 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccent Conversion with Articulatory Representations
Jun 10, 2024



Conversion of non-native accented speech to native (American) English has a wide range of applications such as improving intelligibility of non-native speech. Previous work on this domain has used phonetic posteriograms as the target speech representation to train an acoustic model which is then used to extract a compact representation of input speech for accent conversion. In this work, we introduce the idea of using an effective articulatory speech representation, extracted from an acoustic-to-articulatory speech inversion system, to improve the acoustic model used in accent conversion. The idea to incorporate articulatory representations originates from their ability to well characterize accents in speech. To incorporate articulatory representations with conventional phonetic posteriograms, a multi-task learning based acoustic model is proposed. Objective and subjective evaluations show that the use of articulatory representations can improve the effectiveness of accent conversion.
DeepSpace: Dynamic Spatial and Source Cue Based Source Separation for Dialog Enhancement
Feb 22, 2023


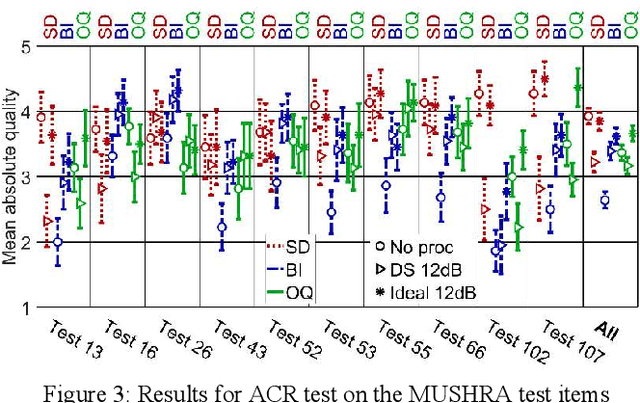
Dialog Enhancement (DE) is a feature which allows a user to increase the level of dialog in TV or movie content relative to non-dialog sounds. When only the original mix is available, DE is "unguided," and requires source separation. In this paper, we describe the DeepSpace system, which performs source separation using both dynamic spatial cues and source cues to support unguided DE. Its technologies include spatio-level filtering (SLF) and deep-learning based dialog classification and denoising. Using subjective listening tests, we show that DeepSpace demonstrates significantly improved overall performance relative to state-of-the-art systems available for testing. We explore the feasibility of using existing automated metrics to evaluate unguided DE systems.
Stereo Speech Enhancement Using Custom Mid-Side Signals and Monaural Processing
Nov 25, 2022Speech Enhancement (SE) systems typically operate on monaural input and are used for applications including voice communications and capture cleanup for user generated content. Recent advancements and changes in the devices used for these applications are likely to lead to an increase in the amount of two-channel content for the same applications. However, SE systems are typically designed for monaural input; stereo results produced using trivial methods such as channel independent or mid-side processing may be unsatisfactory, including substantial speech distortions. To address this, we propose a system which creates a novel representation of stereo signals called Custom Mid-Side Signals (CMSS). CMSS allow benefits of mid-side signals for center-panned speech to be extended to a much larger class of input signals. This in turn allows any existing monaural SE system to operate as an efficient stereo system by processing the custom mid signal. We describe how the parameters needed for CMSS can be efficiently estimated by a component of the spatio-level filtering source separation system. Subjective listening using state-of-the-art deep learning-based SE systems on stereo content with various speech mixing styles shows that CMSS processing leads to improved speech quality at approximately half the cost of channel-independent processing.