 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving UnderEdit & OverEdit with Iterative & Neighbor-Assisted Model Editing
Mar 14, 2025Large Language Models (LLMs) are used in various downstream language tasks, making it crucial to keep their knowledge up-to-date, but both retraining and fine-tuning the model can be costly. Model editing offers an efficient and effective alternative by a single update to only a key subset of model parameters. While being efficient, these methods are not perfect. Sometimes knowledge edits are unsuccessful, i.e., UnderEdit, or the edit contaminated neighboring knowledge that should remain unchanged, i.e., OverEdit. To address these limitations, we propose iterative model editing, based on our hypothesis that a single parameter update is often insufficient, to mitigate UnderEdit, and neighbor-assisted model editing, which incorporates neighboring knowledge during editing to minimize OverEdit. Extensive experiments demonstrate that our methods effectively reduce UnderEdit up to 38 percentage points and OverEdit up to 6 percentage points across multiple model editing algorithms, LLMs, and benchmark datasets.
Position: Benchmarking is Limited in Reinforcement Learning Research
Jun 23, 2024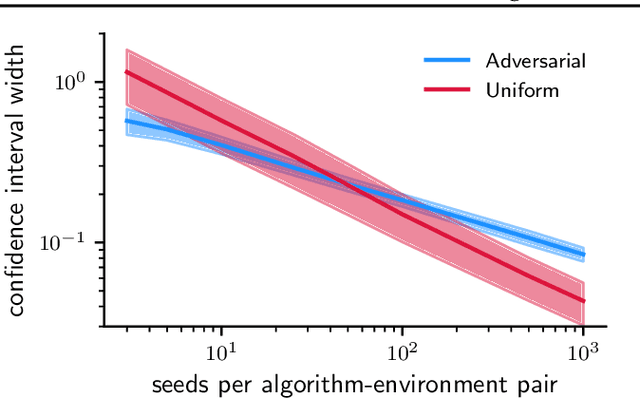

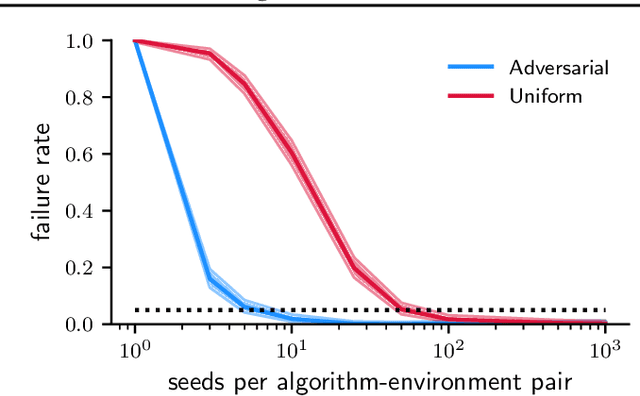
Novel reinforcement learning algorithms, or improvements on existing ones, are commonly justified by evaluating their performance on benchmark environments and are compared to an ever-changing set of standard algorithms. However, despite numerous calls for improvements, experimental practices continue to produce misleading or unsupported claims. One reason for the ongoing substandard practices is that conducting rigorous benchmarking experiments requires substantial computational time. This work investigates the sources of increased computation costs in rigorous experiment designs. We show that conducting rigorous performance benchmarks will likely have computational costs that are often prohibitive. As a result, we argue for using an additional experimentation paradigm to overcome the limitations of benchmarking.
A New View on Planning in Online Reinforcement Learning
Jun 03, 2024



This paper investigates a new approach to model-based reinforcement learning using background planning: mixing (approximate) dynamic programming updates and model-free updates, similar to the Dyna architecture. Background planning with learned models is often worse than model-free alternatives, such as Double DQN, even though the former uses significantly more memory and computation. The fundamental problem is that learned models can be inaccurate and often generate invalid states, especially when iterated many steps. In this paper, we avoid this limitation by constraining background planning to a set of (abstract) subgoals and learning only local, subgoal-conditioned models. This goal-space planning (GSP) approach is more computationally efficient, naturally incorporates temporal abstraction for faster long-horizon planning and avoids learning the transition dynamics entirely. We show that our GSP algorithm can propagate value from an abstract space in a manner that helps a variety of base learners learn significantly faster in different domains.
