 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Large Language Models Enable Better Socially Assistive Human-Robot Interaction: A Brief Survey
Apr 05, 2024Socially assistive robots (SARs) have shown great success in providing personalized cognitive-affective support for user populations with special needs such as older adults, children with autism spectrum disorder (ASD), and individuals with mental health challenges. The large body of work on SAR demonstrates its potential to provide at-home support that complements clinic-based interventions delivered by mental health professionals, making these interventions more effective and accessible. However, there are still several major technical challenges that hinder SAR-mediated interactions and interventions from reaching human-level social intelligence and efficacy. With the recent advances in large language models (LLMs), there is an increased potential for novel applications within the field of SAR that can significantly expand the current capabilities of SARs. However, incorporating LLMs introduces new risks and ethical concerns that have not yet been encountered, and must be carefully be addressed to safely deploy these more advanced systems. In this work, we aim to conduct a brief survey on the use of LLMs in SAR technologies, and discuss the potentials and risks of applying LLMs to the following three major technical challenges of SAR: 1) natural language dialog; 2) multimodal understanding; 3) LLMs as robot policies.
Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Dec 02, 2020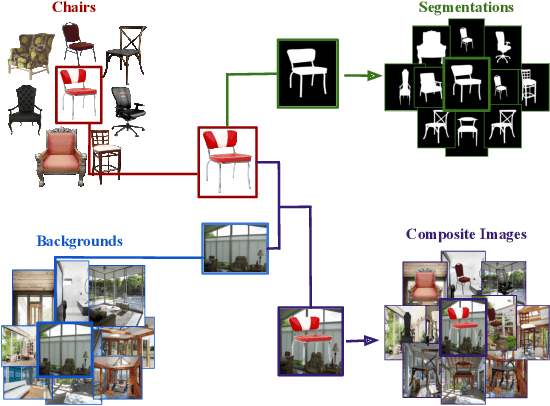
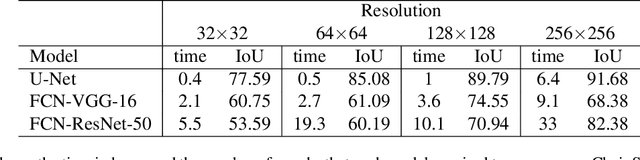

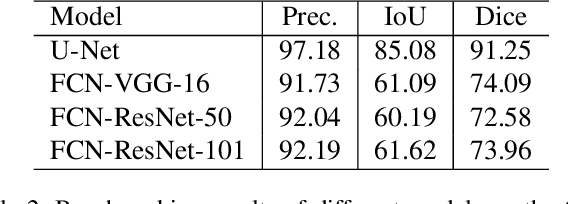
Over the years, datasets and benchmarks have had an outsized influence on the design of novel algorithms. In this paper, we introduce ChairSegments, a novel and compact semi-synthetic dataset for object segmentation. We also show empirical findings in transfer learning that mirror recent findings for image classification. We particularly show that models that are fine-tuned from a pretrained set of weights lie in the same basin of the optimization landscape. ChairSegments consists of a diverse set of prototypical images of chairs with transparent backgrounds composited into a diverse array of backgrounds. We aim for ChairSegments to be the equivalent of the CIFAR-10 dataset but for quickly designing and iterating over novel model architectures for segmentation. On Chair Segments, a U-Net model can be trained to full convergence in only thirty minutes using a single GPU. Finally, while this dataset is semi-synthetic, it can be a useful proxy for real data, leading to state-of-the-art accuracy on the Object Discovery dataset when used as a source of pretraining.