 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedReadCtrl: Personalizing medical text generation with readability-controlled instruction learning
Jul 10, 2025Generative AI has demonstrated strong potential in healthcare, from clinical decision support to patient-facing chatbots that improve outcomes. A critical challenge for deployment is effective human-AI communication, where content must be both personalized and understandable. We introduce MedReadCtrl, a readability-controlled instruction tuning framework that enables LLMs to adjust output complexity without compromising meaning. Evaluations of nine datasets and three tasks across medical and general domains show that MedReadCtrl achieves significantly lower readability instruction-following errors than GPT-4 (e.g., 1.39 vs. 1.59 on ReadMe, p<0.001) and delivers substantial gains on unseen clinical tasks (e.g., +14.7 ROUGE-L, +6.18 SARI on MTSamples). Experts consistently preferred MedReadCtrl (71.7% vs. 23.3%), especially at low literacy levels. These gains reflect MedReadCtrl's ability to restructure clinical content into accessible, readability-aligned language while preserving medical intent, offering a scalable solution to support patient education and expand equitable access to AI-enabled care.
Quality-Diversity Generative Sampling for Learning with Synthetic Data
Dec 22, 2023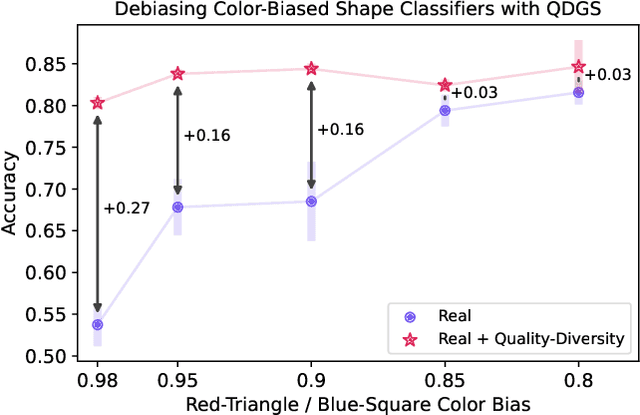
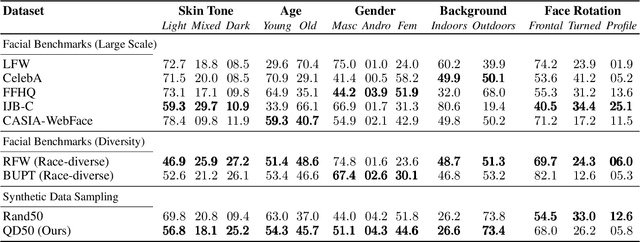


Generative models can serve as surrogates for some real data sources by creating synthetic training datasets, but in doing so they may transfer biases to downstream tasks. We focus on protecting quality and diversity when generating synthetic training datasets. We propose quality-diversity generative sampling (QDGS), a framework for sampling data uniformly across a user-defined measure space, despite the data coming from a biased generator. QDGS is a model-agnostic framework that uses prompt guidance to optimize a quality objective across measures of diversity for synthetically generated data, without fine-tuning the generative model. Using balanced synthetic datasets generated by QDGS, we first debias classifiers trained on color-biased shape datasets as a proof-of-concept. By applying QDGS to facial data synthesis, we prompt for desired semantic concepts, such as skin tone and age, to create an intersectional dataset with a combined blend of visual features. Leveraging this balanced data for training classifiers improves fairness while maintaining accuracy on facial recognition benchmarks. Code available at: https://github.com/Cylumn/qd-generative-sampling
Multimodal Speech Recognition for Language-Guided Embodied Agents
Feb 27, 2023Benchmarks for language-guided embodied agents typically assume text-based instructions, but deployed agents will encounter spoken instructions. While Automatic Speech Recognition (ASR) models can bridge the input gap, erroneous ASR transcripts can hurt the agents' ability to complete tasks. In this work, we propose training a multimodal ASR model to reduce errors in transcribing spoken instructions by considering the accompanying visual context. We train our model on a dataset of spoken instructions, synthesized from the ALFRED task completion dataset, where we simulate acoustic noise by systematically masking spoken words. We find that utilizing visual observations facilitates masked word recovery, with multimodal ASR models recovering up to 30% more masked words than unimodal baselines. We also find that a text-trained embodied agent successfully completes tasks more often by following transcribed instructions from multimodal ASR models.
