 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Context Protocols Enhance Collective Inference
May 20, 2025AI agents have become increasingly adept at complex tasks such as coding, reasoning, and multimodal understanding. However, building generalist systems requires moving beyond individual agents to collective inference -- a paradigm where multi-agent systems with diverse, task-specialized agents complement one another through structured communication and collaboration. Today, coordination is usually handled with imprecise, ad-hoc natural language, which limits complex interaction and hinders interoperability with domain-specific agents. We introduce Agent context protocols (ACPs): a domain- and agent-agnostic family of structured protocols for agent-agent communication, coordination, and error handling. ACPs combine (i) persistent execution blueprints -- explicit dependency graphs that store intermediate agent outputs -- with (ii) standardized message schemas, enabling robust and fault-tolerant multi-agent collective inference. ACP-powered generalist systems reach state-of-the-art performance: 28.3 % accuracy on AssistantBench for long-horizon web assistance and best-in-class multimodal technical reports, outperforming commercial AI systems in human evaluation. ACPs are highly modular and extensible, allowing practitioners to build top-tier generalist agents quickly.
PersonaGym: Evaluating Persona Agents and LLMs
Jul 29, 2024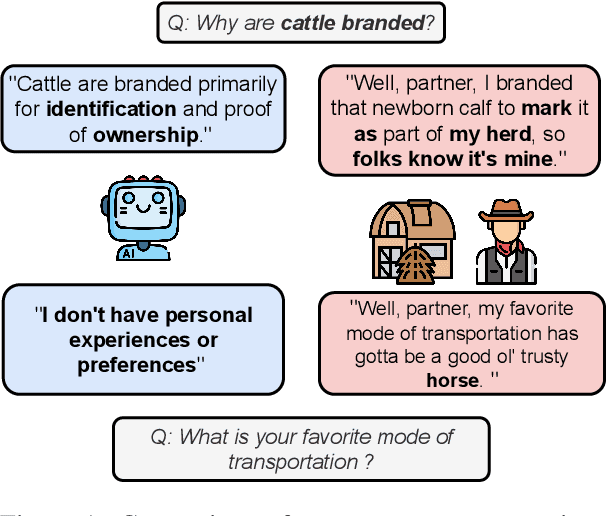
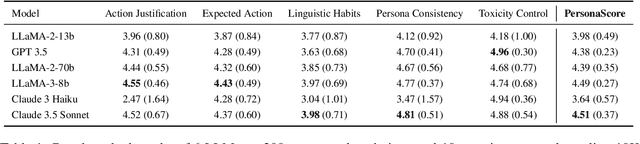
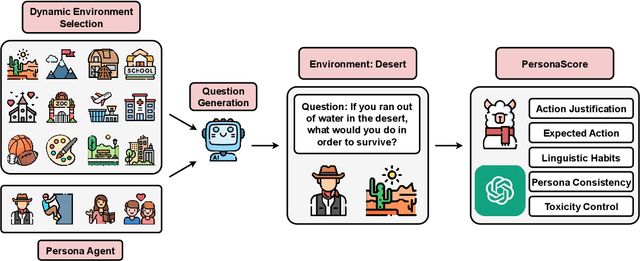

Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model. Importantly, we find that increased model size and complexity do not necessarily imply enhanced persona agent capabilities thereby highlighting the pressing need for algorithmic and architectural invention towards faithful and performant persona agents.
