 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoagent Networks: Generalized and Scaled
May 16, 2023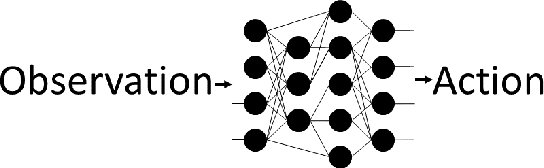

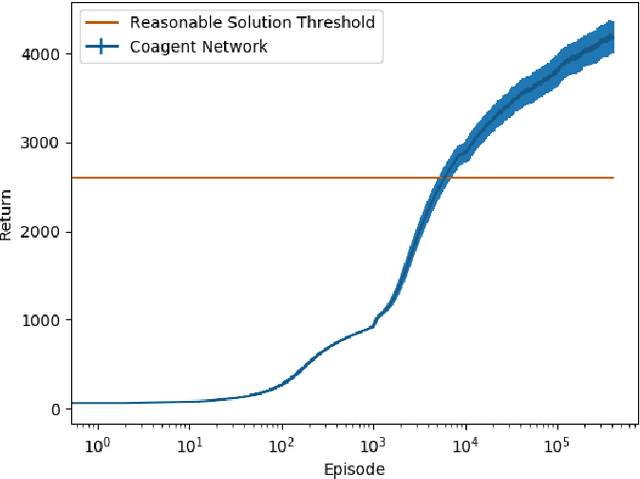
Coagent networks for reinforcement learning (RL) [Thomas and Barto, 2011] provide a powerful and flexible framework for deriving principled learning rules for arbitrary stochastic neural networks. The coagent framework offers an alternative to backpropagation-based deep learning (BDL) that overcomes some of backpropagation's main limitations. For example, coagent networks can compute different parts of the network \emph{asynchronously} (at different rates or at different times), can incorporate non-differentiable components that cannot be used with backpropagation, and can explore at levels higher than their action spaces (that is, they can be designed as hierarchical networks for exploration and/or temporal abstraction). However, the coagent framework is not just an alternative to BDL; the two approaches can be blended: BDL can be combined with coagent learning rules to create architectures with the advantages of both approaches. This work generalizes the coagent theory and learning rules provided by previous works; this generalization provides more flexibility for network architecture design within the coagent framework. This work also studies one of the chief disadvantages of coagent networks: high variance updates for networks that have many coagents and do not use backpropagation. We show that a coagent algorithm with a policy network that does not use backpropagation can scale to a challenging RL domain with a high-dimensional state and action space (the MuJoCo Ant environment), learning reasonable (although not state-of-the-art) policies. These contributions motivate and provide a more general theoretical foundation for future work that studies coagent networks.
Edge-Compatible Reinforcement Learning for Recommendations
Dec 10, 2021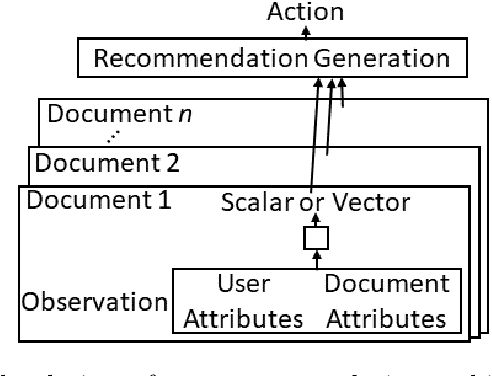
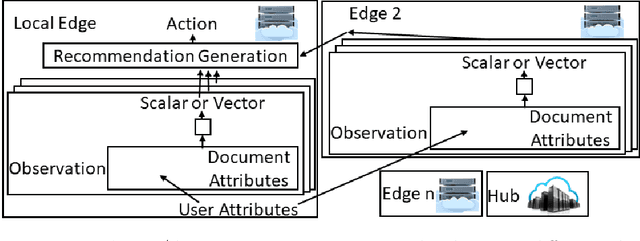
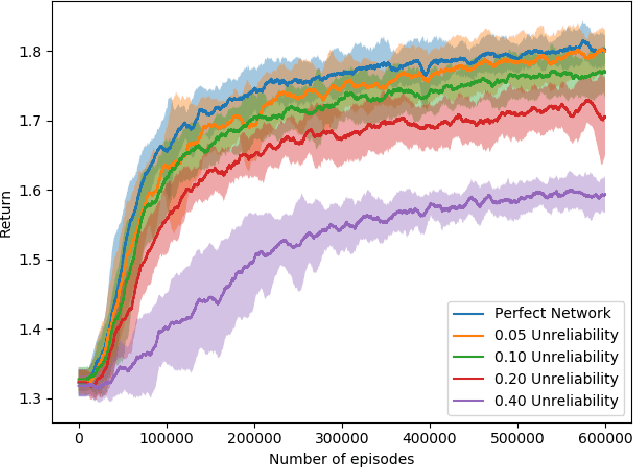
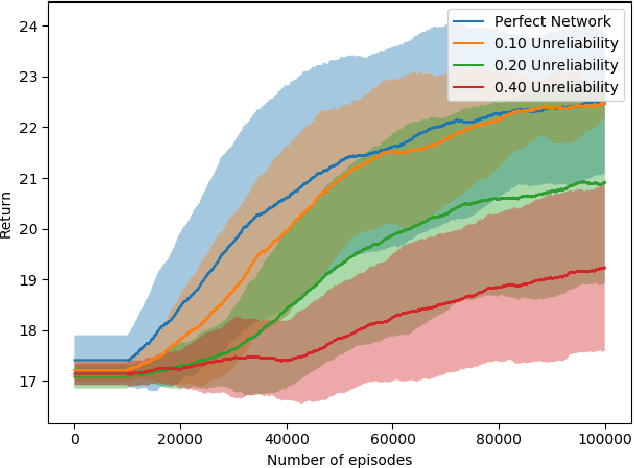
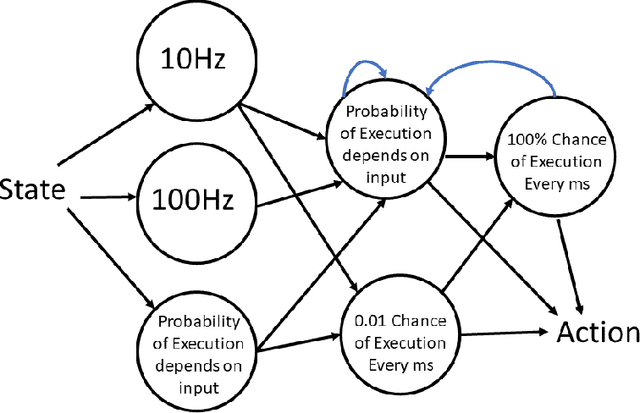
Most reinforcement learning (RL) recommendation systems designed for edge computing must either synchronize during recommendation selection or depend on an unprincipled patchwork collection of algorithms. In this work, we build on asynchronous coagent policy gradient algorithms \citep{kostas2020asynchronous} to propose a principled solution to this problem. The class of algorithms that we propose can be distributed over the internet and run asynchronously and in real-time. When a given edge fails to respond to a request for data with sufficient speed, this is not a problem; the algorithm is designed to function and learn in the edge setting, and network issues are part of this setting. The result is a principled, theoretically grounded RL algorithm designed to be distributed in and learn in this asynchronous environment. In this work, we describe this algorithm and a proposed class of architectures in detail, and demonstrate that they work well in practice in the asynchronous setting, even as the network quality degrades.