Removing Radio Frequency Interference from Auroral Kilometric Radiation with Stacked Autoencoders
Oct 25, 2022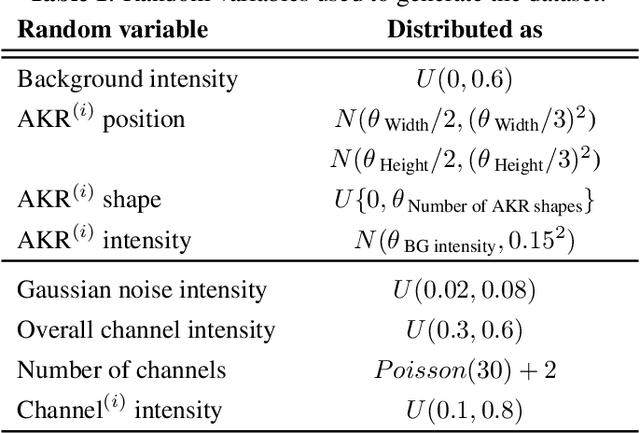



Radio frequency data in astronomy enable scientists to analyze astrophysical phenomena. However, these data can be corrupted by a host of radio frequency interference (RFI) sources that limit the ability to observe underlying natural processes. In this study, we extended recent work in image processing to remove RFI from time-frequency spectrograms containing auroral kilometric radiation (AKR), a coherent radio emission originating from the Earth's auroral zones that is used to study astrophysical plasmas. We present a Denoising Autoencoder for Auroral Radio Emissions (DAARE) trained with synthetic spectrograms to denoise AKR spectrograms collected at the South Pole Station. DAARE achieved 42.2 peak-signal-to-noise ratio (PSNR) and 0.981 structural similarity (SSIM) on synthesized AKR observations, improving PSNR by 3.9 and SSIM by 0.064 compared to state-of-the-art filtering and denoising networks. Qualitative comparisons demonstrate DAARE's denoising capability to effectively remove RFI from real AKR observations, despite being trained completely on a dataset of simulated AKR. The framework for simulating AKR, training DAARE, and employing DAARE can be accessed at https://github.com/Cylumn/daare.
Evaluating Temporal Patterns in Applied Infant Affect Recognition
Sep 07, 2022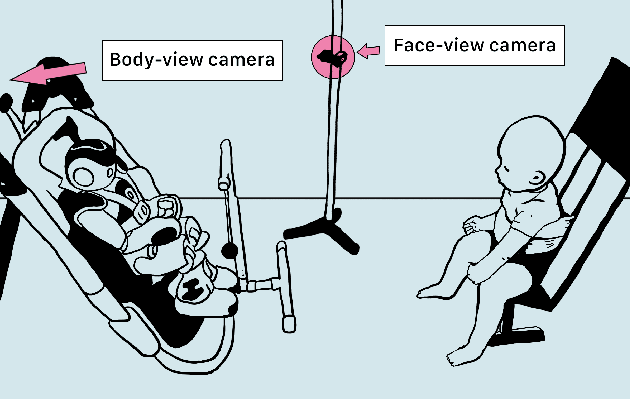
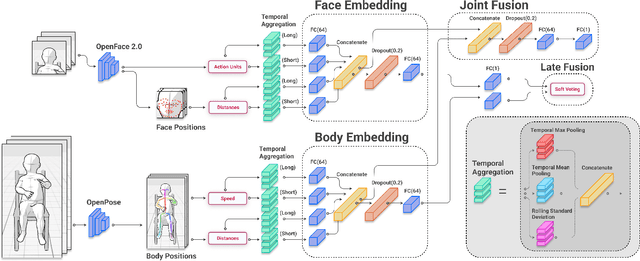

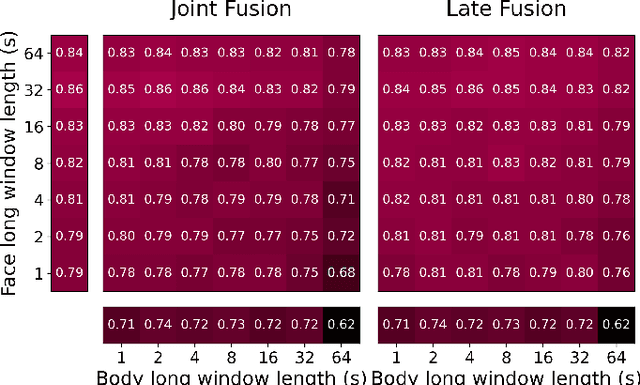
Agents must monitor their partners' affective states continuously in order to understand and engage in social interactions. However, methods for evaluating affect recognition do not account for changes in classification performance that may occur during occlusions or transitions between affective states. This paper addresses temporal patterns in affect classification performance in the context of an infant-robot interaction, where infants' affective states contribute to their ability to participate in a therapeutic leg movement activity. To support robustness to facial occlusions in video recordings, we trained infant affect recognition classifiers using both facial and body features. Next, we conducted an in-depth analysis of our best-performing models to evaluate how performance changed over time as the models encountered missing data and changing infant affect. During time windows when features were extracted with high confidence, a unimodal model trained on facial features achieved the same optimal performance as multimodal models trained on both facial and body features. However, multimodal models outperformed unimodal models when evaluated on the entire dataset. Additionally, model performance was weakest when predicting an affective state transition and improved after multiple predictions of the same affective state. These findings emphasize the benefits of incorporating body features in continuous affect recognition for infants. Our work highlights the importance of evaluating variability in model performance both over time and in the presence of missing data when applying affect recognition to social interactions.