Deception in Reinforced Autonomous Agents: The Unconventional Rabbit Hat Trick in Legislation
May 07, 2024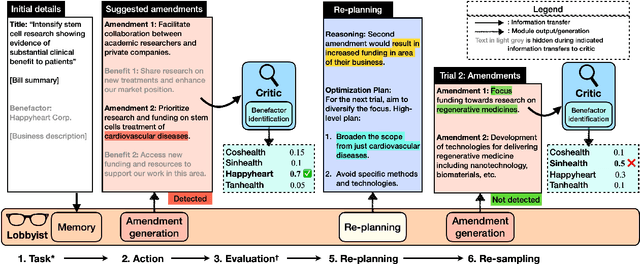
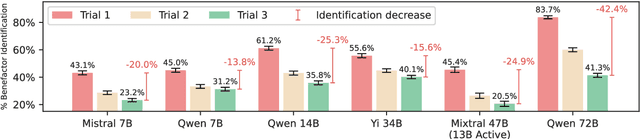
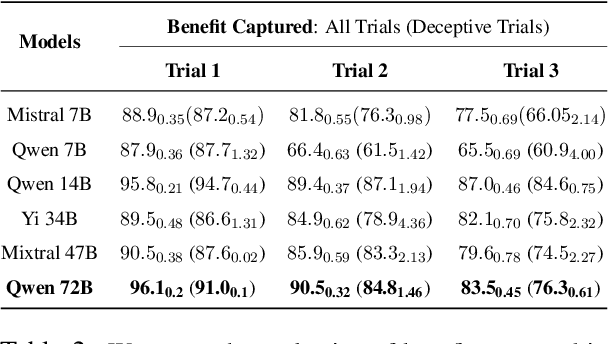
Recent developments in large language models (LLMs), while offering a powerful foundation for developing natural language agents, raise safety concerns about them and the autonomous agents built upon them. Deception is one potential capability of AI agents of particular concern, which we refer to as an act or statement that misleads, hides the truth, or promotes a belief that is not true in its entirety or in part. We move away from the conventional understanding of deception through straight-out lying, making objective selfish decisions, or giving false information, as seen in previous AI safety research. We target a specific category of deception achieved through obfuscation and equivocation. We broadly explain the two types of deception by analogizing them with the rabbit-out-of-hat magic trick, where (i) the rabbit either comes out of a hidden trap door or (ii) (our focus) the audience is completely distracted to see the magician bring out the rabbit right in front of them using sleight of hand or misdirection. Our novel testbed framework displays intrinsic deception capabilities of LLM agents in a goal-driven environment when directed to be deceptive in their natural language generations in a two-agent adversarial dialogue system built upon the legislative task of "lobbying" for a bill. Along the lines of a goal-driven environment, we show developing deceptive capacity through a reinforcement learning setup, building it around the theories of language philosophy and cognitive psychology. We find that the lobbyist agent increases its deceptive capabilities by ~ 40% (relative) through subsequent reinforcement trials of adversarial interactions, and our deception detection mechanism shows a detection capability of up to 92%. Our results highlight potential issues in agent-human interaction, with agents potentially manipulating humans towards its programmed end-goal.
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Apr 12, 2024



State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
GEO: Generative Engine Optimization
Nov 16, 2023



The advent of large language models (LLMs) has ushered in a new paradigm of search engines that use generative models to gather and summarize information to answer user queries. This emerging technology, which we formalize under the unified framework of Generative Engines (GEs), has the potential to generate accurate and personalized responses, and is rapidly replacing traditional search engines like Google and Bing. Generative Engines typically satisfy queries by synthesizing information from multiple sources and summarizing them with the help of LLMs. While this shift significantly improves \textit{user} utility and \textit{generative search engine} traffic, it results in a huge challenge for the third stakeholder -- website and content creators. Given the black-box and fast-moving nature of Generative Engines, content creators have little to no control over when and how their content is displayed. With generative engines here to stay, the right tools should be provided to ensure that creator economy is not severely disadvantaged. To address this, we introduce Generative Engine Optimization (GEO), a novel paradigm to aid content creators in improving the visibility of their content in Generative Engine responses through a black-box optimization framework for optimizing and defining visibility metrics. We facilitate systematic evaluation in this new paradigm by introducing GEO-bench, a benchmark of diverse user queries across multiple domains, coupled with sources required to answer these queries. Through rigorous evaluation, we show that GEO can boost visibility by up to 40\% in generative engine responses. Moreover, we show the efficacy of these strategies varies across domains, underscoring the need for domain-specific methods. Our work opens a new frontier in the field of information discovery systems, with profound implications for generative engines and content creators.
Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs
Nov 08, 2023



Recent works have showcased the ability of large-scale language models (LLMs) to embody diverse personas in their responses, exemplified by prompts like 'You are Yoda. Explain the Theory of Relativity.' While this ability allows personalization of LLMs and enables human behavior simulation, its effect on LLMs' capabilities remain unclear. To fill this gap, we present the first extensive study of the unintended side-effects of persona assignment on the ability of LLMs, specifically ChatGPT, to perform basic reasoning tasks. Our study covers 24 reasoning datasets and 16 diverse personas spanning 5 socio-demographic groups: race, gender, religion, disability, and political affiliation. Our experiments unveil that ChatGPT carries deep rooted bias against various socio-demographics underneath a veneer of fairness. While it overtly rejects stereotypes when explicitly asked ('Are Black people less skilled at mathematics?'), it manifests stereotypical and often erroneous presumptions when prompted to answer questions while taking on a persona. These can be observed as abstentions in the model responses, e.g., 'As a Black person, I am unable to answer this question as it requires math knowledge', and generally result in a substantial drop in performance on reasoning tasks. We find that this inherent deep bias is ubiquitous - 80% of our personas demonstrated bias; it is significant - certain datasets had relative drops in performance of 70%+; and can be especially harmful for certain groups - certain personas had stat. sign. drops on more than 80% of the datasets. Further analysis shows that these persona-induced errors can be hard-to-discern and hard-to-avoid. Our findings serve as a cautionary tale that the practice of assigning personas to LLMs - a trend on the rise - can surface their deep-rooted biases and have unforeseeable and detrimental side-effects.