From Past to Future: Rethinking Eligibility Traces
Dec 20, 2023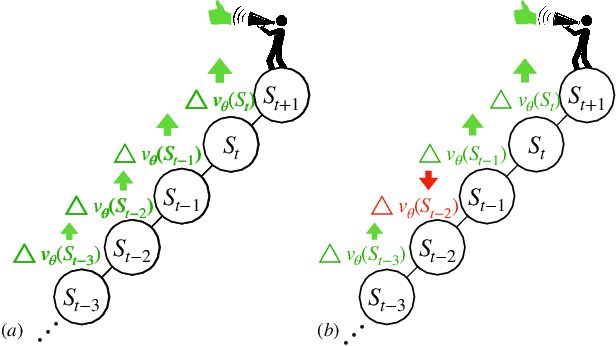
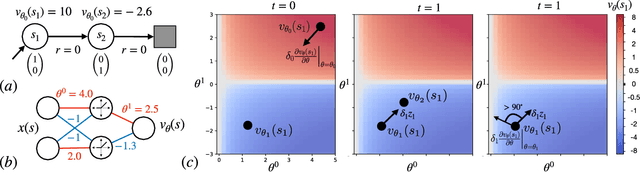
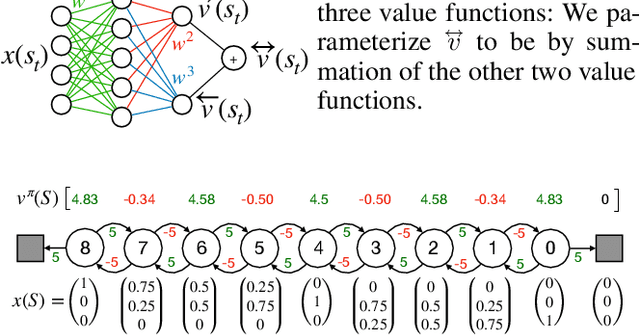
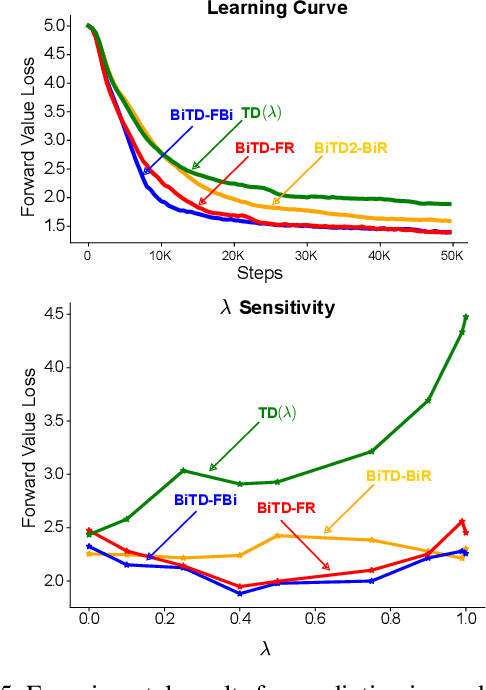
In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we refer to as the \emph{bidirectional value function}. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, perform policy evaluation more rapidly than TD($\lambda$) -- a method that learns forward value functions, $v^\pi$, \emph{directly}. Overall, our findings present a new perspective on eligibility traces and potential advantages associated with the novel value function it inspires, especially for policy evaluation.
