 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing multimodal embedding spaces with group-sparse autoencoders
Jan 27, 2026The Linear Representation Hypothesis asserts that the embeddings learned by neural networks can be understood as linear combinations of features corresponding to high-level concepts. Based on this ansatz, sparse autoencoders (SAEs) have recently become a popular method for decomposing embeddings into a sparse combination of linear directions, which have been shown empirically to often correspond to human-interpretable semantics. However, recent attempts to apply SAEs to multimodal embedding spaces (such as the popular CLIP embeddings for image/text data) have found that SAEs often learn "split dictionaries", where most of the learned sparse features are essentially unimodal, active only for data of a single modality. In this work, we study how to effectively adapt SAEs for the setting of multimodal embeddings while ensuring multimodal alignment. We first argue that the existence of a split dictionary decomposition on an aligned embedding space implies the existence of a non-split dictionary with improved modality alignment. Then, we propose a new SAE-based approach to multimodal embedding decomposition using cross-modal random masking and group-sparse regularization. We apply our method to popular embeddings for image/text (CLIP) and audio/text (CLAP) data and show that, compared to standard SAEs, our approach learns a more multimodal dictionary while reducing the number of dead neurons and improving feature semanticity. We finally demonstrate how this improvement in alignment of concepts between modalities can enable improvements in the interpretability and control of cross-modal tasks.
Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Nov 07, 2025In this work, we identify an inherent bias in prevailing LVLM architectures toward the language modality, largely resulting from the common practice of simply appending visual embeddings to the input text sequence. To address this, we propose a simple yet effective method that refines textual embeddings by integrating average-pooled visual features. Our approach demonstrably improves visual grounding and significantly reduces hallucinations on established benchmarks. While average pooling offers a straightforward, robust, and efficient means of incorporating visual information, we believe that more sophisticated fusion methods could further enhance visual grounding and cross-modal alignment. Given that the primary focus of this work is to highlight the modality imbalance and its impact on hallucinations -- and to show that refining textual embeddings with visual information mitigates this issue -- we leave exploration of advanced fusion strategies for future work.
Audio-Visual Speech Separation via Bottleneck Iterative Network
Jul 09, 2025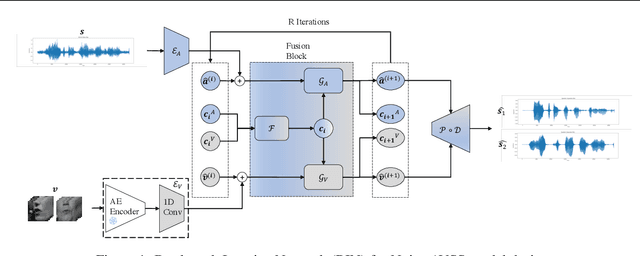
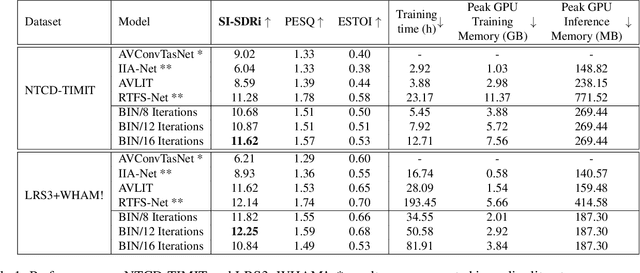
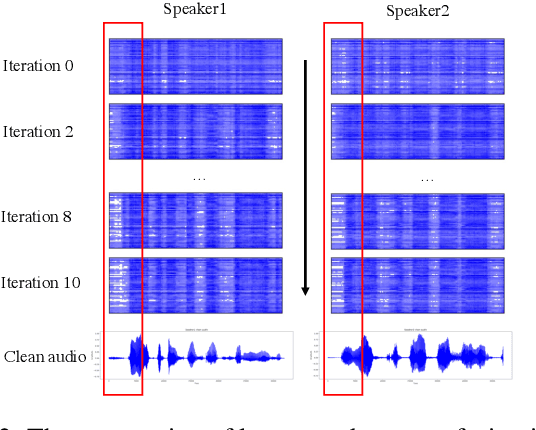
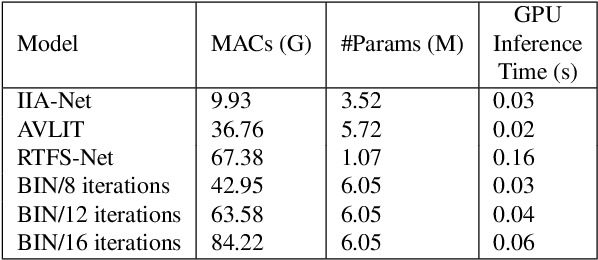
Integration of information from non-auditory cues can significantly improve the performance of speech-separation models. Often such models use deep modality-specific networks to obtain unimodal features, and risk being too costly or lightweight but lacking capacity. In this work, we present an iterative representation refinement approach called Bottleneck Iterative Network (BIN), a technique that repeatedly progresses through a lightweight fusion block, while bottlenecking fusion representations by fusion tokens. This helps improve the capacity of the model, while avoiding major increase in model size and balancing between the model performance and training cost. We test BIN on challenging noisy audio-visual speech separation tasks, and show that our approach consistently outperforms state-of-the-art benchmark models with respect to SI-SDRi on NTCD-TIMIT and LRS3+WHAM! datasets, while simultaneously achieving a reduction of more than 50% in training and GPU inference time across nearly all settings.
Are Deep Speech Denoising Models Robust to Adversarial Noise?
Mar 14, 2025Deep noise suppression (DNS) models enjoy widespread use throughout a variety of high-stakes speech applications. However, in this paper, we show that four recent DNS models can each be reduced to outputting unintelligible gibberish through the addition of imperceptible adversarial noise. Furthermore, our results show the near-term plausibility of targeted attacks, which could induce models to output arbitrary utterances, and over-the-air attacks. While the success of these attacks varies by model and setting, and attacks appear to be strongest when model-specific (i.e., white-box and non-transferable), our results highlight a pressing need for practical countermeasures in DNS systems.
XAttnMark: Learning Robust Audio Watermarking with Cross-Attention
Feb 07, 2025



