 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Preference Hacking in Policy Optimization with Pessimism
Mar 10, 2025This work tackles the problem of overoptimization in reinforcement learning from human feedback (RLHF), a prevalent technique for aligning models with human preferences. RLHF relies on reward or preference models trained on \emph{fixed preference datasets}, and these models are unreliable when evaluated outside the support of this preference data, leading to the common reward or preference hacking phenomenon. We propose novel, pessimistic objectives for RLHF which are provably robust to overoptimization through the use of pessimism in the face of uncertainty, and design practical algorithms, P3O and PRPO, to optimize these objectives. Our approach is derived for the general preference optimization setting, but can be used with reward models as well. We evaluate P3O and PRPO on the tasks of fine-tuning language models for document summarization and creating helpful assistants, demonstrating remarkable resilience to overoptimization.
A Safe Exploration Strategy for Model-free Task Adaptation in Safety-constrained Grid Environments
Aug 02, 2024



Training a model-free reinforcement learning agent requires allowing the agent to sufficiently explore the environment to search for an optimal policy. In safety-constrained environments, utilizing unsupervised exploration or a non-optimal policy may lead the agent to undesirable states, resulting in outcomes that are potentially costly or hazardous for both the agent and the environment. In this paper, we introduce a new exploration framework for navigating the grid environments that enables model-free agents to interact with the environment while adhering to safety constraints. Our framework includes a pre-training phase, during which the agent learns to identify potentially unsafe states based on both observable features and specified safety constraints in the environment. Subsequently, a binary classification model is trained to predict those unsafe states in new environments that exhibit similar dynamics. This trained classifier empowers model-free agents to determine situations in which employing random exploration or a suboptimal policy may pose safety risks, in which case our framework prompts the agent to follow a predefined safe policy to mitigate the potential for hazardous consequences. We evaluated our framework on three randomly generated grid environments and demonstrated how model-free agents can safely adapt to new tasks and learn optimal policies for new environments. Our results indicate that by defining an appropriate safe policy and utilizing a well-trained model to detect unsafe states, our framework enables a model-free agent to adapt to new tasks and environments with significantly fewer safety violations.
ICU-Sepsis: A Benchmark MDP Built from Real Medical Data
Jun 09, 2024
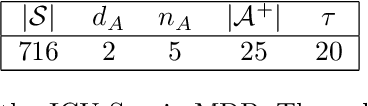

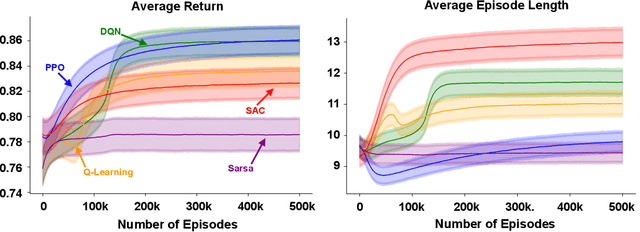
We present ICU-Sepsis, an environment that can be used in benchmarks for evaluating reinforcement learning (RL) algorithms. Sepsis management is a complex task that has been an important topic in applied RL research in recent years. Therefore, MDPs that model sepsis management can serve as part of a benchmark to evaluate RL algorithms on a challenging real-world problem. However, creating usable MDPs that simulate sepsis care in the ICU remains a challenge due to the complexities involved in acquiring and processing patient data. ICU-Sepsis is a lightweight environment that models personalized care of sepsis patients in the ICU. The environment is a tabular MDP that is widely compatible and is challenging even for state-of-the-art RL algorithms, making it a valuable tool for benchmarking their performance. However, we emphasize that while ICU-Sepsis provides a standardized environment for evaluating RL algorithms, it should not be used to draw conclusions that guide medical practice.
