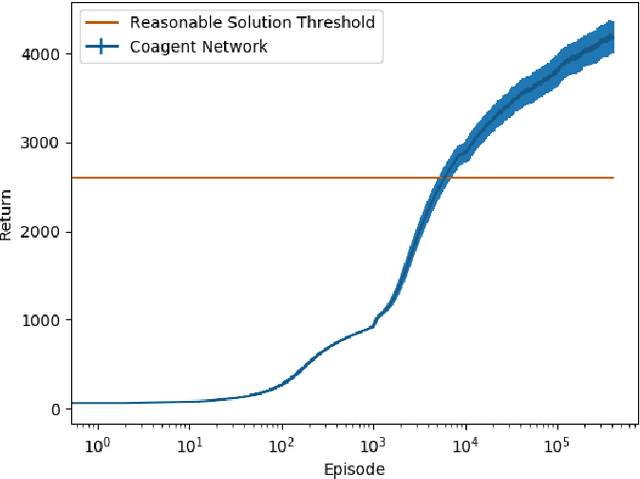
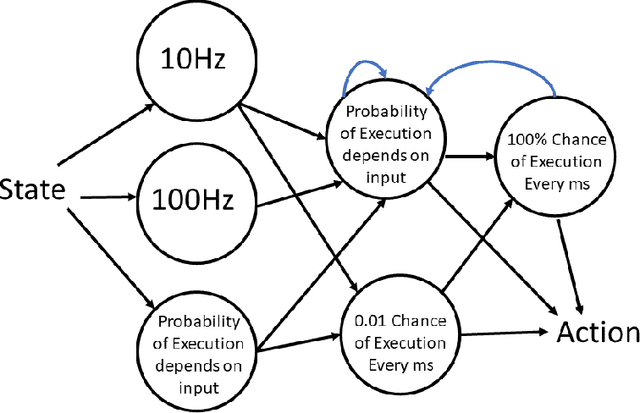
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011] provide a powerful and flexible framework for deriving principled learning rules for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of backpropagation's main limitations. For example, coagent networks can compute different parts of the network \emph{asynchronously} (at different rates or at different times), can incorporate non-differentiable components that cannot be used with backpropagation, and can explore at levels higher than their action spaces (that is, they can be designed as hierarchical networks for exploration and/or temporal abstraction). However, the coagent framework is not just an alternative to BDL; the two approaches can be blended: BDL can be combined with coagent learning rules to create architectures with the advantages of both approaches. This work generalizes the coagent theory and learning rules provided by previous works; this generalization provides more flexibility for network architecture design within the coagent framework. This work also studies one of the chief disadvantages of coagent networks: high variance updates for networks that have many coagents and do not use backpropagation. We show that a coagent algorithm with a policy network that does not use backpropagation can scale to a challenging RL domain with a high-dimensional state and action space (the MuJoCo Ant environment), learning reasonable (although not state-of-the-art) policies. These contributions motivate and provide a more general theoretical foundation for future work that studies coagent networks.