 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Your Tokens: Word-Pooled Tokenization for Language Modeling
Oct 17, 2023
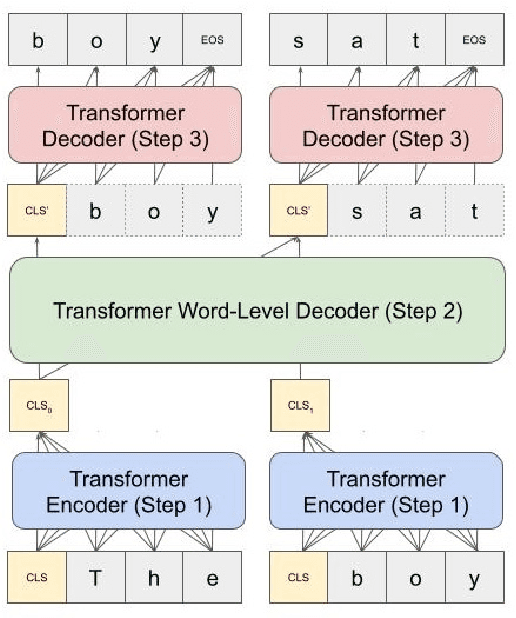
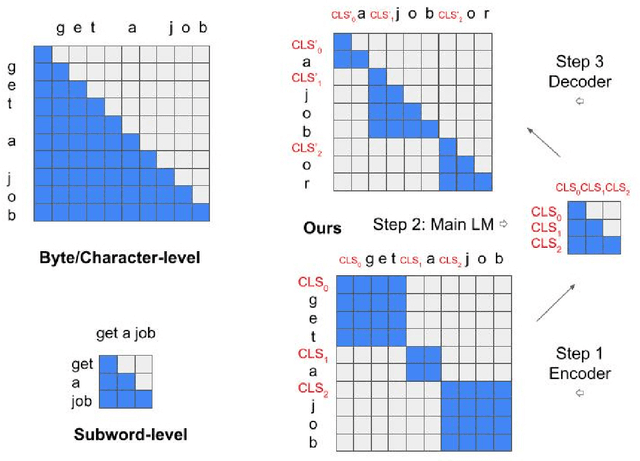
Language models typically tokenize text into subwords, using a deterministic, hand-engineered heuristic of combining characters into longer surface-level strings such as 'ing' or whole words. Recent literature has repeatedly shown the limitations of such a tokenization strategy, particularly for documents not written in English and for representing numbers. On the other extreme, byte/character-level language models are much less restricted but suffer from increased sequence description lengths and a subsequent quadratic expansion in self-attention computation. Recent attempts to compress and limit these context lengths with fixed size convolutions is helpful but completely ignores the word boundary. This paper considers an alternative 'learn your tokens' scheme which utilizes the word boundary to pool bytes/characters into word representations, which are fed to the primary language model, before again decoding individual characters/bytes per word in parallel. We find that our moderately expressive and moderately fast end-to-end tokenizer outperform by over 300% both subwords and byte/character models over the intrinsic language modeling metric of next-word prediction across datasets. It particularly outshines on rare words, outperforming by a factor of 30! We extensively study the language modeling setup for all three categories of tokenizers and theoretically analyze how our end-to-end models can also be a strong trade-off in efficiency and robustness.