Learning Partially Observable Deterministic Action Models
Jan 15, 2014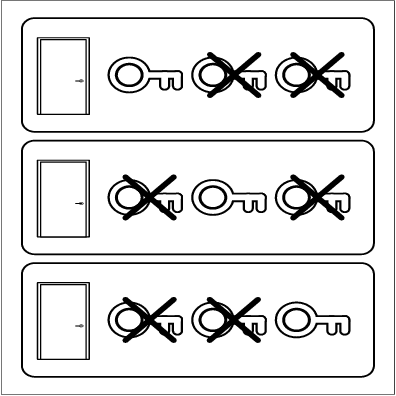
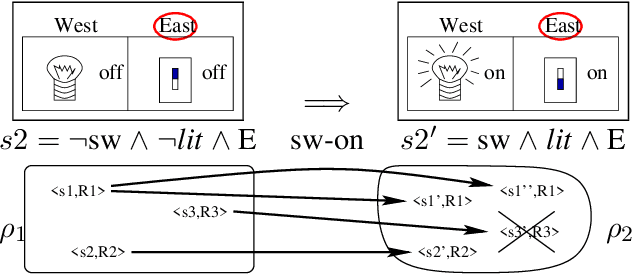


We present exact algorithms for identifying deterministic-actions effects and preconditions in dynamic partially observable domains. They apply when one does not know the action model(the way actions affect the world) of a domain and must learn it from partial observations over time. Such scenarios are common in real world applications. They are challenging for AI tasks because traditional domain structures that underly tractability (e.g., conditional independence) fail there (e.g., world features become correlated). Our work departs from traditional assumptions about partial observations and action models. In particular, it focuses on problems in which actions are deterministic of simple logical structure and observation models have all features observed with some frequency. We yield tractable algorithms for the modified problem for such domains. Our algorithms take sequences of partial observations over time as input, and output deterministic action models that could have lead to those observations. The algorithms output all or one of those models (depending on our choice), and are exact in that no model is misclassified given the observations. Our algorithms take polynomial time in the number of time steps and state features for some traditional action classes examined in the AI-planning literature, e.g., STRIPS actions. In contrast, traditional approaches for HMMs and Reinforcement Learning are inexact and exponentially intractable for such domains. Our experiments verify the theoretical tractability guarantees, and show that we identify action models exactly. Several applications in planning, autonomous exploration, and adventure-game playing already use these results. They are also promising for probabilistic settings, partially observable reinforcement learning, and diagnosis.
Reachability Under Uncertainty
Jun 20, 2012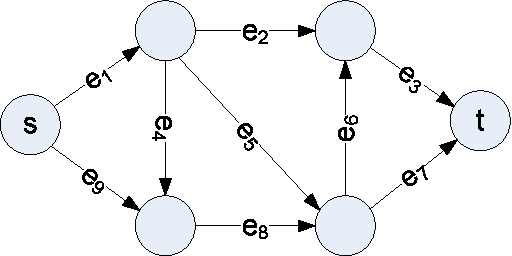
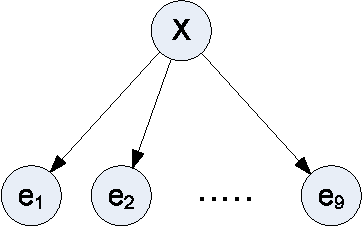
In this paper we introduce a new network reachability problem where the goal is to find the most reliable path between two nodes in a network, represented as a directed acyclic graph. Individual edges within this network may fail according to certain probabilities, and these failure probabilities may depend on the values of one or more hidden variables. This problem may be viewed as a generalization of shortest-path problems for finding minimum cost paths or Viterbi-type problems for finding highest-probability sequences of states, where the addition of the hidden variables introduces correlations that are not handled by previous algorithms. We give theoretical results characterizing this problem including an NP-hardness proof. We also give an exact algorithm and a more efficient approximation algorithm for this problem.