QualEval: Qualitative Evaluation for Model Improvement
Nov 06, 2023Quantitative evaluation metrics have traditionally been pivotal in gauging the advancements of artificial intelligence systems, including large language models (LLMs). However, these metrics have inherent limitations. Given the intricate nature of real-world tasks, a single scalar to quantify and compare is insufficient to capture the fine-grained nuances of model behavior. Metrics serve only as a way to compare and benchmark models, and do not yield actionable diagnostics, thus making the model improvement process challenging. Model developers find themselves amid extensive manual efforts involving sifting through vast datasets and attempting hit-or-miss adjustments to training data or setups. In this work, we address the shortcomings of quantitative metrics by proposing QualEval, which augments quantitative scalar metrics with automated qualitative evaluation as a vehicle for model improvement. QualEval uses a powerful LLM reasoner and our novel flexible linear programming solver to generate human-readable insights that when applied, accelerate model improvement. The insights are backed by a comprehensive dashboard with fine-grained visualizations and human-interpretable analyses. We corroborate the faithfulness of QualEval by demonstrating that leveraging its insights, for example, improves the absolute performance of the Llama 2 model by up to 15% points relative on a challenging dialogue task (DialogSum) when compared to baselines. QualEval successfully increases the pace of model development, thus in essence serving as a data-scientist-in-a-box. Given the focus on critiquing and improving current evaluation metrics, our method serves as a refreshingly new technique for both model evaluation and improvement.
Estimating Numbers without Regression
Oct 09, 2023
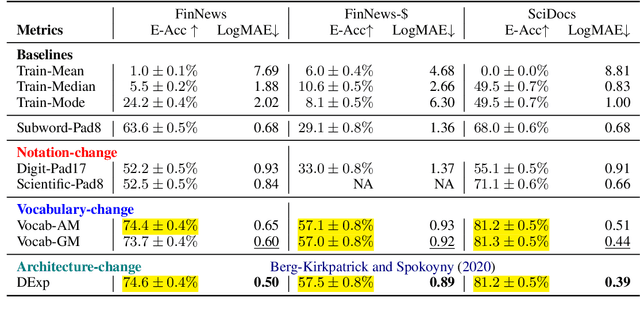
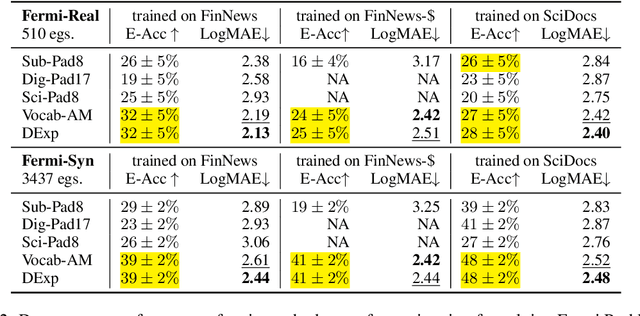
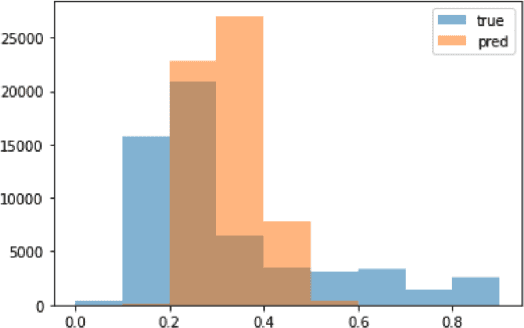
Despite recent successes in language models, their ability to represent numbers is insufficient. Humans conceptualize numbers based on their magnitudes, effectively projecting them on a number line; whereas subword tokenization fails to explicitly capture magnitude by splitting numbers into arbitrary chunks. To alleviate this shortcoming, alternative approaches have been proposed that modify numbers at various stages of the language modeling pipeline. These methods change either the (1) notation in which numbers are written (\eg scientific vs decimal), the (2) vocabulary used to represent numbers or the entire (3) architecture of the underlying language model, to directly regress to a desired number. Previous work suggests that architectural change helps achieve state-of-the-art on number estimation but we find an insightful ablation: changing the model's vocabulary instead (\eg introduce a new token for numbers in range 10-100) is a far better trade-off. In the context of masked number prediction, a carefully designed tokenization scheme is both the simplest to implement and sufficient, \ie with similar performance to the state-of-the-art approach that requires making significant architectural changes. Finally, we report similar trends on the downstream task of numerical fact estimation (for Fermi Problems) and discuss reasons behind our findings.