From Past to Future: Rethinking Eligibility Traces
Dec 20, 2023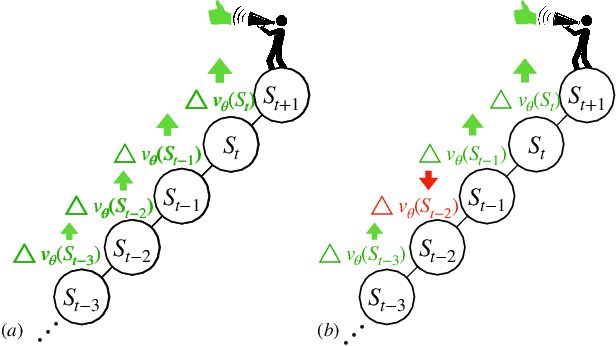
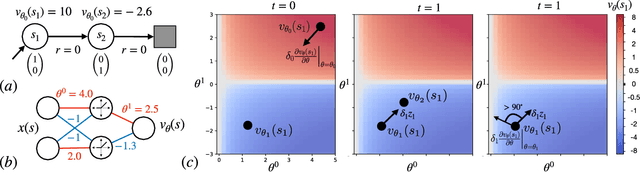
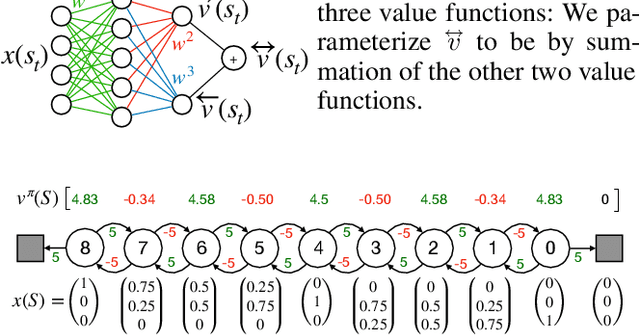
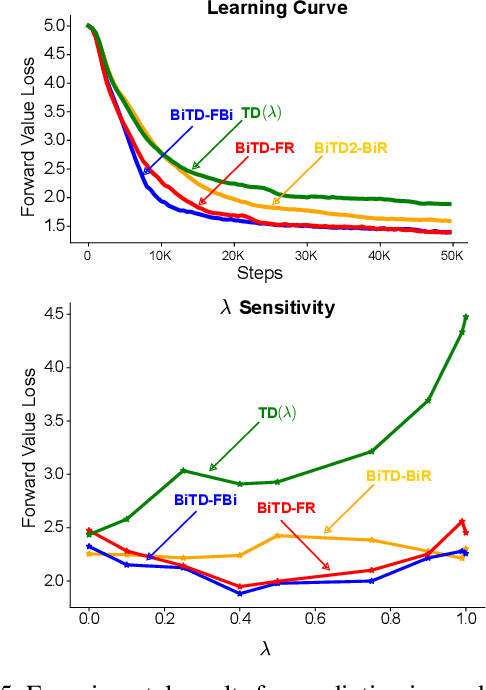
In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we refer to as the \emph{bidirectional value function}. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, perform policy evaluation more rapidly than TD($\lambda$) -- a method that learns forward value functions, $v^\pi$, \emph{directly}. Overall, our findings present a new perspective on eligibility traces and potential advantages associated with the novel value function it inspires, especially for policy evaluation.
Behavior Alignment via Reward Function Optimization
Oct 31, 2023



Designing reward functions for efficiently guiding reinforcement learning (RL) agents toward specific behaviors is a complex task. This is challenging since it requires the identification of reward structures that are not sparse and that avoid inadvertently inducing undesirable behaviors. Naively modifying the reward structure to offer denser and more frequent feedback can lead to unintended outcomes and promote behaviors that are not aligned with the designer's intended goal. Although potential-based reward shaping is often suggested as a remedy, we systematically investigate settings where deploying it often significantly impairs performance. To address these issues, we introduce a new framework that uses a bi-level objective to learn \emph{behavior alignment reward functions}. These functions integrate auxiliary rewards reflecting a designer's heuristics and domain knowledge with the environment's primary rewards. Our approach automatically determines the most effective way to blend these types of feedback, thereby enhancing robustness against heuristic reward misspecification. Remarkably, it can also adapt an agent's policy optimization process to mitigate suboptimalities resulting from limitations and biases inherent in the underlying RL algorithms. We evaluate our method's efficacy on a diverse set of tasks, from small-scale experiments to high-dimensional control challenges. We investigate heuristic auxiliary rewards of varying quality -- some of which are beneficial and others detrimental to the learning process. Our results show that our framework offers a robust and principled way to integrate designer-specified heuristics. It not only addresses key shortcomings of existing approaches but also consistently leads to high-performing solutions, even when given misaligned or poorly-specified auxiliary reward functions.