Estimating Numbers without Regression
Oct 09, 2023
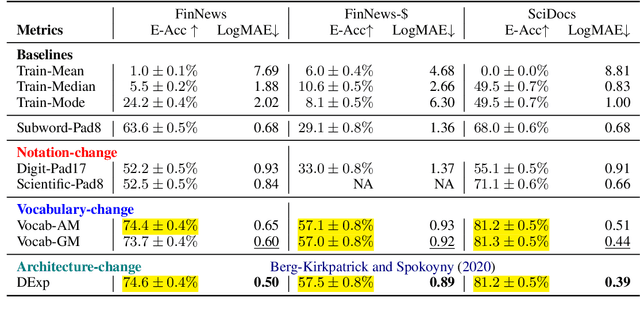
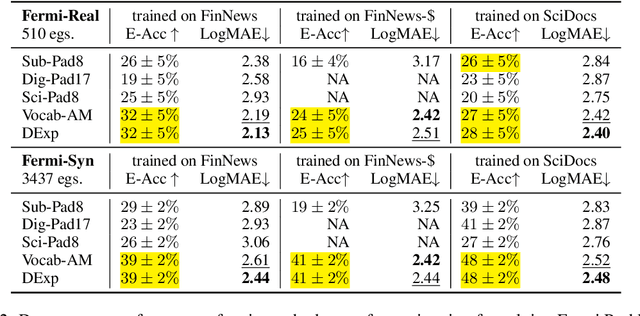
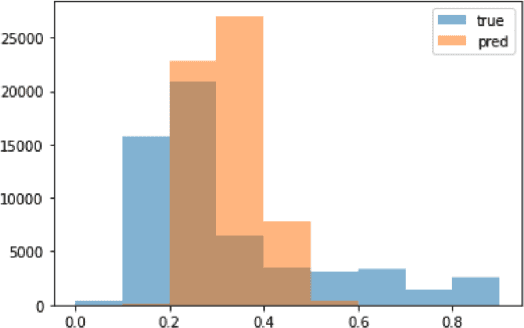
Despite recent successes in language models, their ability to represent numbers is insufficient. Humans conceptualize numbers based on their magnitudes, effectively projecting them on a number line; whereas subword tokenization fails to explicitly capture magnitude by splitting numbers into arbitrary chunks. To alleviate this shortcoming, alternative approaches have been proposed that modify numbers at various stages of the language modeling pipeline. These methods change either the (1) notation in which numbers are written (\eg scientific vs decimal), the (2) vocabulary used to represent numbers or the entire (3) architecture of the underlying language model, to directly regress to a desired number. Previous work suggests that architectural change helps achieve state-of-the-art on number estimation but we find an insightful ablation: changing the model's vocabulary instead (\eg introduce a new token for numbers in range 10-100) is a far better trade-off. In the context of masked number prediction, a carefully designed tokenization scheme is both the simplest to implement and sufficient, \ie with similar performance to the state-of-the-art approach that requires making significant architectural changes. Finally, we report similar trends on the downstream task of numerical fact estimation (for Fermi Problems) and discuss reasons behind our findings.
Representing Numbers in NLP: a Survey and a Vision
Mar 24, 2021
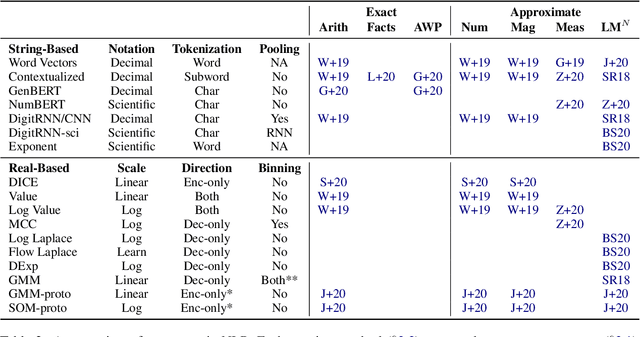
NLP systems rarely give special consideration to numbers found in text. This starkly contrasts with the consensus in neuroscience that, in the brain, numbers are represented differently from words. We arrange recent NLP work on numeracy into a comprehensive taxonomy of tasks and methods. We break down the subjective notion of numeracy into 7 subtasks, arranged along two dimensions: granularity (exact vs approximate) and units (abstract vs grounded). We analyze the myriad representational choices made by 18 previously published number encoders and decoders. We synthesize best practices for representing numbers in text and articulate a vision for holistic numeracy in NLP, comprised of design trade-offs and a unified evaluation.