Behavior Alignment via Reward Function Optimization
Oct 31, 2023



Designing reward functions for efficiently guiding reinforcement learning (RL) agents toward specific behaviors is a complex task. This is challenging since it requires the identification of reward structures that are not sparse and that avoid inadvertently inducing undesirable behaviors. Naively modifying the reward structure to offer denser and more frequent feedback can lead to unintended outcomes and promote behaviors that are not aligned with the designer's intended goal. Although potential-based reward shaping is often suggested as a remedy, we systematically investigate settings where deploying it often significantly impairs performance. To address these issues, we introduce a new framework that uses a bi-level objective to learn \emph{behavior alignment reward functions}. These functions integrate auxiliary rewards reflecting a designer's heuristics and domain knowledge with the environment's primary rewards. Our approach automatically determines the most effective way to blend these types of feedback, thereby enhancing robustness against heuristic reward misspecification. Remarkably, it can also adapt an agent's policy optimization process to mitigate suboptimalities resulting from limitations and biases inherent in the underlying RL algorithms. We evaluate our method's efficacy on a diverse set of tasks, from small-scale experiments to high-dimensional control challenges. We investigate heuristic auxiliary rewards of varying quality -- some of which are beneficial and others detrimental to the learning process. Our results show that our framework offers a robust and principled way to integrate designer-specified heuristics. It not only addresses key shortcomings of existing approaches but also consistently leads to high-performing solutions, even when given misaligned or poorly-specified auxiliary reward functions.
Coagent Networks: Generalized and Scaled
May 16, 2023

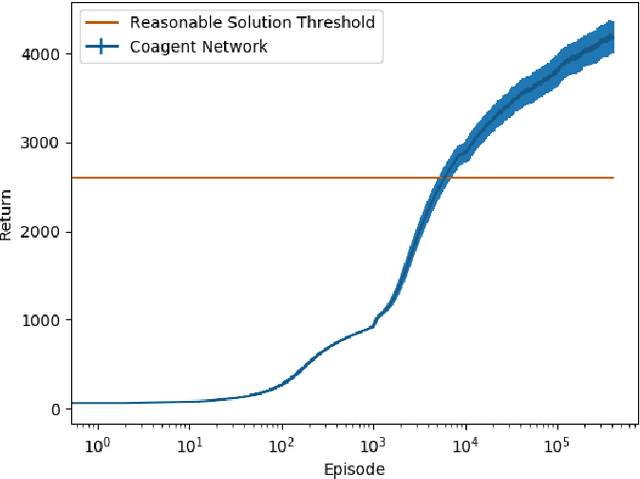
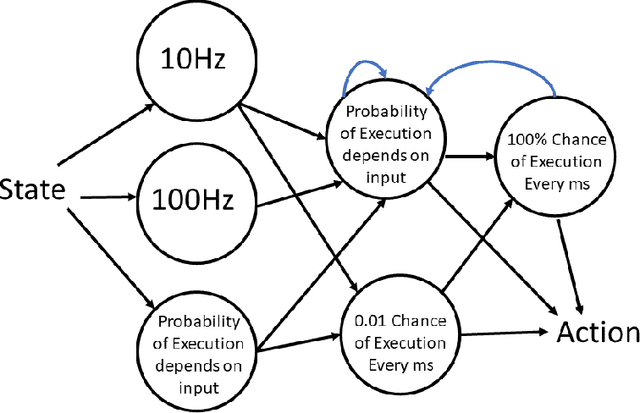
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011] provide a powerful and flexible framework for deriving principled learning rules for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of backpropagation's main limitations. For example, coagent networks can compute different parts of the network \emph{asynchronously} (at different rates or at different times), can incorporate non-differentiable components that cannot be used with backpropagation, and can explore at levels higher than their action spaces (that is, they can be designed as hierarchical networks for exploration and/or temporal abstraction). However, the coagent framework is not just an alternative to BDL; the two approaches can be blended: BDL can be combined with coagent learning rules to create architectures with the advantages of both approaches. This work generalizes the coagent theory and learning rules provided by previous works; this generalization provides more flexibility for network architecture design within the coagent framework. This work also studies one of the chief disadvantages of coagent networks: high variance updates for networks that have many coagents and do not use backpropagation. We show that a coagent algorithm with a policy network that does not use backpropagation can scale to a challenging RL domain with a high-dimensional state and action space (the MuJoCo Ant environment), learning reasonable (although not state-of-the-art) policies. These contributions motivate and provide a more general theoretical foundation for future work that studies coagent networks.
