 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical Policy Gradient: Preserving Bellman's Principle of Optimality
Jun 06, 2019We propose a new objective function for finite-horizon episodic Markov decision processes that better captures Bellman's principle of optimality, and provide an expression for the gradient of the objective.
Asynchronous Coagent Networks: Stochastic Networks for Reinforcement Learning without Backpropagation or a Clock
Feb 21, 2019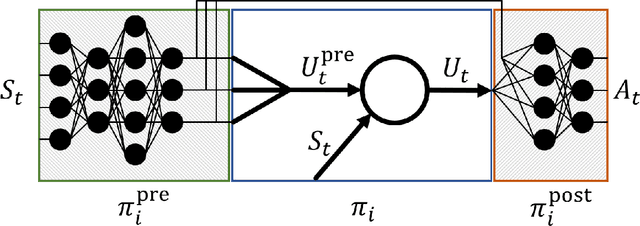
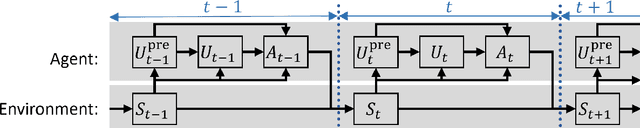
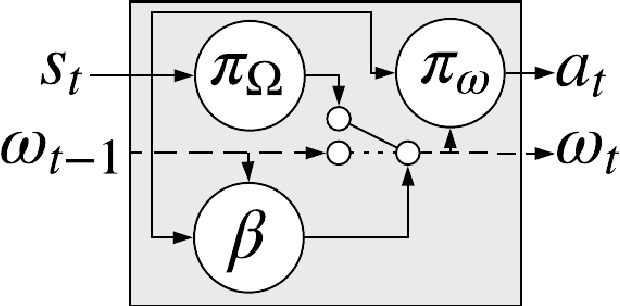
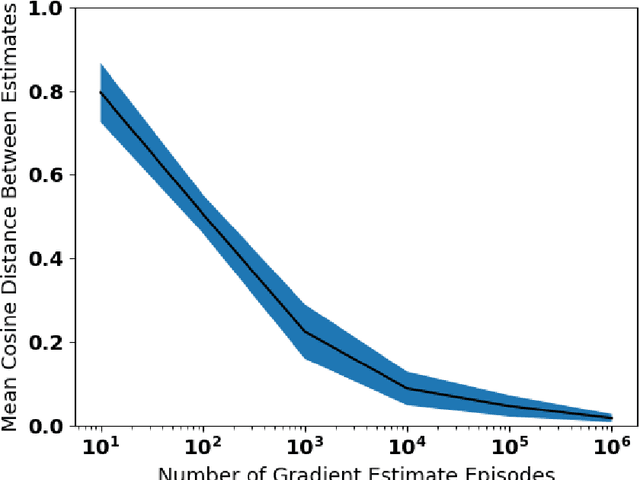
In this paper we introduce a reinforcement learning (RL) approach for training policies, including artificial neural network policies, that is both backpropagation-free and clock-free. It is backpropagation-free in that it does not propagate any information backwards through the network. It is clock-free in that no signal is given to each node in the network to specify when it should compute its output and when it should update its weights. We contend that these two properties increase the biological plausibility of our algorithms and facilitate distributed implementations. Additionally, our approach eliminates the need for customized learning rules for hierarchical RL algorithms like the option-critic.
Learning Action Representations for Reinforcement Learning
Feb 01, 2019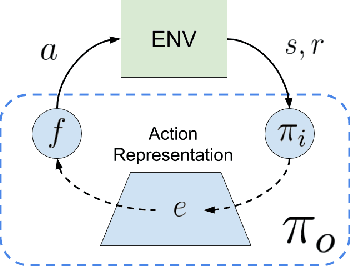
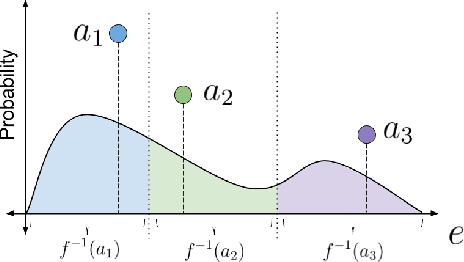
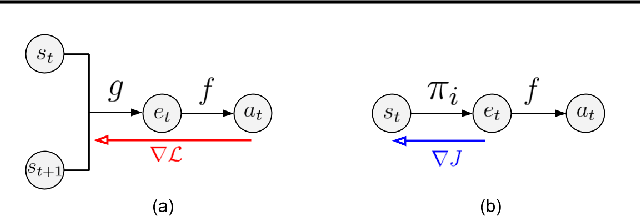
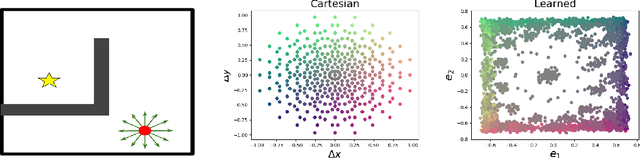
Most model-free reinforcement learning methods leverage state representations (embeddings) for generalization, but either ignore structure in the space of actions or assume the structure is provided a priori. We show how a policy can be decomposed into a component that acts in a low-dimensional space of action representations and a component that transforms these representations into actual actions. These representations improve generalization over large, finite action sets by allowing the agent to infer the outcomes of actions similar to actions already taken. We provide an algorithm to both learn and use action representations and provide conditions for its convergence. The efficacy of the proposed method is demonstrated on large-scale real-world problems.