 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025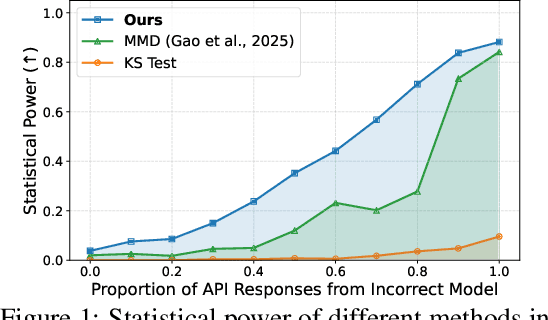

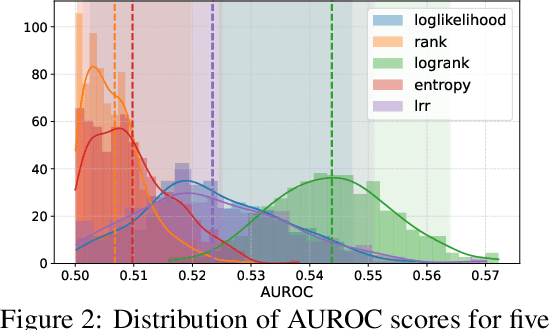
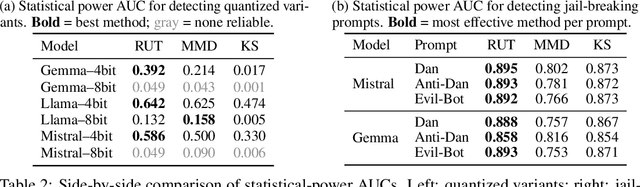
As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
How Can Large Language Models Enable Better Socially Assistive Human-Robot Interaction: A Brief Survey
Apr 05, 2024Socially assistive robots (SARs) have shown great success in providing personalized cognitive-affective support for user populations with special needs such as older adults, children with autism spectrum disorder (ASD), and individuals with mental health challenges. The large body of work on SAR demonstrates its potential to provide at-home support that complements clinic-based interventions delivered by mental health professionals, making these interventions more effective and accessible. However, there are still several major technical challenges that hinder SAR-mediated interactions and interventions from reaching human-level social intelligence and efficacy. With the recent advances in large language models (LLMs), there is an increased potential for novel applications within the field of SAR that can significantly expand the current capabilities of SARs. However, incorporating LLMs introduces new risks and ethical concerns that have not yet been encountered, and must be carefully be addressed to safely deploy these more advanced systems. In this work, we aim to conduct a brief survey on the use of LLMs in SAR technologies, and discuss the potentials and risks of applying LLMs to the following three major technical challenges of SAR: 1) natural language dialog; 2) multimodal understanding; 3) LLMs as robot policies.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Learn Your Tokens: Word-Pooled Tokenization for Language Modeling
Oct 17, 2023
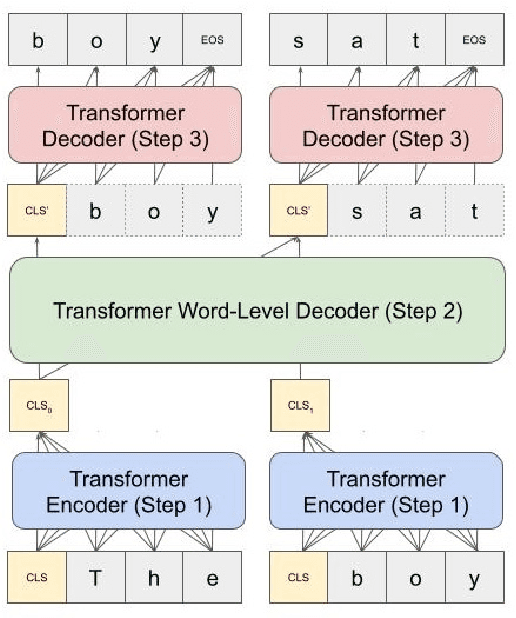
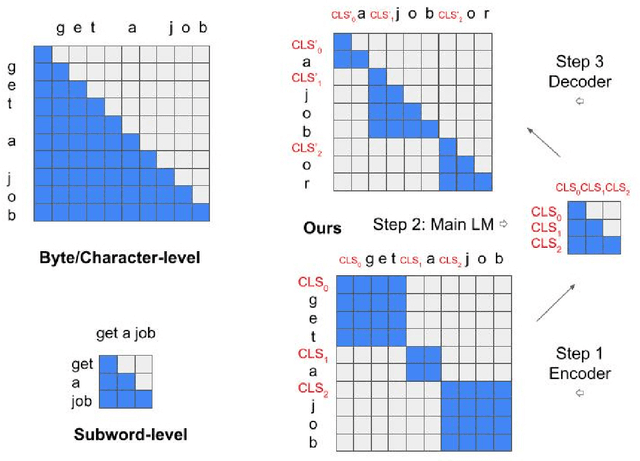
Language models typically tokenize text into subwords, using a deterministic, hand-engineered heuristic of combining characters into longer surface-level strings such as 'ing' or whole words. Recent literature has repeatedly shown the limitations of such a tokenization strategy, particularly for documents not written in English and for representing numbers. On the other extreme, byte/character-level language models are much less restricted but suffer from increased sequence description lengths and a subsequent quadratic expansion in self-attention computation. Recent attempts to compress and limit these context lengths with fixed size convolutions is helpful but completely ignores the word boundary. This paper considers an alternative 'learn your tokens' scheme which utilizes the word boundary to pool bytes/characters into word representations, which are fed to the primary language model, before again decoding individual characters/bytes per word in parallel. We find that our moderately expressive and moderately fast end-to-end tokenizer outperform by over 300% both subwords and byte/character models over the intrinsic language modeling metric of next-word prediction across datasets. It particularly outshines on rare words, outperforming by a factor of 30! We extensively study the language modeling setup for all three categories of tokenizers and theoretically analyze how our end-to-end models can also be a strong trade-off in efficiency and robustness.
Multimodal Speech Recognition for Language-Guided Embodied Agents
Feb 27, 2023Benchmarks for language-guided embodied agents typically assume text-based instructions, but deployed agents will encounter spoken instructions. While Automatic Speech Recognition (ASR) models can bridge the input gap, erroneous ASR transcripts can hurt the agents' ability to complete tasks. In this work, we propose training a multimodal ASR model to reduce errors in transcribing spoken instructions by considering the accompanying visual context. We train our model on a dataset of spoken instructions, synthesized from the ALFRED task completion dataset, where we simulate acoustic noise by systematically masking spoken words. We find that utilizing visual observations facilitates masked word recovery, with multimodal ASR models recovering up to 30% more masked words than unimodal baselines. We also find that a text-trained embodied agent successfully completes tasks more often by following transcribed instructions from multimodal ASR models.