Avoiding Model Estimation in Robust Markov Decision Processes with a Generative Model
Feb 02, 2023Robust Markov Decision Processes (MDPs) are getting more attention for learning a robust policy which is less sensitive to environment changes. There are an increasing number of works analyzing sample-efficiency of robust MDPs. However, most works study robust MDPs in a model-based regime, where the transition probability needs to be estimated and requires $\mathcal{O}(|\mathcal{S}|^2|\mathcal{A}|)$ storage in memory. A common way to solve robust MDPs is to formulate them as a distributionally robust optimization (DRO) problem. However, solving a DRO problem is non-trivial, so prior works typically assume a strong oracle to obtain the optimal solution of the DRO problem easily. To remove the need for an oracle, we first transform the original robust MDPs into an alternative form, as the alternative form allows us to use stochastic gradient methods to solve the robust MDPs. Moreover, we prove the alternative form still preserves the role of robustness. With this new formulation, we devise a sample-efficient algorithm to solve the robust MDPs in a model-free regime, from which we benefit lower memory space $\mathcal{O}(|\mathcal{S}||\mathcal{A}|)$ without using the oracle. Finally, we validate our theoretical findings via numerical experiments and show the efficiency to solve the alternative form of robust MDPs.
Towards Safe Policy Improvement for Non-Stationary MDPs
Oct 23, 2020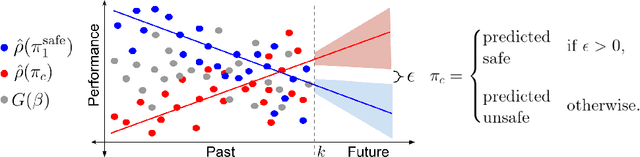
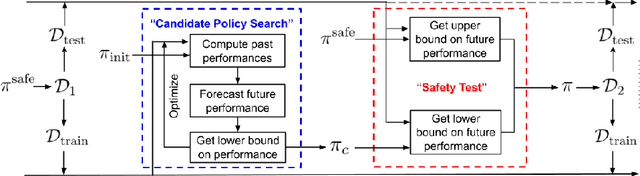

Many real-world sequential decision-making problems involve critical systems with financial risks and human-life risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. We take the first steps towards ensuring safety, with high confidence, for smoothly-varying non-stationary decision problems. Our proposed method extends a type of safe algorithm, called a Seldonian algorithm, through a synthesis of model-free reinforcement learning with time-series analysis. Safety is ensured using sequential hypothesis testing of a policy's forecasted performance, and confidence intervals are obtained using wild bootstrap.
