 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Strategies for More Efficient and Accurate Agentic RAG
Mar 12, 2026Retrieval-Augmented Generation (RAG) systems face challenges with complex, multihop questions, and agentic frameworks such as Search-R1 (Jin et al., 2025), which operates iteratively, have been proposed to address these complexities. However, such approaches can introduce inefficiencies, including repetitive retrieval of previously processed information and challenges in contextualizing retrieved results effectively within the current generation prompt. Such issues can lead to unnecessary retrieval turns, suboptimal reasoning, inaccurate answers, and increased token consumption. In this paper, we investigate test-time modifications to the Search-R1 pipeline to mitigate these identified shortcomings. Specifically, we explore the integration of two components and their combination: a contextualization module to better integrate relevant information from retrieved documents into reasoning, and a de-duplication module that replaces previously retrieved documents with the next most relevant ones. We evaluate our approaches using the HotpotQA (Yang et al., 2018) and the Natural Questions (Kwiatkowski et al., 2019) datasets, reporting the exact match (EM) score, an LLM-as-a-Judge assessment of answer correctness, and the average number of turns. Our best-performing variant, utilizing GPT-4.1-mini for contextualization, achieves a 5.6% increase in EM score and reduces the number of turns by 10.5% compared to the Search-R1 baseline, demonstrating improved answer accuracy and retrieval efficiency.
GLUE: Gradient-free Learning to Unify Experts
Dec 27, 2025In many deployed systems (multilingual ASR, cross-hospital imaging, region-specific perception), multiple pretrained specialist models coexist. Yet, new target domains often require domain expansion: a generalized model that performs well beyond any single specialist's domain. Given such a new target domain, prior works seek a single strong initialization prior for the model parameters by first blending expert models to initialize a target model. However, heuristic blending -- using coefficients based on data size or proxy metrics -- often yields lower target-domain test accuracy, and learning the coefficients on the target loss typically requires computationally-expensive full backpropagation through the network. We propose GLUE, Gradient-free Learning To Unify Experts, which initializes the target model as a convex combination of fixed experts, learning the mixture coefficients of this combination via a gradient-free two-point (SPSA) update that requires only two forward passes per step. Across experiments on three datasets and three network architectures, GLUE produces a single prior that can be fine-tuned effectively to outperform baselines. GLUE improves test accuracy by up to 8.5% over data-size weighting and by up to 9.1% over proxy-metric selection. GLUE either outperforms backpropagation-based full-gradient mixing or matches its performance within 1.4%.
GradNetOT: Learning Optimal Transport Maps with GradNets
Jul 17, 2025Monotone gradient functions play a central role in solving the Monge formulation of the optimal transport problem, which arises in modern applications ranging from fluid dynamics to robot swarm control. When the transport cost is the squared Euclidean distance, Brenier's theorem guarantees that the unique optimal map is the gradient of a convex function, namely a monotone gradient map, and it satisfies a Monge-Amp\`ere equation. In [arXiv:2301.10862] [arXiv:2404.07361], we proposed Monotone Gradient Networks (mGradNets), neural networks that directly parameterize the space of monotone gradient maps. In this work, we leverage mGradNets to directly learn the optimal transport mapping by minimizing a training loss function defined using the Monge-Amp\`ere equation. We empirically show that the structural bias of mGradNets facilitates the learning of optimal transport maps and employ our method for a robot swarm control problem.
Agent Context Protocols Enhance Collective Inference
May 20, 2025AI agents have become increasingly adept at complex tasks such as coding, reasoning, and multimodal understanding. However, building generalist systems requires moving beyond individual agents to collective inference -- a paradigm where multi-agent systems with diverse, task-specialized agents complement one another through structured communication and collaboration. Today, coordination is usually handled with imprecise, ad-hoc natural language, which limits complex interaction and hinders interoperability with domain-specific agents. We introduce Agent context protocols (ACPs): a domain- and agent-agnostic family of structured protocols for agent-agent communication, coordination, and error handling. ACPs combine (i) persistent execution blueprints -- explicit dependency graphs that store intermediate agent outputs -- with (ii) standardized message schemas, enabling robust and fault-tolerant multi-agent collective inference. ACP-powered generalist systems reach state-of-the-art performance: 28.3 % accuracy on AssistantBench for long-horizon web assistance and best-in-class multimodal technical reports, outperforming commercial AI systems in human evaluation. ACPs are highly modular and extensible, allowing practitioners to build top-tier generalist agents quickly.
ReLU Networks as Random Functions: Their Distribution in Probability Space
Mar 28, 2025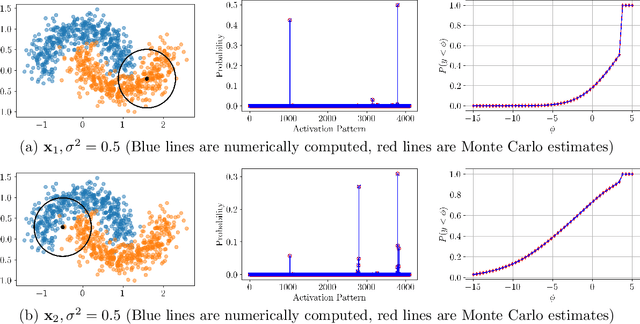