The rapid proliferation of generative audio synthesis and editing technologies has raised significant concerns about copyright infringement, data provenance, and the spread of misinformation through deepfake audio. Watermarking offers a proactive solution by embedding imperceptible, identifiable, and traceable marks into audio content. While recent neural network-based watermarking methods like WavMark and AudioSeal have improved robustness and quality, they struggle to achieve both robust detection and accurate attribution simultaneously. This paper introduces Cross-Attention Robust Audio Watermark (XAttnMark), which bridges this gap by leveraging partial parameter sharing between the generator and the detector, a cross-attention mechanism for efficient message retrieval, and a temporal conditioning module for improved message distribution. Additionally, we propose a psychoacoustic-aligned temporal-frequency masking loss that captures fine-grained auditory masking effects, enhancing watermark imperceptibility. Our approach achieves state-of-the-art performance in both detection and attribution, demonstrating superior robustness against a wide range of audio transformations, including challenging generative editing with strong editing strength. The project webpage is available at https://liuyixin-louis.github.io/xattnmark/.
AudioMiXR: Spatial Audio Object Manipulation with 6DoF for Sound Design in Augmented Reality
Feb 05, 2025



We present AudioMiXR, an augmented reality (AR) interface intended to assess how users manipulate virtual audio objects situated in their physical space using six degrees of freedom (6DoF) deployed on a head-mounted display (Apple Vision Pro) for 3D sound design. Existing tools for 3D sound design are typically constrained to desktop displays, which may limit spatial awareness of mixing within the execution environment. Utilizing an XR HMD to create soundscapes may provide a real-time test environment for 3D sound design, as modern HMDs can provide precise spatial localization assisted by cross-modal interactions. However, there is no research on design guidelines specific to sound design with six degrees of freedom (6DoF) in XR. To provide a first step toward identifying design-related research directions in this space, we conducted an exploratory study where we recruited 27 participants, consisting of expert and non-expert sound designers. The goal was to assess design lessons that can be used to inform future research venues in 3D sound design. We ran a within-subjects study where users designed both a music and cinematic soundscapes. After thematically analyzing participant data, we constructed two design lessons: 1. Proprioception for AR Sound Design, and 2. Balancing Audio-Visual Modalities in AR GUIs. Additionally, we provide application domains that can benefit most from 6DoF sound design based on our results.
Accent Conversion with Articulatory Representations
Jun 10, 2024



Conversion of non-native accented speech to native (American) English has a wide range of applications such as improving intelligibility of non-native speech. Previous work on this domain has used phonetic posteriograms as the target speech representation to train an acoustic model which is then used to extract a compact representation of input speech for accent conversion. In this work, we introduce the idea of using an effective articulatory speech representation, extracted from an acoustic-to-articulatory speech inversion system, to improve the acoustic model used in accent conversion. The idea to incorporate articulatory representations originates from their ability to well characterize accents in speech. To incorporate articulatory representations with conventional phonetic posteriograms, a multi-task learning based acoustic model is proposed. Objective and subjective evaluations show that the use of articulatory representations can improve the effectiveness of accent conversion.
Low latency transformers for speech processing
Feb 27, 2023



The transformer is a widely-used building block in modern neural networks. However, when applied to audio data, the transformer's acausal behaviour, which we term Acausal Attention (AA), has generally limited its application to offline tasks. In this paper we introduce Streaming Attention (SA), which operates causally with fixed latency, and requires lower compute and memory resources than AA to train. Next, we introduce Low Latency Streaming Attention (LLSA), a method which combines multiple SA layers without latency build-up proportional to the layer count. Comparative analysis between AA, SA and LLSA on Automatic Speech Recognition (ASR) and Speech Emotion Recognition (SER) tasks are presented. The results show that causal SA-based networks with fixed latencies of a few seconds (e.g. 1.8 seconds) and LLSA networks with latencies as short as 300 ms can perform comparably with acausal (AA) networks. We conclude that SA and LLSA methods retain many of the benefits of conventional acausal transformers, but with latency characteristics that make them practical to run in real-time streaming applications.