Evaluating the Performance of Reinforcement Learning Algorithms
Jun 30, 2020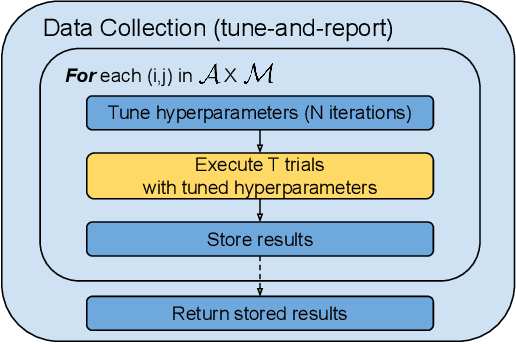
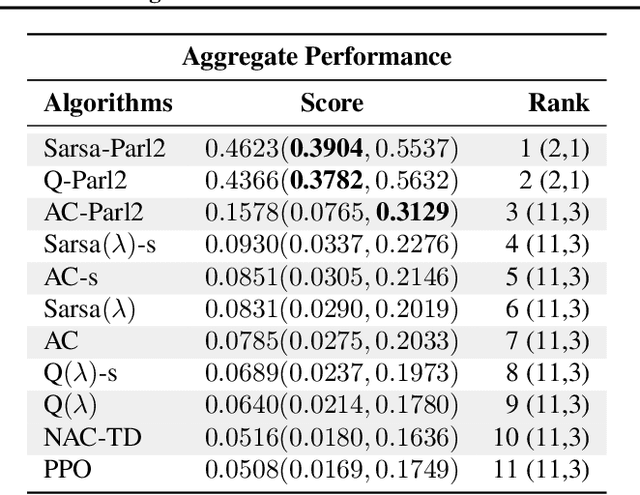
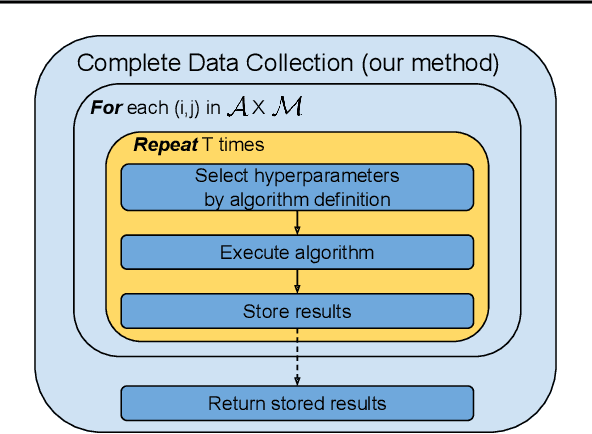
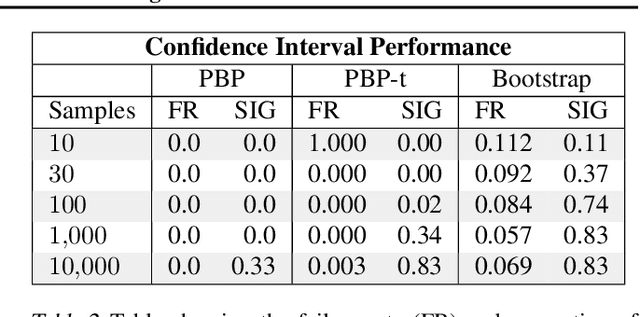
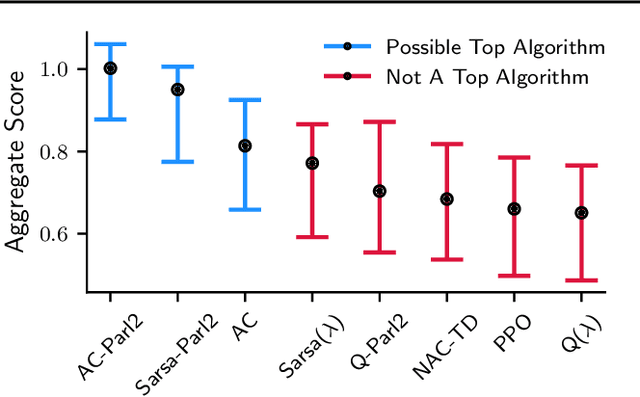
Performance evaluations are critical for quantifying algorithmic advances in reinforcement learning. Recent reproducibility analyses have shown that reported performance results are often inconsistent and difficult to replicate. In this work, we argue that the inconsistency of performance stems from the use of flawed evaluation metrics. Taking a step towards ensuring that reported results are consistent, we propose a new comprehensive evaluation methodology for reinforcement learning algorithms that produces reliable measurements of performance both on a single environment and when aggregated across environments. We demonstrate this method by evaluating a broad class of reinforcement learning algorithms on standard benchmark tasks.
Classical Policy Gradient: Preserving Bellman's Principle of Optimality
Jun 06, 2019We propose a new objective function for finite-horizon episodic Markov decision processes that better captures Bellman's principle of optimality, and provide an expression for the gradient of the objective.