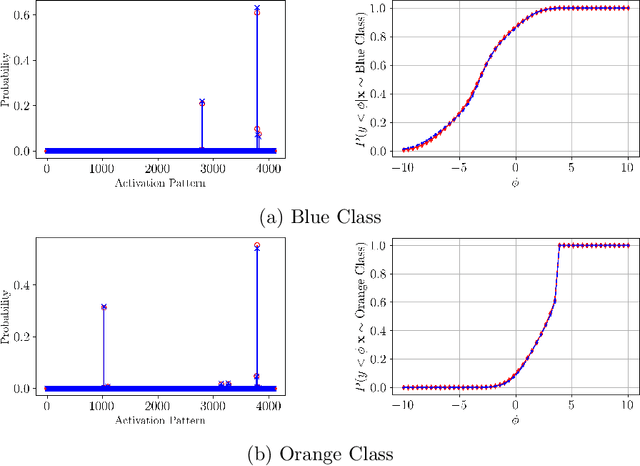

This paper presents a novel framework for understanding trained ReLU networks as random, affine functions, where the randomness is induced by the distribution over the inputs. By characterizing the probability distribution of the network's activation patterns, we derive the discrete probability distribution over the affine functions realizable by the network. We extend this analysis to describe the probability distribution of the network's outputs. Our approach provides explicit, numerically tractable expressions for these distributions in terms of Gaussian orthant probabilities. Additionally, we develop approximation techniques to identify the support of affine functions a trained ReLU network can realize for a given distribution of inputs. Our work provides a framework for understanding the behavior and performance of ReLU networks corresponding to stochastic inputs, paving the way for more interpretable and reliable models.
Abstract Reward Processes: Leveraging State Abstraction for Consistent Off-Policy Evaluation
Oct 03, 2024Evaluating policies using off-policy data is crucial for applying reinforcement learning to real-world problems such as healthcare and autonomous driving. Previous methods for off-policy evaluation (OPE) generally suffer from high variance or irreducible bias, leading to unacceptably high prediction errors. In this work, we introduce STAR, a framework for OPE that encompasses a broad range of estimators -- which include existing OPE methods as special cases -- that achieve lower mean squared prediction errors. STAR leverages state abstraction to distill complex, potentially continuous problems into compact, discrete models which we call abstract reward processes (ARPs). Predictions from ARPs estimated from off-policy data are provably consistent (asymptotically correct). Rather than proposing a specific estimator, we present a new framework for OPE and empirically demonstrate that estimators within STAR outperform existing methods. The best STAR estimator outperforms baselines in all twelve cases studied, and even the median STAR estimator surpasses the baselines in seven out of the twelve cases.
Quantifying reliance on external information over parametric knowledge during Retrieval Augmented Generation (RAG) using mechanistic analysis