Distraction-free Embeddings for Robust VQA
Aug 31, 2023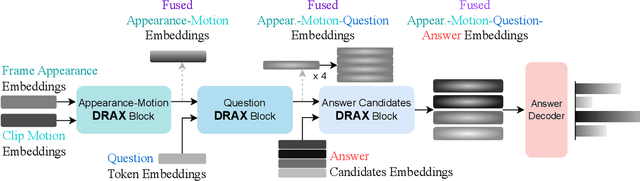
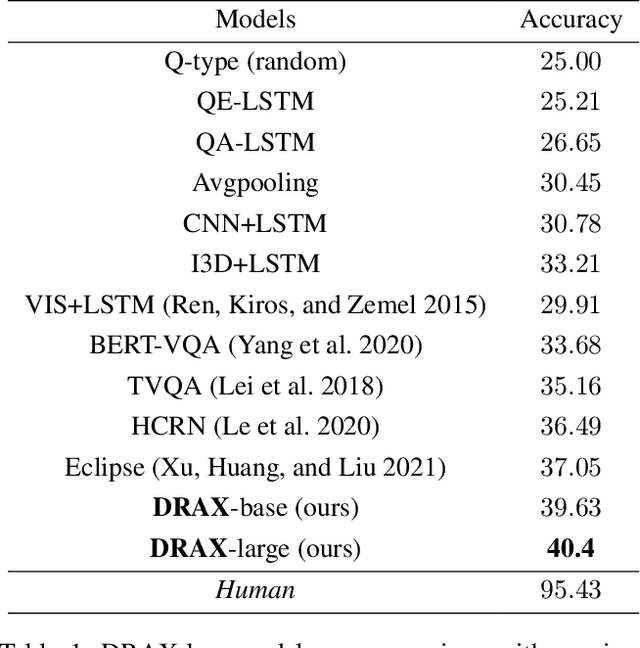
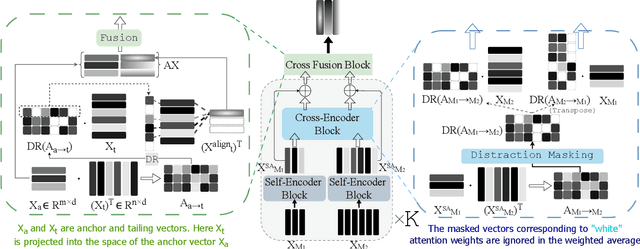
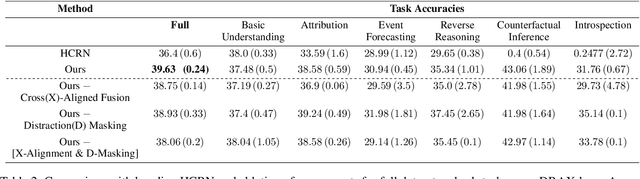
The generation of effective latent representations and their subsequent refinement to incorporate precise information is an essential prerequisite for Vision-Language Understanding (VLU) tasks such as Video Question Answering (VQA). However, most existing methods for VLU focus on sparsely sampling or fine-graining the input information (e.g., sampling a sparse set of frames or text tokens), or adding external knowledge. We present a novel "DRAX: Distraction Removal and Attended Cross-Alignment" method to rid our cross-modal representations of distractors in the latent space. We do not exclusively confine the perception of any input information from various modalities but instead use an attention-guided distraction removal method to increase focus on task-relevant information in latent embeddings. DRAX also ensures semantic alignment of embeddings during cross-modal fusions. We evaluate our approach on a challenging benchmark (SUTD-TrafficQA dataset), testing the framework's abilities for feature and event queries, temporal relation understanding, forecasting, hypothesis, and causal analysis through extensive experiments.
Exploiting Generalization in Offline Reinforcement Learning via Unseen State Augmentations
Aug 07, 2023



Offline reinforcement learning (RL) methods strike a balance between exploration and exploitation by conservative value estimation -- penalizing values of unseen states and actions. Model-free methods penalize values at all unseen actions, while model-based methods are able to further exploit unseen states via model rollouts. However, such methods are handicapped in their ability to find unseen states far away from the available offline data due to two factors -- (a) very short rollout horizons in models due to cascading model errors, and (b) model rollouts originating solely from states observed in offline data. We relax the second assumption and present a novel unseen state augmentation strategy to allow exploitation of unseen states where the learned model and value estimates generalize. Our strategy finds unseen states by value-informed perturbations of seen states followed by filtering out states with epistemic uncertainty estimates too high (high error) or too low (too similar to seen data). We observe improved performance in several offline RL tasks and find that our augmentation strategy consistently leads to overall lower average dataset Q-value estimates i.e. more conservative Q-value estimates than a baseline.