Exploring the impact of low-rank adaptation on the performance, efficiency, and regularization of RLHF
Sep 16, 2023
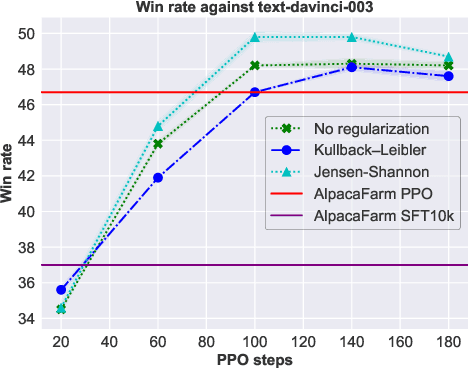
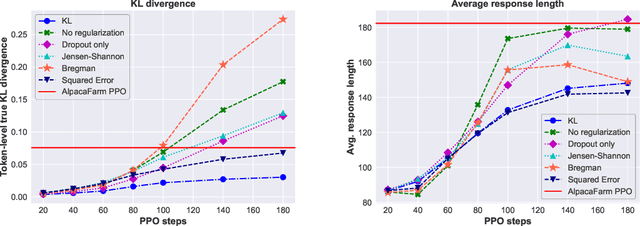
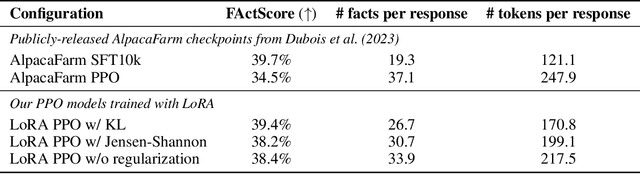
During the last stage of RLHF, a large language model is aligned to human intents via PPO training, a process that generally requires large-scale computational resources. In this technical report, we empirically investigate an efficient implementation of RLHF using low-rank adaptation (LoRA), which allows us to align the LLaMA 7B checkpoint on the Alpaca dataset using only two A100 GPUs instead of the eight required for full model fine-tuning. Despite tuning only 0.2% of LLaMA 7B's parameters, our implementation achieves better performance than the publicly-released AlpacaFarm checkpoint with full model fine-tuning. Next, we analyze several configurations of our LoRA-based PPO implementation, varying the form of the KL regularization term in the training objective. We find that (1) removing this penalty term does not harm performance on the AlpacaFarm evaluation set under our LoRA setup; (2) other regularizers, such as Jensen-Shannon divergence, lead to improved performance; and (3) while PPO training negatively impacts the factuality of model-generated responses, training with LoRA largely mitigates this effect. We release our code and pretrained checkpoints to facilitate future research on more efficient RLHF.
Coagent Networks: Generalized and Scaled
May 16, 2023

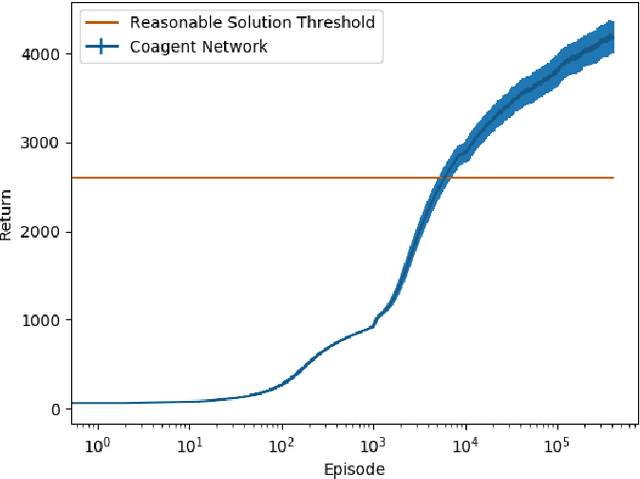
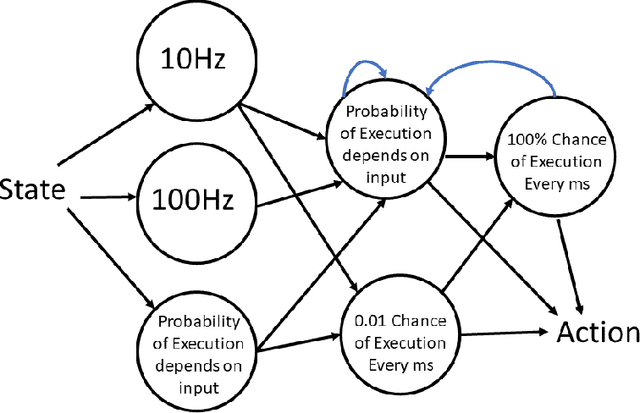
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011] provide a powerful and flexible framework for deriving principled learning rules for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of backpropagation's main limitations. For example, coagent networks can compute different parts of the network \emph{asynchronously} (at different rates or at different times), can incorporate non-differentiable components that cannot be used with backpropagation, and can explore at levels higher than their action spaces (that is, they can be designed as hierarchical networks for exploration and/or temporal abstraction). However, the coagent framework is not just an alternative to BDL; the two approaches can be blended: BDL can be combined with coagent learning rules to create architectures with the advantages of both approaches. This work generalizes the coagent theory and learning rules provided by previous works; this generalization provides more flexibility for network architecture design within the coagent framework. This work also studies one of the chief disadvantages of coagent networks: high variance updates for networks that have many coagents and do not use backpropagation. We show that a coagent algorithm with a policy network that does not use backpropagation can scale to a challenging RL domain with a high-dimensional state and action space (the MuJoCo Ant environment), learning reasonable (although not state-of-the-art) policies. These contributions motivate and provide a more general theoretical foundation for future work that studies coagent networks.