Oct 01, 2024Retrieval Augmented Generation (RAG) is a widely used approach for leveraging external context in several natural language applications such as question answering and information retrieval. Yet, the exact nature in which a Language Model (LM) leverages this non-parametric memory or retrieved context isn't clearly understood. This paper mechanistically examines the RAG pipeline to highlight that LMs demonstrate a "shortcut'' effect and have a strong bias towards utilizing the retrieved context to answer questions, while relying minimally on model priors. We propose (a) Causal Mediation Analysis; for proving that parametric memory is minimally utilized when answering a question and (b) Attention Contributions and Knockouts for showing the last token residual stream do not get enriched from the subject token in the question, but gets enriched from tokens of RAG-context. We find this pronounced "shortcut'' behaviour to be true across both LLMs (e.g.,LlaMa) and SLMs (e.g., Phi)
PersonaGym: Evaluating Persona Agents and LLMs
Jul 29, 2024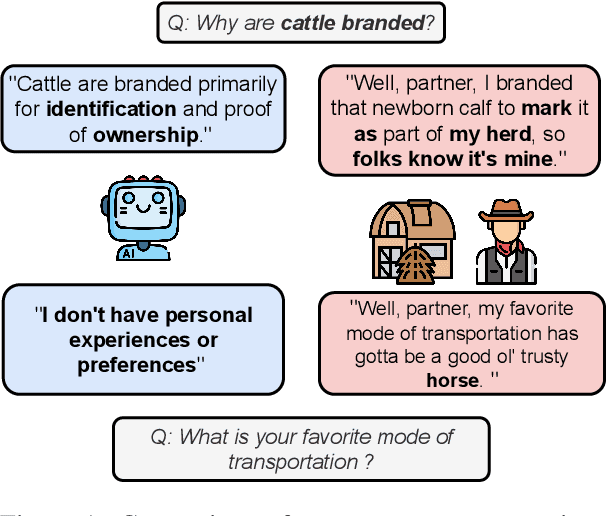
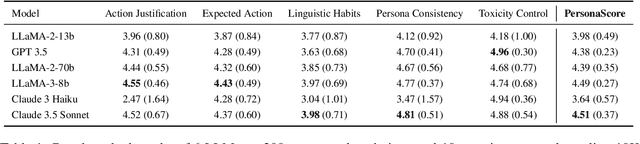
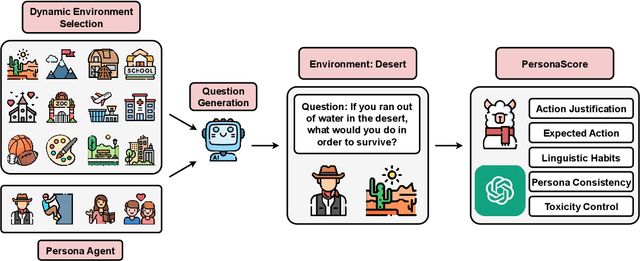

Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model. Importantly, we find that increased model size and complexity do not necessarily imply enhanced persona agent capabilities thereby highlighting the pressing need for algorithmic and architectural invention towards faithful and performant persona agents.
From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries
Jun 18, 2024



Retrieval Augmented Generation (RAG) enriches the ability of language models to reason using external context to augment responses for a given user prompt. This approach has risen in popularity due to practical applications in various applications of language models in search, question/answering, and chat-bots. However, the exact nature of how this approach works isn't clearly understood. In this paper, we mechanistically examine the RAG pipeline to highlight that language models take shortcut and have a strong bias towards utilizing only the context information to answer the question, while relying minimally on their parametric memory. We probe this mechanistic behavior in language models with: (i) Causal Mediation Analysis to show that the parametric memory is minimally utilized when answering a question and (ii) Attention Contributions and Knockouts to show that the last token residual stream do not get enriched from the subject token in the question, but gets enriched from other informative tokens in the context. We find this pronounced shortcut behaviour true across both LLaMa and Phi family of models.
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Apr 12, 2024



State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.