Offline Reinforcement Learning for Mixture-of-Expert Dialogue Management
Feb 21, 2023Reinforcement learning (RL) has shown great promise for developing dialogue management (DM) agents that are non-myopic, conduct rich conversations, and maximize overall user satisfaction. Despite recent developments in RL and language models (LMs), using RL to power conversational chatbots remains challenging, in part because RL requires online exploration to learn effectively, whereas collecting novel human-bot interactions can be expensive and unsafe. This issue is exacerbated by the combinatorial action spaces facing these algorithms, as most LM agents generate responses at the word level. We develop a variety of RL algorithms, specialized to dialogue planning, that leverage recent Mixture-of-Expert Language Models (MoE-LMs) -- models that capture diverse semantics, generate utterances reflecting different intents, and are amenable for multi-turn DM. By exploiting MoE-LM structure, our methods significantly reduce the size of the action space and improve the efficacy of RL-based DM. We evaluate our methods in open-domain dialogue to demonstrate their effectiveness w.r.t.\ the diversity of intent in generated utterances and overall DM performance.
Gradient Temporal-Difference Learning with Regularized Corrections
Jul 07, 2020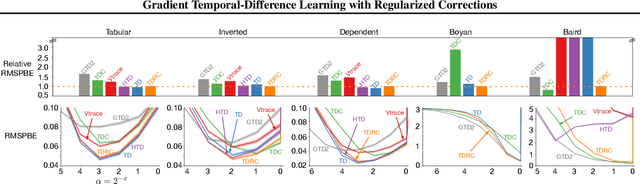
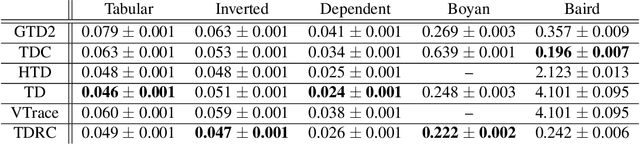
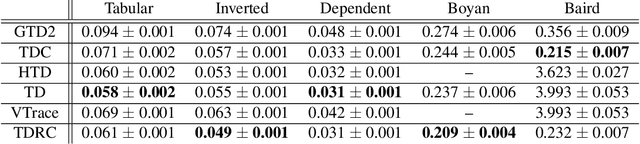
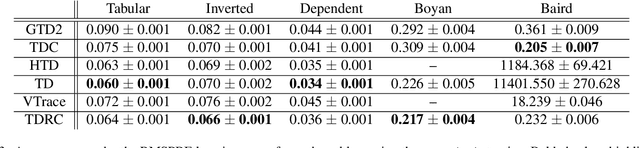
It is still common to use Q-learning and temporal difference (TD) learning-even though they have divergence issues and sound Gradient TD alternatives exist-because divergence seems rare and they typically perform well. However, recent work with large neural network learning systems reveals that instability is more common than previously thought. Practitioners face a difficult dilemma: choose an easy to use and performant TD method, or a more complex algorithm that is more sound but harder to tune and all but unexplored with non-linear function approximation or control. In this paper, we introduce a new method called TD with Regularized Corrections (TDRC), that attempts to balance ease of use, soundness, and performance. It behaves as well as TD, when TD performs well, but is sound in cases where TD diverges. We empirically investigate TDRC across a range of problems, for both prediction and control, and for both linear and non-linear function approximation, and show, potentially for the first time, that gradient TD methods could be a better alternative to TD and Q-learning.